 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Dual On-Policy Distillation from Expressive Flow-based Teacher
May 26, 2026Learning from demonstrations in embodied control is often cast as behavioral cloning, and recent diffusion or flow-matching policies improve this paradigm by modeling multi-modal expert actions. Yet these methods remain offline supervised learners: the policy is trained only on expert states and receives no corrective signal on the states it actually visits. On-policy distillation (OPD) offers a natural remedy, but standard OPD assumes a strong fixed teacher, which is unavailable in demonstration-only control. We propose \textbf{FA-OPD}, an \emph{adversarial dual on-policy distillation} method in which a Flow Matching (FM) teacher is learned from demonstrations and co-trained with a lightweight MLP student. The teacher provides two complementary signals on student rollouts. The reward channel learns an expert-likeness objective over state-action pairs and drives online exploration through long-horizon policy optimization. The action channel supplies dense local targets at student-visited states, stabilizing exploitation. FA-OPD couples them so that reward distillation enables generalization beyond point-wise demonstrations, while action distillation keeps exploration anchored near expert-like behavior. Across six robot navigation, manipulation, and locomotion benchmarks, FA-OPD beats strong baselines and shows much stronger robustness under noisy or limited demonstrations.
Time-Annealed Perturbation Sampling: Diverse Generation for Diffusion Language Models
Jan 30, 2026Diffusion language models (Diffusion-LMs) introduce an explicit temporal dimension into text generation, yet how this structure can be leveraged to control generation diversity for exploring multiple valid semantic or reasoning paths remains underexplored. In this paper, we show that Diffusion-LMs, like diffusion models in image generation, exhibit a temporal division of labor: early denoising steps largely determine the global semantic structure, while later steps focus on local lexical refinement. Building on this insight, we propose Time-Annealed Perturbation Sampling (TAPS), a training-free inference strategy that encourages semantic branching early in the diffusion process while progressively reducing perturbations to preserve fluency and instruction adherence. TAPS is compatible with both non-autoregressive and semi-autoregressive Diffusion backbones, demonstrated on LLaDA and TraDo in our paper, and consistently improves output diversity across creative writing and reasoning benchmarks without compromising generation quality.
CaveAgent: Transforming LLMs into Stateful Runtime Operators
Jan 04, 2026LLM-based agents are increasingly capable of complex task execution, yet current agentic systems remain constrained by text-centric paradigms. Traditional approaches rely on procedural JSON-based function calling, which often struggles with long-horizon tasks due to fragile multi-turn dependencies and context drift. In this paper, we present CaveAgent, a framework that transforms the paradigm from "LLM-as-Text-Generator" to "LLM-as-Runtime-Operator." We introduce a Dual-stream Context Architecture that decouples state management into a lightweight semantic stream for reasoning and a persistent, deterministic Python Runtime stream for execution. In addition to leveraging code generation to efficiently resolve interdependent sub-tasks (e.g., loops, conditionals) in a single step, we introduce \textit{Stateful Runtime Management} in CaveAgent. Distinct from existing code-based approaches that remain text-bound and lack the support for external object injection and retrieval, CaveAgent injects, manipulates, and retrieves complex Python objects (e.g., DataFrames, database connections) that persist across turns. This persistence mechanism acts as a high-fidelity external memory to eliminate context drift, avoid catastrophic forgetting, while ensuring that processed data flows losslessly to downstream applications. Comprehensive evaluations on Tau$^2$-bench, BFCL and various case studies across representative SOTA LLMs demonstrate CaveAgent's superiority. Specifically, our framework achieves a 10.5\% success rate improvement on retail tasks and reduces total token consumption by 28.4\% in multi-turn scenarios. On data-intensive tasks, direct variable storage and retrieval reduces token consumption by 59\%, allowing CaveAgent to handle large-scale data that causes context overflow failures in both JSON-based and Code-based agents.
CNIMA: A Universal Evaluation Framework and Automated Approach for Assessing Second Language Dialogues
Aug 29, 2024We develop CNIMA (Chinese Non-Native Interactivity Measurement and Automation), a Chinese-as-a-second-language labelled dataset with 10K dialogues. We annotate CNIMA using an evaluation framework -- originally introduced for English-as-a-second-language dialogues -- that assesses micro-level features (e.g.\ backchannels) and macro-level interactivity labels (e.g.\ topic management) and test the framework's transferability from English to Chinese. We found the framework robust across languages and revealed universal and language-specific relationships between micro-level and macro-level features. Next, we propose an approach to automate the evaluation and find strong performance, creating a new tool for automated second language assessment. Our system can be adapted to other languages easily as it uses large language models and as such does not require large-scale annotated training data.
Fair Causal Feature Selection
Jun 17, 2023



Causal feature selection has recently received increasing attention in machine learning. Existing causal feature selection algorithms select unique causal features of a class variable as the optimal feature subset. However, a class variable usually has multiple states, and it is unfair to select the same causal features for different states of a class variable. To address this problem, we employ the class-specific mutual information to evaluate the causal information carried by each state of the class attribute, and theoretically analyze the unique relationship between each state and the causal features. Based on this, a Fair Causal Feature Selection algorithm (FairCFS) is proposed to fairly identifies the causal features for each state of the class variable. Specifically, FairCFS uses the pairwise comparisons of class-specific mutual information and the size of class-specific mutual information values from the perspective of each state, and follows a divide-and-conquer framework to find causal features. The correctness and application condition of FairCFS are theoretically proved, and extensive experiments are conducted to demonstrate the efficiency and superiority of FairCFS compared to the state-of-the-art approaches.
MDS-Net: A Multi-scale Depth Stratification Based Monocular 3D Object Detection Algorithm
Jan 12, 2022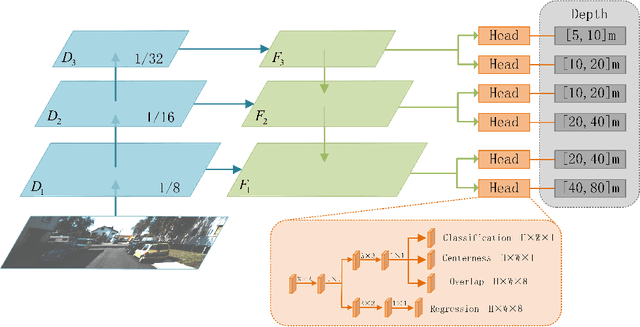
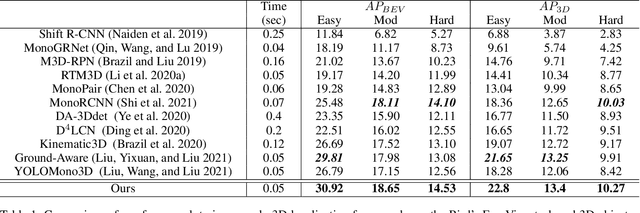


Monocular 3D object detection is very challenging in autonomous driving due to the lack of depth information. This paper proposes a one-stage monocular 3D object detection algorithm based on multi-scale depth stratification, which uses the anchor-free method to detect 3D objects in a per-pixel prediction. In the proposed MDS-Net, a novel depth-based stratification structure is developed to improve the network's ability of depth prediction by establishing mathematical models between depth and image size of objects. A new angle loss function is then developed to further improve the accuracy of the angle prediction and increase the convergence speed of training. An optimized soft-NMS is finally applied in the post-processing stage to adjust the confidence of candidate boxes. Experiments on the KITTI benchmark show that the MDS-Net outperforms the existing monocular 3D detection methods in 3D detection and BEV detection tasks while fulfilling real-time requirements.