 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Clues to Generation: Language-Guided Conditional Diffusion for Cross-Domain Recommendation
Apr 07, 2026Cross-domain Recommendation (CDR) exploits multi-domain correlations to alleviate data sparsity. As a core task within this field, inter-domain recommendation focuses on predicting preferences for users who interact in a source domain but lack behavioral records in a target domain. Existing approaches predominantly rely on overlapping users as anchors for knowledge transfer. In real-world scenarios, overlapping users are often scarce, leaving the vast majority of users with only single-domain interactions. For these users, the absence of explicit alignment signals makes fine-grained preference transfer intrinsically difficult. To address this challenge, this paper proposes Language-Guided Conditional Diffusion for CDR (LGCD), a novel framework that integrates Large Language Models (LLMs) and diffusion models for inter-domain sequential recommendation. Specifically, we leverage LLM reasoning to bridge the domain gap by inferring potential target preferences for single-domain users and mapping them to real items, thereby constructing pseudo-overlapping data. We distinguish between real and pseudo-interaction pathways and introduce additional supervision constraints to mitigate the semantic noise brought by pseudo-interaction. Furthermore, we design a conditional diffusion architecture to precisely guide the generation of target user representations based on source-domain patterns. Extensive experiments demonstrate that LGCD significantly outperforms state-of-the-art methods in inter-domain recommendation tasks.
Heterogeneous Graph Masked Contrastive Learning for Robust Recommendation
May 30, 2025Heterogeneous graph neural networks (HGNNs) have demonstrated their superiority in exploiting auxiliary information for recommendation tasks. However, graphs constructed using meta-paths in HGNNs are usually too dense and contain a large number of noise edges. The propagation mechanism of HGNNs propagates even small amounts of noise in a graph to distant neighboring nodes, thereby affecting numerous node embeddings. To address this limitation, we introduce a novel model, named Masked Contrastive Learning (MCL), to enhance recommendation robustness to noise. MCL employs a random masking strategy to augment the graph via meta-paths, reducing node sensitivity to specific neighbors and bolstering embedding robustness. Furthermore, MCL employs contrastive cross-view on a Heterogeneous Information Network (HIN) from two perspectives: one-hop neighbors and meta-path neighbors. This approach acquires embeddings capturing both local and high-order structures simultaneously for recommendation. Empirical evaluations on three real-world datasets confirm the superiority of our approach over existing recommendation methods.
Revisiting Feature Interactions from the Perspective of Quadratic Neural Networks for Click-through Rate Prediction
May 23, 2025Hadamard Product (HP) has long been a cornerstone in click-through rate (CTR) prediction tasks due to its simplicity, effectiveness, and ability to capture feature interactions without additional parameters. However, the underlying reasons for its effectiveness remain unclear. In this paper, we revisit HP from the perspective of Quadratic Neural Networks (QNN), which leverage quadratic interaction terms to model complex feature relationships. We further reveal QNN's ability to expand the feature space and provide smooth nonlinear approximations without relying on activation functions. Meanwhile, we find that traditional post-activation does not further improve the performance of the QNN. Instead, mid-activation is a more suitable alternative. Through theoretical analysis and empirical evaluation of 25 QNN neuron formats, we identify a good-performing variant and make further enhancements on it. Specifically, we propose the Multi-Head Khatri-Rao Product as a superior alternative to HP and a Self-Ensemble Loss with dynamic ensemble capability within the same network to enhance computational efficiency and performance. Ultimately, we propose a novel neuron format, QNN-alpha, which is tailored for CTR prediction tasks. Experimental results show that QNN-alpha achieves new state-of-the-art performance on six public datasets while maintaining low inference latency, good scalability, and excellent compatibility. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/QNN.
Quadratic Interest Network for Multimodal Click-Through Rate Prediction
Apr 24, 2025Multimodal click-through rate (CTR) prediction is a key technique in industrial recommender systems. It leverages heterogeneous modalities such as text, images, and behavioral logs to capture high-order feature interactions between users and items, thereby enhancing the system's understanding of user interests and its ability to predict click behavior. The primary challenge in this field lies in effectively utilizing the rich semantic information from multiple modalities while satisfying the low-latency requirements of online inference in real-world applications. To foster progress in this area, the Multimodal CTR Prediction Challenge Track of the WWW 2025 EReL@MIR Workshop formulates the problem into two tasks: (1) Task 1 of Multimodal Item Embedding: this task aims to explore multimodal information extraction and item representation learning methods that enhance recommendation tasks; and (2) Task 2 of Multimodal CTR Prediction: this task aims to explore what multimodal recommendation model can effectively leverage multimodal embedding features and achieve better performance. In this paper, we propose a novel model for Task 2, named Quadratic Interest Network (QIN) for Multimodal CTR Prediction. Specifically, QIN employs adaptive sparse target attention to extract multimodal user behavior features, and leverages Quadratic Neural Networks to capture high-order feature interactions. As a result, QIN achieved an AUC of 0.9798 on the leaderboard and ranked second in the competition. The model code, training logs, hyperparameter configurations, and checkpoints are available at https://github.com/salmon1802/QIN.
Unveiling Contrastive Learning's Capability of Neighborhood Aggregation for Collaborative Filtering
Apr 14, 2025



Personalized recommendation is widely used in the web applications, and graph contrastive learning (GCL) has gradually become a dominant approach in recommender systems, primarily due to its ability to extract self-supervised signals from raw interaction data, effectively alleviating the problem of data sparsity. A classic GCL-based method typically uses data augmentation during graph convolution to generates more contrastive views, and performs contrast on these new views to obtain rich self-supervised signals. Despite this paradigm is effective, the reasons behind the performance gains remain a mystery. In this paper, we first reveal via theoretical derivation that the gradient descent process of the CL objective is formally equivalent to graph convolution, which implies that CL objective inherently supports neighborhood aggregation on interaction graphs. We further substantiate this capability through experimental validation and identify common misconceptions in the selection of positive samples in previous methods, which limit the potential of CL objective. Based on this discovery, we propose the Light Contrastive Collaborative Filtering (LightCCF) method, which introduces a novel neighborhood aggregation objective to bring users closer to all interacted items while pushing them away from other positive pairs, thus achieving high-quality neighborhood aggregation with very low time complexity. On three highly sparse public datasets, the proposed method effectively aggregate neighborhood information while preventing graph over-smoothing, demonstrating significant improvements over existing GCL-based counterparts in both training efficiency and recommendation accuracy. Our implementations are publicly accessible.
Intent Representation Learning with Large Language Model for Recommendation
Feb 05, 2025



Intent-based recommender systems have garnered significant attention for uncovering latent fine-grained preferences. Intents, as underlying factors of interactions, are crucial for improving recommendation interpretability. Most methods define intents as learnable parameters updated alongside interactions. However, existing frameworks often overlook textual information (e.g., user reviews, item descriptions), which is crucial for alleviating the sparsity of interaction intents. Exploring these multimodal intents, especially the inherent differences in representation spaces, poses two key challenges: i) How to align multimodal intents and effectively mitigate noise issues; ii) How to extract and match latent key intents across modalities. To tackle these challenges, we propose a model-agnostic framework, Intent Representation Learning with Large Language Model (IRLLRec), which leverages large language models (LLMs) to construct multimodal intents and enhance recommendations. Specifically, IRLLRec employs a dual-tower architecture to learn multimodal intent representations. Next, we propose pairwise and translation alignment to eliminate inter-modal differences and enhance robustness against noisy input features. Finally, to better match textual and interaction-based intents, we employ momentum distillation to perform teacher-student learning on fused intent representations. Empirical evaluations on three datasets show that our IRLLRec framework outperforms baselines. The implementation is available at https://github.com/wangyu0627/IRLLRec.
Ensemble Learning via Knowledge Transfer for CTR Prediction
Nov 25, 2024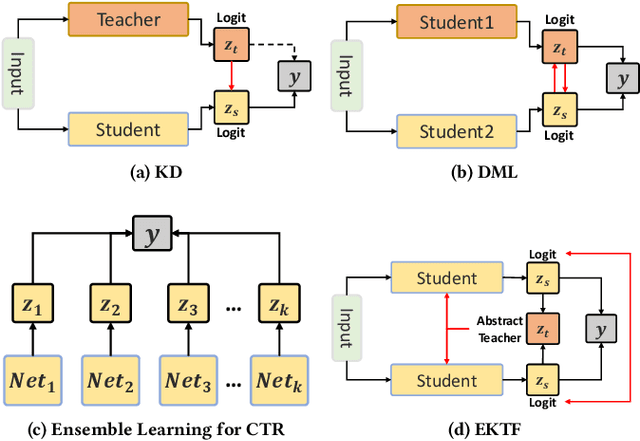
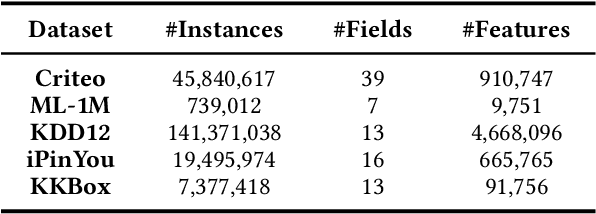
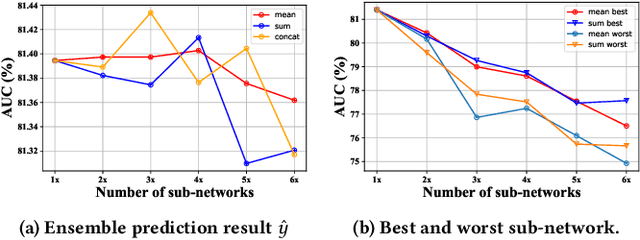
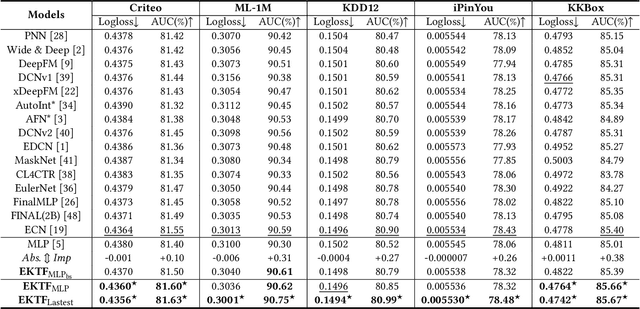
Click-through rate (CTR) prediction plays a critical role in recommender systems and web searches. While many existing methods utilize ensemble learning to improve model performance, they typically limit the ensemble to two or three sub-networks, with little exploration of larger ensembles. In this paper, we investigate larger ensemble networks and find three inherent limitations in commonly used ensemble learning method: (1) performance degradation with more networks; (2) sharp decline and high variance in sub-network performance; (3) large discrepancies between sub-network and ensemble predictions. To simultaneously address the above limitations, this paper investigates potential solutions from the perspectives of Knowledge Distillation (KD) and Deep Mutual Learning (DML). Based on the empirical performance of these methods, we combine them to propose a novel model-agnostic Ensemble Knowledge Transfer Framework (EKTF). Specifically, we employ the collective decision-making of the students as an abstract teacher to guide each student (sub-network) towards more effective learning. Additionally, we encourage mutual learning among students to enable knowledge acquisition from different views. To address the issue of balancing the loss hyperparameters, we design a novel examination mechanism to ensure tailored teaching from teacher-to-student and selective learning in peer-to-peer. Experimental results on five real-world datasets demonstrate the effectiveness and compatibility of EKTF. The code, running logs, and detailed hyperparameter configurations are available at: https://github.com/salmon1802/EKTF.
Feature Interaction Fusion Self-Distillation Network For CTR Prediction
Nov 13, 2024


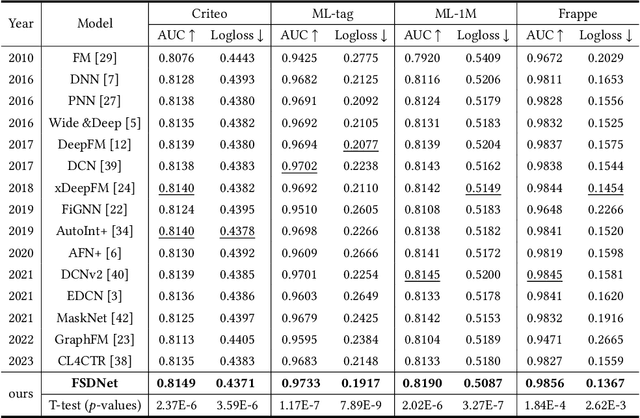
Click-Through Rate (CTR) prediction plays a vital role in recommender systems, online advertising, and search engines. Most of the current approaches model feature interactions through stacked or parallel structures, with some employing knowledge distillation for model compression. However, we observe some limitations with these approaches: (1) In parallel structure models, the explicit and implicit components are executed independently and simultaneously, which leads to insufficient information sharing within the feature set. (2) The introduction of knowledge distillation technology brings about the problems of complex teacher-student framework design and low knowledge transfer efficiency. (3) The dataset and the process of constructing high-order feature interactions contain significant noise, which limits the model's effectiveness. To address these limitations, we propose FSDNet, a CTR prediction framework incorporating a plug-and-play fusion self-distillation module. Specifically, FSDNet forms connections between explicit and implicit feature interactions at each layer, enhancing the sharing of information between different features. The deepest fusion layer is then used as the teacher model, utilizing self-distillation to guide the training of shallow layers. Empirical evaluation across four benchmark datasets validates the framework's efficacy and generalization capabilities. The code is available on https://anonymous.4open.science/r/FSDNet.
Federated Prototype-based Contrastive Learning for Privacy-Preserving Cross-domain Recommendation
Sep 05, 2024



Cross-domain recommendation (CDR) aims to improve recommendation accuracy in sparse domains by transferring knowledge from data-rich domains. However, existing CDR methods often assume the availability of user-item interaction data across domains, overlooking user privacy concerns. Furthermore, these methods suffer from performance degradation in scenarios with sparse overlapping users, as they typically depend on a large number of fully shared users for effective knowledge transfer. To address these challenges, we propose a Federated Prototype-based Contrastive Learning (CL) method for Privacy-Preserving CDR, named FedPCL-CDR. This approach utilizes non-overlapping user information and prototypes to improve multi-domain performance while protecting user privacy. FedPCL-CDR comprises two modules: local domain (client) learning and global server aggregation. In the local domain, FedPCL-CDR clusters all user data to learn representative prototypes, effectively utilizing non-overlapping user information and addressing the sparse overlapping user issue. It then facilitates knowledge transfer by employing both local and global prototypes returned from the server in a CL manner. Simultaneously, the global server aggregates representative prototypes from local domains to learn both local and global prototypes. The combination of prototypes and federated learning (FL) ensures that sensitive user data remains decentralized, with only prototypes being shared across domains, thereby protecting user privacy. Extensive experiments on four CDR tasks using two real-world datasets demonstrate that FedPCL-CDR outperforms the state-of-the-art baselines.
High-Order Fusion Graph Contrastive Learning for Recommendation
Jul 29, 2024Self-supervised learning (SSL) has recently attracted significant attention in the field of recommender systems. Contrastive learning (CL) stands out as a major SSL paradigm due to its robust ability to generate self-supervised signals. Mainstream graph contrastive learning (GCL)-based methods typically implement CL by creating contrastive views through various data augmentation techniques. Despite these methods are effective, we argue that there still exist several challenges: i) Data augmentation (e.g., discarding edges or adding noise) necessitates additional graph convolution (GCN) or modeling operations, which are highly time-consuming and potentially harm the embedding quality. ii) Existing CL-based methods use traditional CL objectives to capture self-supervised signals. However, few studies have explored obtaining CL objectives from more perspectives and have attempted to fuse the varying signals from these CL objectives to enhance recommendation performance. To overcome these challenges, we propose a High-Order Fusion Graph Contrastive Learning (HFGCL) framework for recommendation. Specifically, we discards the data augmentations and instead high-order information from GCN process to create contrastive views. Additionally, to integrate self-supervised signals from various CL objectives, we propose an advanced CL objective. By ensuring that positive pairs are distanced from negative samples derived from both contrastive views, we effectively fuse self-supervised signals from distinct CL objectives, thereby enhancing the mutual information between positive pairs. Experimental results on three public datasets demonstrate the superior effectiveness of HFGCL compared to the state-of-the-art baselines.