 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Local Causal Discovery
Dec 27, 2024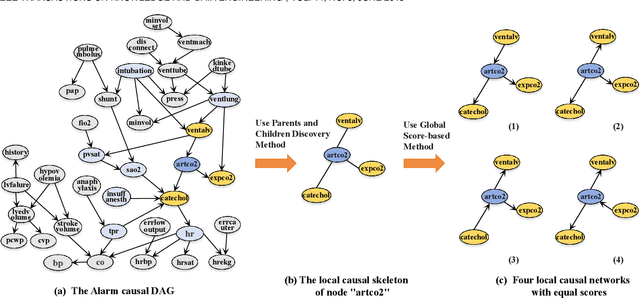
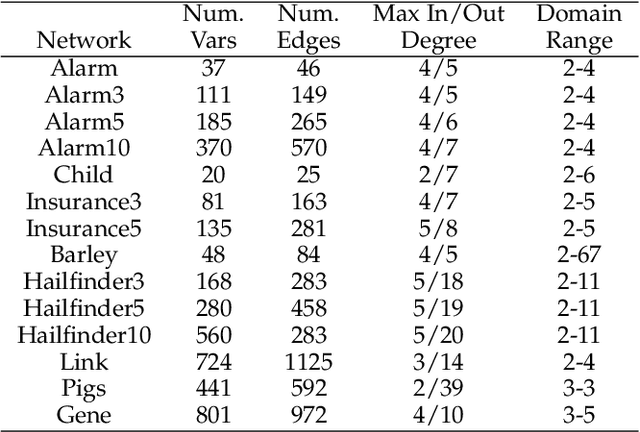
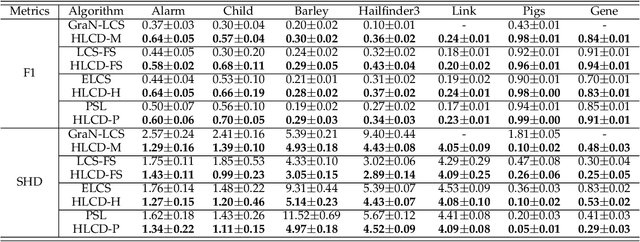
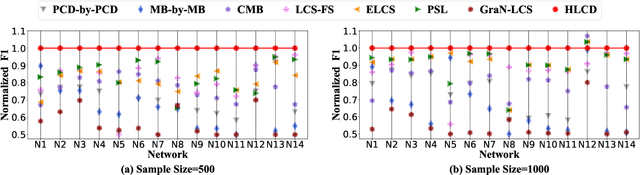
Local causal discovery aims to learn and distinguish the direct causes and effects of a target variable from observed data. Existing constraint-based local causal discovery methods use AND or OR rules in constructing the local causal skeleton, but using either rule alone is prone to produce cascading errors in the learned local causal skeleton, and thus impacting the inference of local causal relationships. On the other hand, directly applying score-based global causal discovery methods to local causal discovery may randomly return incorrect results due to the existence of local equivalence classes. To address the above issues, we propose a Hybrid Local Causal Discovery algorithm, called HLCD. Specifically, HLCD initially utilizes a constraint-based approach combined with the OR rule to obtain a candidate skeleton and then employs a score-based method to eliminate redundant portions in the candidate skeleton. Furthermore, during the local causal orientation phase, HLCD distinguishes between V-structures and equivalence classes by comparing the local structure scores between the two, thereby avoiding orientation interference caused by local equivalence classes. We conducted extensive experiments with seven state-of-the-art competitors on 14 benchmark Bayesian network datasets, and the experimental results demonstrate that HLCD significantly outperforms existing local causal discovery algorithms.
Fair Streaming Feature Selection
Jun 20, 2024



Streaming feature selection techniques have become essential in processing real-time data streams, as they facilitate the identification of the most relevant attributes from continuously updating information. Despite their performance, current algorithms to streaming feature selection frequently fall short in managing biases and avoiding discrimination that could be perpetuated by sensitive attributes, potentially leading to unfair outcomes in the resulting models. To address this issue, we propose FairSFS, a novel algorithm for Fair Streaming Feature Selection, to uphold fairness in the feature selection process without compromising the ability to handle data in an online manner. FairSFS adapts to incoming feature vectors by dynamically adjusting the feature set and discerns the correlations between classification attributes and sensitive attributes from this revised set, thereby forestalling the propagation of sensitive data. Empirical evaluations show that FairSFS not only maintains accuracy that is on par with leading streaming feature selection methods and existing fair feature techniques but also significantly improves fairness metrics.
Fair Causal Feature Selection
Jun 17, 2023



Causal feature selection has recently received increasing attention in machine learning. Existing causal feature selection algorithms select unique causal features of a class variable as the optimal feature subset. However, a class variable usually has multiple states, and it is unfair to select the same causal features for different states of a class variable. To address this problem, we employ the class-specific mutual information to evaluate the causal information carried by each state of the class attribute, and theoretically analyze the unique relationship between each state and the causal features. Based on this, a Fair Causal Feature Selection algorithm (FairCFS) is proposed to fairly identifies the causal features for each state of the class variable. Specifically, FairCFS uses the pairwise comparisons of class-specific mutual information and the size of class-specific mutual information values from the perspective of each state, and follows a divide-and-conquer framework to find causal features. The correctness and application condition of FairCFS are theoretically proved, and extensive experiments are conducted to demonstrate the efficiency and superiority of FairCFS compared to the state-of-the-art approaches.
Feature Selection for Efficient Local-to-Global Bayesian Network Structure Learning
Dec 20, 2021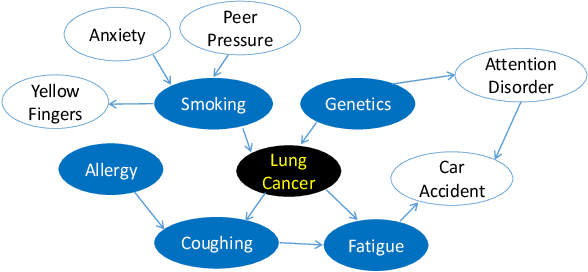
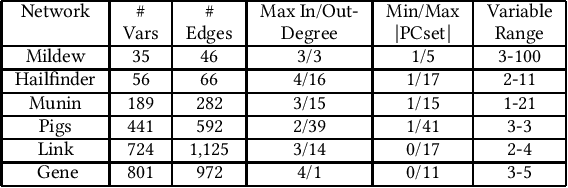
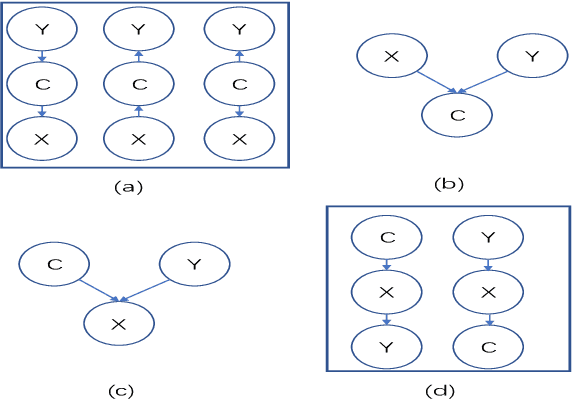
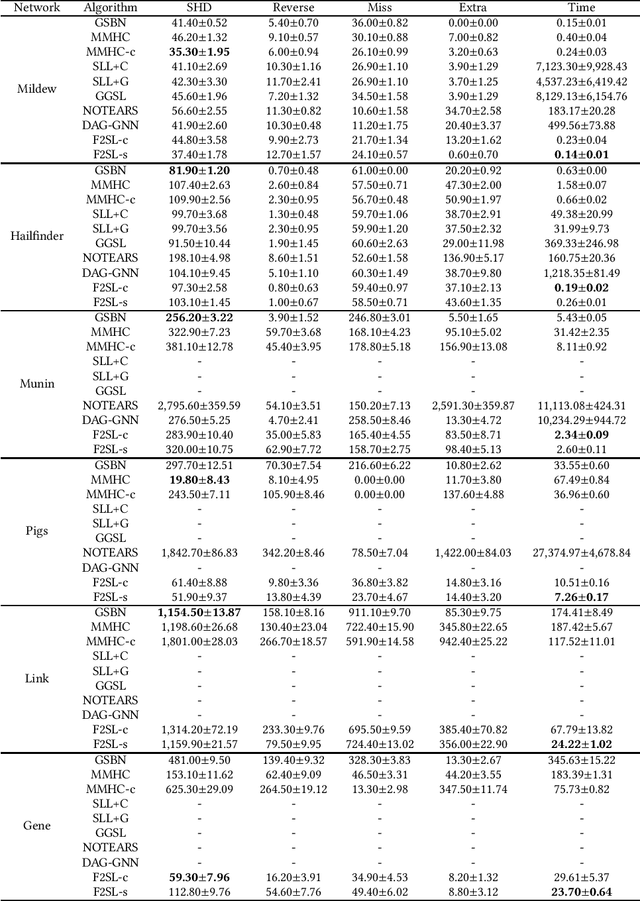
Local-to-global learning approach plays an essential role in Bayesian network (BN) structure learning. Existing local-to-global learning algorithms first construct the skeleton of a DAG (directed acyclic graph) by learning the MB (Markov blanket) or PC (parents and children) of each variable in a data set, then orient edges in the skeleton. However, existing MB or PC learning methods are often computationally expensive especially with a large-sized BN, resulting in inefficient local-to-global learning algorithms. To tackle the problem, in this paper, we develop an efficient local-to-global learning approach using feature selection. Specifically, we first analyze the rationale of the well-known Minimum-Redundancy and Maximum-Relevance (MRMR) feature selection approach for learning a PC set of a variable. Based on the analysis, we propose an efficient F2SL (feature selection-based structure learning) approach to local-to-global BN structure learning. The F2SL approach first employs the MRMR approach to learn a DAG skeleton, then orients edges in the skeleton. Employing independence tests or score functions for orienting edges, we instantiate the F2SL approach into two new algorithms, F2SL-c (using independence tests) and F2SL-s (using score functions). Compared to the state-of-the-art local-to-global BN learning algorithms, the experiments validated that the proposed algorithms in this paper are more efficient and provide competitive structure learning quality than the compared algorithms.
Any Part of Bayesian Network Structure Learning
Mar 23, 2021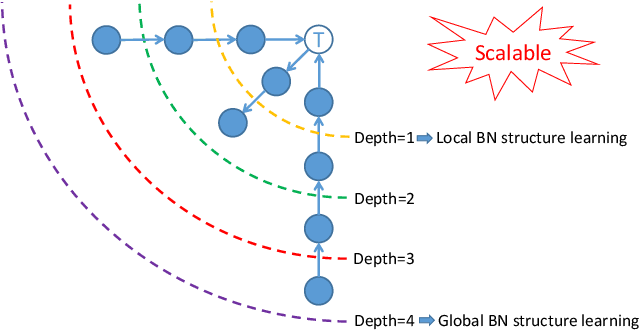

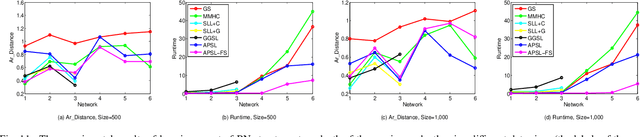
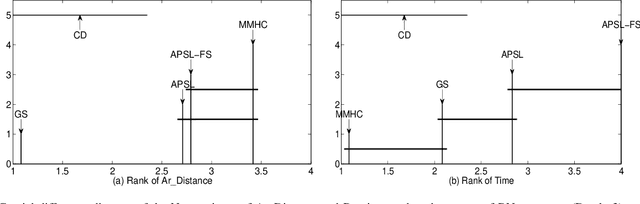
We study an interesting and challenging problem, learning any part of a Bayesian network (BN) structure. In this challenge, it will be computationally inefficient using existing global BN structure learning algorithms to find an entire BN structure to achieve the part of a BN structure in which we are interested. And local BN structure learning algorithms encounter the false edge orientation problem when they are directly used to tackle this challenging problem. In this paper, we first present a new concept of Expand-Backtracking to explain why local BN structure learning methods have the false edge orientation problem, then propose APSL, an efficient and accurate Any Part of BN Structure Learning algorithm. Specifically, APSL divides the V-structures in a Markov blanket (MB) into two types: collider V-structure and non-collider V-structure, then it starts from a node of interest and recursively finds both collider V-structures and non-collider V-structures in the found MBs, until the part of a BN structure in which we are interested are oriented. To improve the efficiency of APSL, we further design the APSL-FS algorithm using Feature Selection, APSL-FS. Using six benchmark BNs, the extensive experiments have validated the efficiency and accuracy of our methods.
Causal Learner: A Toolbox for Causal Structure and Markov Blanket Learning
Mar 11, 2021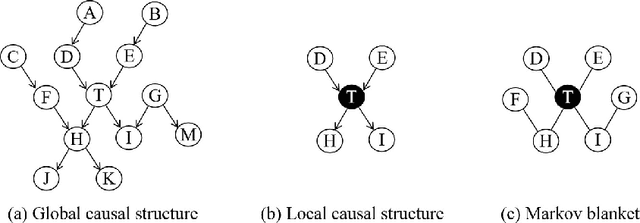
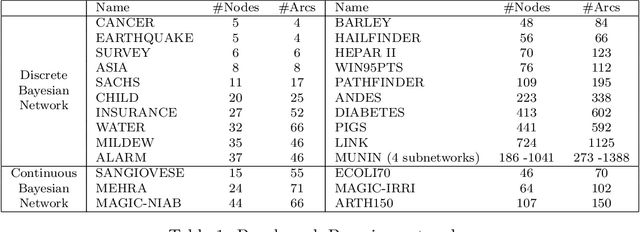
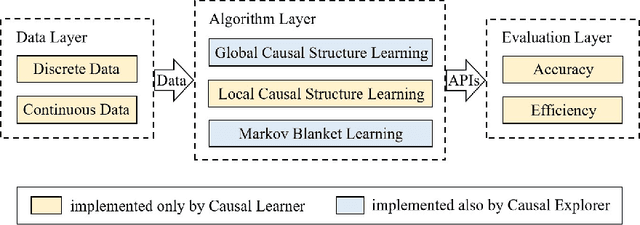
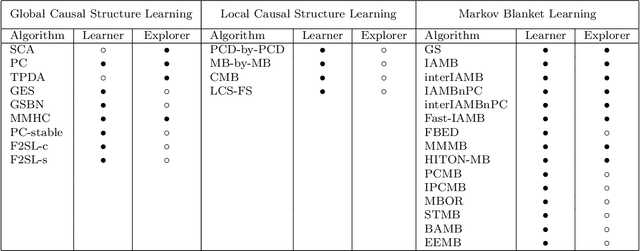
Causal Learner is a toolbox for learning causal structure and Markov blanket (MB) from data. It integrates functions for generating simulated Bayesian network data, a set of state-of-the-art global causal structure learning algorithms, a set of state-of-the-art local causal structure learning algorithms, a set of state-of-the-art MB learning algorithms, and functions for evaluating algorithms. The data generation part of Causal Learner is written in R, and the rest of Causal Learner is written in MATLAB. Causal Learner aims to provide researchers and practitioners with an open-source platform for causal learning from data and for the development and evaluation of new causal learning algorithms. The Causal Learner project is available at http://bigdata.ahu.edu.cn/causal-learner.
Causality-based Feature Selection: Methods and Evaluations
Nov 17, 2019
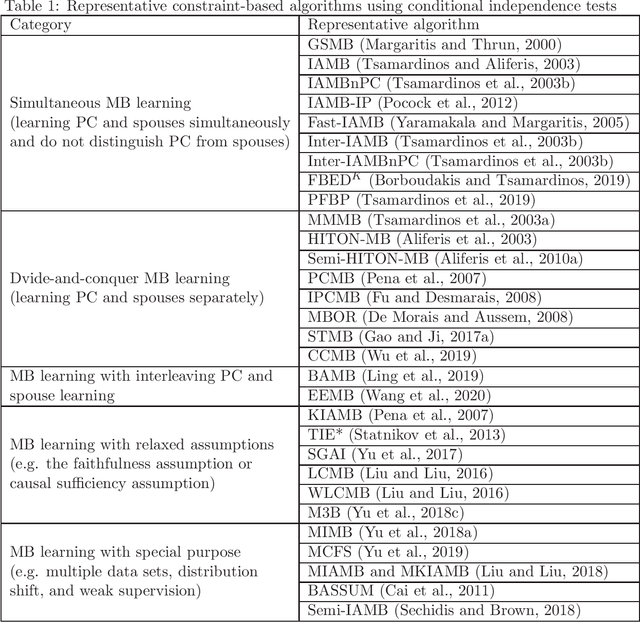

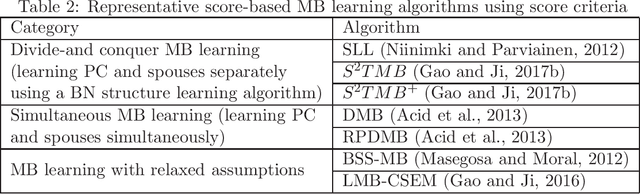
Feature selection is a crucial preprocessing step in data analytics and machine learning. Classical feature selection algorithms select features based on the correlations between predictive features and the class variable and do not attempt to capture causal relationships between them. It has been shown that the knowledge about the causal relationships between features and the class variable has potential benefits for building interpretable and robust prediction models, since causal relationships imply the underlying mechanism of a system. Consequently, causality-based feature selection has gradually attracted greater attentions and many algorithms have been proposed. In this paper, we present a comprehensive review of recent advances in causality-based feature selection. To facilitate the development of new algorithms in the research area and make it easy for the comparisons between new methods and existing ones, we develop the first open-source package, called CausalFS, which consists of most of the representative causality-based feature selection algorithms (available at https://github.com/kuiy/CausalFS). Using CausalFS, we conduct extensive experiments to compare the representative algorithms with both synthetic and real-world data sets. Finally, we discuss some challenging problems to be tackled in future causality-based feature selection research.