 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAURec: Dual-Intent Space Representation Optimization for Recommendation
Apr 13, 2026General recommender systems deliver personalized services by learning user and item representations, with the central challenge being how to capture latent user preferences. However, representations derived from sparse interactions often fail to comprehensively characterize user behaviors, thereby limiting recommendation effectiveness. Recent studies attempt to enhance user representations through sophisticated modeling strategies ($e.g.,$ intent or language modeling). Nevertheless, most works primarily concentrate on model interpretability instead of representation optimization. This imbalance has led to limited progress, as representation optimization is crucial for recommendation quality by promoting the affinity between users and their interacted items in the feature space, yet remains largely overlooked. To overcome these limitations, we propose DIAURec, a novel representation learning framework that unifies intent and language modeling for recommendation. DIAURec reconstructs representations based on the prototype and distribution intent spaces formed by collaborative and language signals. Furthermore, we design a comprehensive representation optimization strategy. Specifically, we adopts alignment and uniformity as the primary optimization objectives, and incorporates both coarse- and fine-grained matching to achieve effective alignment across different spaces, thereby enhancing representational consistency. Additionally, we further introduce intra-space and interaction regularization to enhance model robustness and prevent representation collapse in reconstructed space representation. Experiments on three public datasets against fifteen baseline methods show that DIAURec consistently outperforms state-of-the-art baselines, fully validating its effectiveness and superiority.
Polynomial Expansion Rank Adaptation: Enhancing Low-Rank Fine-Tuning with High-Order Interactions
Apr 12, 2026Low-rank adaptation (LoRA) is a widely used strategy for efficient fine-tuning of large language models (LLMs), but its strictly linear structure fundamentally limits expressive capacity. The bilinear formulation of weight updates captures only first-order dependencies between low-rank factors, restricting the modeling of nonlinear and higher-order parameter interactions. In this paper, we propose Polynomial Expansion Rank Adaptation (PERA), a novel method that introduces structured polynomial expansion directly into the low-rank factor space. By expanding each low-rank factor to synthesize high-order interaction terms before composition, PERA transforms the adaptation space into a polynomial manifold capable of modeling richer nonlinear coupling without increasing rank or inference cost. We provide theoretical analysis demonstrating that PERA offers enhanced expressive capacity and more effective feature utilization compare to existing linear adaptation approaches. Empirically, PERA consistently outperforms state-of-the-art methods across diverse benchmarks. Notably, our experiments show that incorporating high-order nonlinear components particularly square terms is crucial for enhancing expressive capacity and maintaining strong and robust performance under various rank settings. Our code is available at https://github.com/zhangwenhao6/PERA
From Clues to Generation: Language-Guided Conditional Diffusion for Cross-Domain Recommendation
Apr 07, 2026Cross-domain Recommendation (CDR) exploits multi-domain correlations to alleviate data sparsity. As a core task within this field, inter-domain recommendation focuses on predicting preferences for users who interact in a source domain but lack behavioral records in a target domain. Existing approaches predominantly rely on overlapping users as anchors for knowledge transfer. In real-world scenarios, overlapping users are often scarce, leaving the vast majority of users with only single-domain interactions. For these users, the absence of explicit alignment signals makes fine-grained preference transfer intrinsically difficult. To address this challenge, this paper proposes Language-Guided Conditional Diffusion for CDR (LGCD), a novel framework that integrates Large Language Models (LLMs) and diffusion models for inter-domain sequential recommendation. Specifically, we leverage LLM reasoning to bridge the domain gap by inferring potential target preferences for single-domain users and mapping them to real items, thereby constructing pseudo-overlapping data. We distinguish between real and pseudo-interaction pathways and introduce additional supervision constraints to mitigate the semantic noise brought by pseudo-interaction. Furthermore, we design a conditional diffusion architecture to precisely guide the generation of target user representations based on source-domain patterns. Extensive experiments demonstrate that LGCD significantly outperforms state-of-the-art methods in inter-domain recommendation tasks.
TalkLoRA: Communication-Aware Mixture of Low-Rank Adaptation for Large Language Models
Apr 07, 2026Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of Large Language Models (LLMs), and recent Mixture-of-Experts (MoE) extensions further enhance flexibility by dynamically combining multiple LoRA experts. However, existing MoE-augmented LoRA methods assume that experts operate independently, often leading to unstable routing, expert dominance. In this paper, we propose \textbf{TalkLoRA}, a communication-aware MoELoRA framework that relaxes this independence assumption by introducing expert-level communication prior to routing. TalkLoRA equips low-rank experts with a lightweight Talking Module that enables controlled information exchange across expert subspaces, producing a more robust global signal for routing. Theoretically, we show that expert communication smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures. Empirically, TalkLoRA consistently outperforms vanilla LoRA and MoELoRA across diverse language understanding and generation tasks, achieving higher parameter efficiency and more balanced expert routing under comparable parameter budgets. These results highlight structured expert communication as a principled and effective enhancement for MoE-based parameter-efficient adaptation. Code is available at https://github.com/why0129/TalkLoRA.
DemoTuner: Efficient DBMS Knobs Tuning via LLM-Assisted Demonstration Reinforcement Learning
Nov 13, 2025The performance of modern DBMSs such as MySQL and PostgreSQL heavily depends on the configuration of performance-critical knobs. Manual tuning these knobs is laborious and inefficient due to the complex and high-dimensional nature of the configuration space. Among the automated tuning methods, reinforcement learning (RL)-based methods have recently sought to improve the DBMS knobs tuning process from several different perspectives. However, they still encounter challenges with slow convergence speed during offline training. In this paper, we mainly focus on how to leverage the valuable tuning hints contained in various textual documents such as DBMS manuals and web forums to improve the offline training of RL-based methods. To this end, we propose an efficient DBMS knobs tuning framework named DemoTuner via a novel LLM-assisted demonstration reinforcement learning method. Specifically, to comprehensively and accurately mine tuning hints from documents, we design a structured chain of thought prompt to employ LLMs to conduct a condition-aware tuning hints extraction task. To effectively integrate the mined tuning hints into RL agent training, we propose a hint-aware demonstration reinforcement learning algorithm HA-DDPGfD in DemoTuner. As far as we know, DemoTuner is the first work to introduce the demonstration reinforcement learning algorithm for DBMS knobs tuning. Experimental evaluations conducted on MySQL and PostgreSQL across various workloads demonstrate the significant advantages of DemoTuner in both performance improvement and online tuning cost reduction over three representative baselines including DB-BERT, GPTuner and CDBTune. Additionally, DemoTuner also exhibits superior adaptability to application scenarios with unknown workloads.
Breaking the Modality Barrier: Generative Modeling for Accurate Molecule Retrieval from Mass Spectra
Nov 09, 2025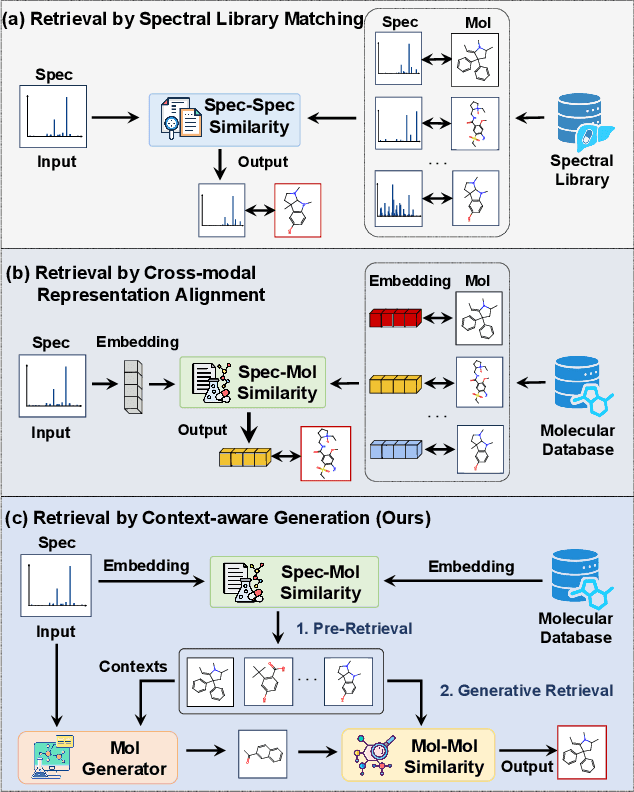
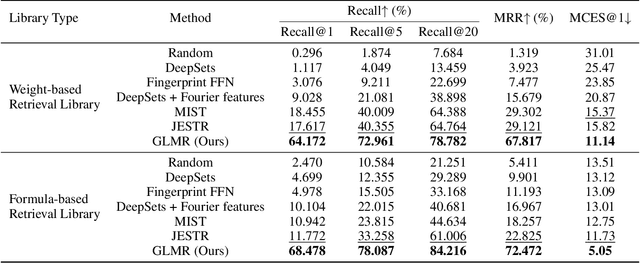
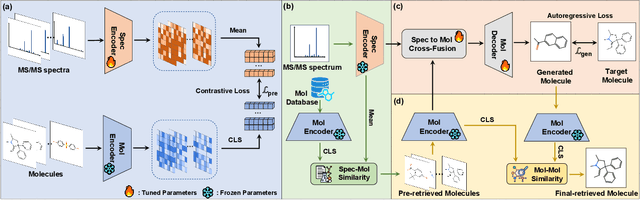
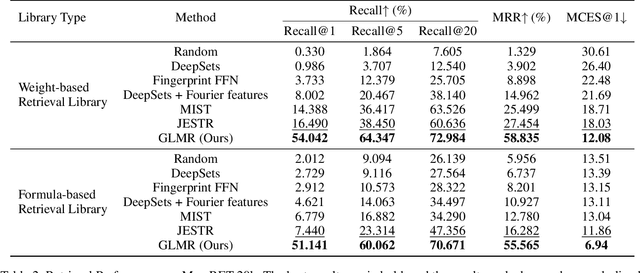
Retrieving molecular structures from tandem mass spectra is a crucial step in rapid compound identification. Existing retrieval methods, such as traditional mass spectral library matching, suffer from limited spectral library coverage, while recent cross-modal representation learning frameworks often encounter modality misalignment, resulting in suboptimal retrieval accuracy and generalization. To address these limitations, we propose GLMR, a Generative Language Model-based Retrieval framework that mitigates the cross-modal misalignment through a two-stage process. In the pre-retrieval stage, a contrastive learning-based model identifies top candidate molecules as contextual priors for the input mass spectrum. In the generative retrieval stage, these candidate molecules are integrated with the input mass spectrum to guide a generative model in producing refined molecular structures, which are then used to re-rank the candidates based on molecular similarity. Experiments on both MassSpecGym and the proposed MassRET-20k dataset demonstrate that GLMR significantly outperforms existing methods, achieving over 40% improvement in top-1 accuracy and exhibiting strong generalizability.
Heterogeneous Graph Masked Contrastive Learning for Robust Recommendation
May 30, 2025Heterogeneous graph neural networks (HGNNs) have demonstrated their superiority in exploiting auxiliary information for recommendation tasks. However, graphs constructed using meta-paths in HGNNs are usually too dense and contain a large number of noise edges. The propagation mechanism of HGNNs propagates even small amounts of noise in a graph to distant neighboring nodes, thereby affecting numerous node embeddings. To address this limitation, we introduce a novel model, named Masked Contrastive Learning (MCL), to enhance recommendation robustness to noise. MCL employs a random masking strategy to augment the graph via meta-paths, reducing node sensitivity to specific neighbors and bolstering embedding robustness. Furthermore, MCL employs contrastive cross-view on a Heterogeneous Information Network (HIN) from two perspectives: one-hop neighbors and meta-path neighbors. This approach acquires embeddings capturing both local and high-order structures simultaneously for recommendation. Empirical evaluations on three real-world datasets confirm the superiority of our approach over existing recommendation methods.
DenseLoRA: Dense Low-Rank Adaptation of Large Language Models
May 27, 2025
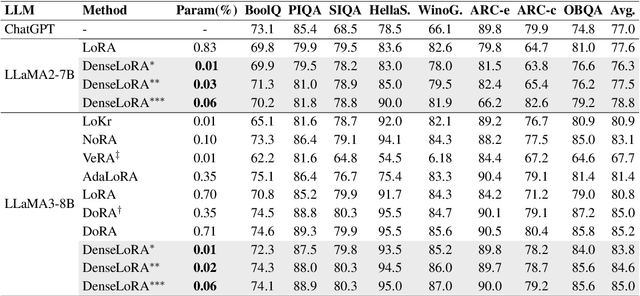
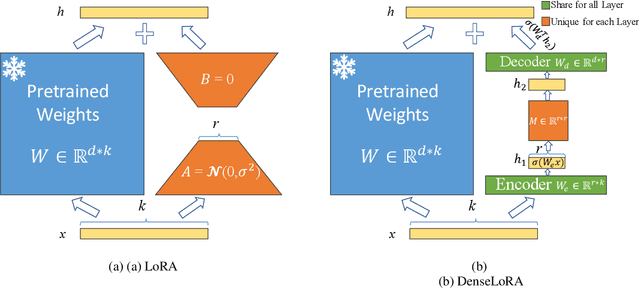

Low-rank adaptation (LoRA) has been developed as an efficient approach for adapting large language models (LLMs) by fine-tuning two low-rank matrices, thereby reducing the number of trainable parameters. However, prior research indicates that many of the weights in these matrices are redundant, leading to inefficiencies in parameter utilization. To address this limitation, we introduce Dense Low-Rank Adaptation (DenseLoRA), a novel approach that enhances parameter efficiency while achieving superior performance compared to LoRA. DenseLoRA builds upon the concept of representation fine-tuning, incorporating a single Encoder-Decoder to refine and compress hidden representations across all adaptation layers before applying adaptation. Instead of relying on two redundant low-rank matrices as in LoRA, DenseLoRA adapts LLMs through a dense low-rank matrix, improving parameter utilization and adaptation efficiency. We evaluate DenseLoRA on various benchmarks, showing that it achieves 83.8% accuracy with only 0.01% of trainable parameters, compared to LoRA's 80.8% accuracy with 0.70% of trainable parameters on LLaMA3-8B. Additionally, we conduct extensive experiments to systematically assess the impact of DenseLoRA's components on overall model performance. Code is available at https://github.com/mulin-ahu/DenseLoRA.
Revisiting Feature Interactions from the Perspective of Quadratic Neural Networks for Click-through Rate Prediction
May 23, 2025Hadamard Product (HP) has long been a cornerstone in click-through rate (CTR) prediction tasks due to its simplicity, effectiveness, and ability to capture feature interactions without additional parameters. However, the underlying reasons for its effectiveness remain unclear. In this paper, we revisit HP from the perspective of Quadratic Neural Networks (QNN), which leverage quadratic interaction terms to model complex feature relationships. We further reveal QNN's ability to expand the feature space and provide smooth nonlinear approximations without relying on activation functions. Meanwhile, we find that traditional post-activation does not further improve the performance of the QNN. Instead, mid-activation is a more suitable alternative. Through theoretical analysis and empirical evaluation of 25 QNN neuron formats, we identify a good-performing variant and make further enhancements on it. Specifically, we propose the Multi-Head Khatri-Rao Product as a superior alternative to HP and a Self-Ensemble Loss with dynamic ensemble capability within the same network to enhance computational efficiency and performance. Ultimately, we propose a novel neuron format, QNN-alpha, which is tailored for CTR prediction tasks. Experimental results show that QNN-alpha achieves new state-of-the-art performance on six public datasets while maintaining low inference latency, good scalability, and excellent compatibility. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/QNN.
Pre-trained Prompt-driven Community Search
May 18, 2025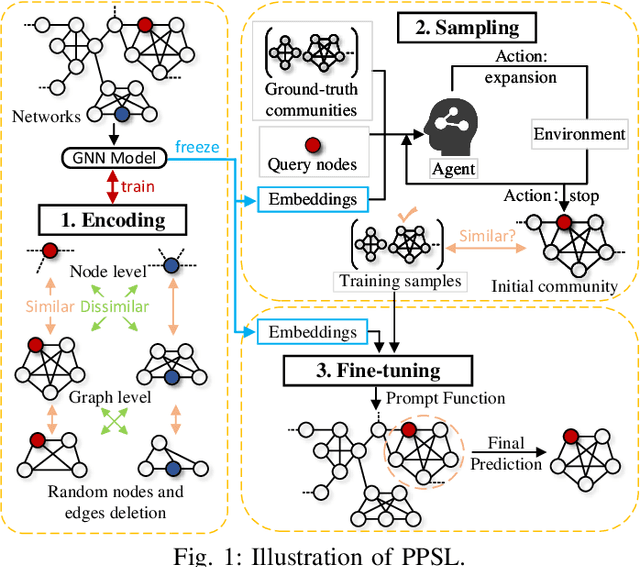
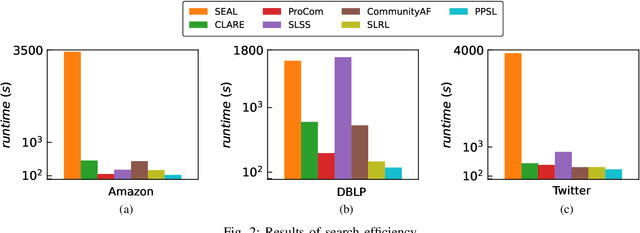
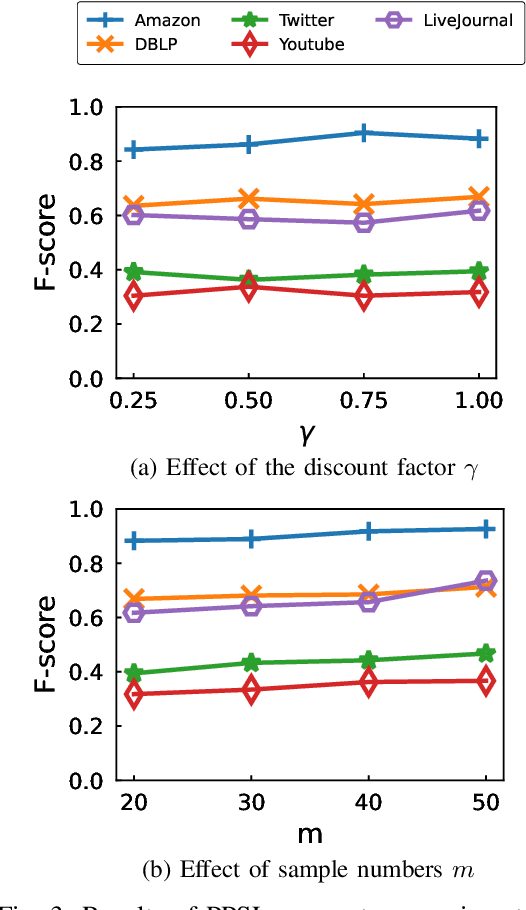

The "pre-train, prompt" paradigm is widely adopted in various graph-based tasks and has shown promising performance in community detection. Most existing semi-supervised community detection algorithms detect communities based on known ones, and the detected communities typically do not contain the given query node. Therefore, they are not suitable for searching the community of a given node. Motivated by this, we adopt this paradigm into the semi-supervised community search for the first time and propose Pre-trained Prompt-driven Community Search (PPCS), a novel model designed to enhance search accuracy and efficiency. PPCS consists of three main components: node encoding, sample generation, and prompt-driven fine-tuning. Specifically, the node encoding component employs graph neural networks to learn local structural patterns of nodes in a graph, thereby obtaining representations for nodes and communities. Next, the sample generation component identifies an initial community for a given node and selects known communities that are structurally similar to the initial one as training samples. Finally, the prompt-driven fine-tuning component leverages these samples as prompts to guide the final community prediction. Experimental results on five real-world datasets demonstrate that PPCS performs better than baseline algorithms. It also achieves higher community search efficiency than semi-supervised community search baseline methods, with ablation studies verifying the effectiveness of each component of PPCS.