 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelink: Constructing Query-Driven Evidence Graph On-the-Fly for GraphRAG
Jan 12, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) mitigates hallucinations in Large Language Models (LLMs) by grounding them in structured knowledge. However, current GraphRAG methods are constrained by a prevailing \textit{build-then-reason} paradigm, which relies on a static, pre-constructed Knowledge Graph (KG). This paradigm faces two critical challenges. First, the KG's inherent incompleteness often breaks reasoning paths. Second, the graph's low signal-to-noise ratio introduces distractor facts, presenting query-relevant but misleading knowledge that disrupts the reasoning process. To address these challenges, we argue for a \textit{reason-and-construct} paradigm and propose Relink, a framework that dynamically builds a query-specific evidence graph. To tackle incompleteness, \textbf{Relink} instantiates required facts from a latent relation pool derived from the original text corpus, repairing broken paths on the fly. To handle misleading or distractor facts, Relink employs a unified, query-aware evaluation strategy that jointly considers candidates from both the KG and latent relations, selecting those most useful for answering the query rather than relying on their pre-existence. This empowers Relink to actively discard distractor facts and construct the most faithful and precise evidence path for each query. Extensive experiments on five Open-Domain Question Answering benchmarks show that Relink achieves significant average improvements of 5.4\% in EM and 5.2\% in F1 over leading GraphRAG baselines, demonstrating the superiority of our proposed framework.
Chinese Cyberbullying Detection: Dataset, Method, and Validation
May 27, 2025Existing cyberbullying detection benchmarks were organized by the polarity of speech, such as "offensive" and "non-offensive", which were essentially hate speech detection. However, in the real world, cyberbullying often attracted widespread social attention through incidents. To address this problem, we propose a novel annotation method to construct a cyberbullying dataset that organized by incidents. The constructed CHNCI is the first Chinese cyberbullying incident detection dataset, which consists of 220,676 comments in 91 incidents. Specifically, we first combine three cyberbullying detection methods based on explanations generation as an ensemble method to generate the pseudo labels, and then let human annotators judge these labels. Then we propose the evaluation criteria for validating whether it constitutes a cyberbullying incident. Experimental results demonstrate that the constructed dataset can be a benchmark for the tasks of cyberbullying detection and incident prediction. To the best of our knowledge, this is the first study for the Chinese cyberbullying incident detection task.
How to Mitigate Information Loss in Knowledge Graphs for GraphRAG: Leveraging Triple Context Restoration and Query-Driven Feedback
Jan 26, 2025Knowledge Graph (KG)-augmented Large Language Models (LLMs) have recently propelled significant advances in complex reasoning tasks, thanks to their broad domain knowledge and contextual awareness. Unfortunately, current methods often assume KGs to be complete, which is impractical given the inherent limitations of KG construction and the potential loss of contextual cues when converting unstructured text into entity-relation triples. In response, this paper proposes the Triple Context Restoration and Query-driven Feedback (TCR-QF) framework, which reconstructs the textual context underlying each triple to mitigate information loss, while dynamically refining the KG structure by iteratively incorporating query-relevant missing knowledge. Experiments on five benchmark question-answering datasets substantiate the effectiveness of TCR-QF in KG and LLM integration, where itachieves a 29.1% improvement in Exact Match and a 15.5% improvement in F1 over its state-of-the-art GraphRAG competitors.
Hybrid Local Causal Discovery
Dec 27, 2024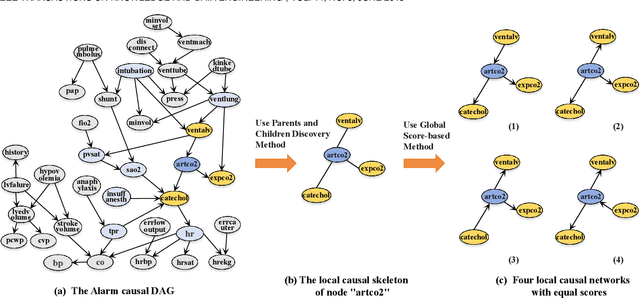
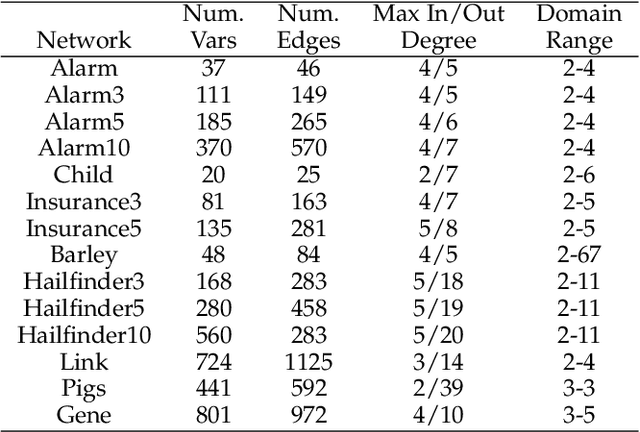
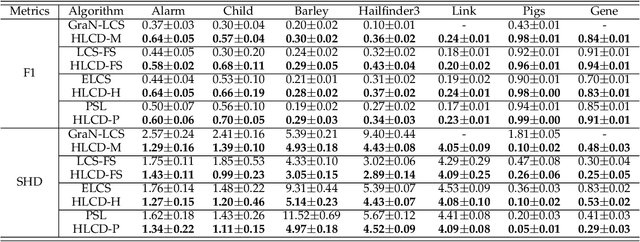
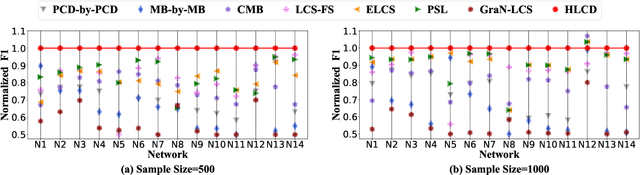
Local causal discovery aims to learn and distinguish the direct causes and effects of a target variable from observed data. Existing constraint-based local causal discovery methods use AND or OR rules in constructing the local causal skeleton, but using either rule alone is prone to produce cascading errors in the learned local causal skeleton, and thus impacting the inference of local causal relationships. On the other hand, directly applying score-based global causal discovery methods to local causal discovery may randomly return incorrect results due to the existence of local equivalence classes. To address the above issues, we propose a Hybrid Local Causal Discovery algorithm, called HLCD. Specifically, HLCD initially utilizes a constraint-based approach combined with the OR rule to obtain a candidate skeleton and then employs a score-based method to eliminate redundant portions in the candidate skeleton. Furthermore, during the local causal orientation phase, HLCD distinguishes between V-structures and equivalence classes by comparing the local structure scores between the two, thereby avoiding orientation interference caused by local equivalence classes. We conducted extensive experiments with seven state-of-the-art competitors on 14 benchmark Bayesian network datasets, and the experimental results demonstrate that HLCD significantly outperforms existing local causal discovery algorithms.
Feature Interaction Fusion Self-Distillation Network For CTR Prediction
Nov 13, 2024


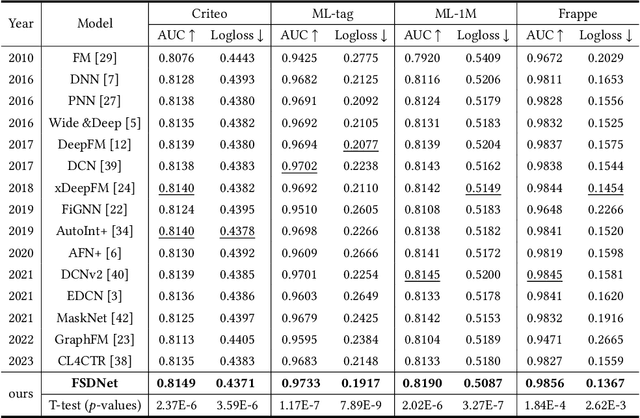
Click-Through Rate (CTR) prediction plays a vital role in recommender systems, online advertising, and search engines. Most of the current approaches model feature interactions through stacked or parallel structures, with some employing knowledge distillation for model compression. However, we observe some limitations with these approaches: (1) In parallel structure models, the explicit and implicit components are executed independently and simultaneously, which leads to insufficient information sharing within the feature set. (2) The introduction of knowledge distillation technology brings about the problems of complex teacher-student framework design and low knowledge transfer efficiency. (3) The dataset and the process of constructing high-order feature interactions contain significant noise, which limits the model's effectiveness. To address these limitations, we propose FSDNet, a CTR prediction framework incorporating a plug-and-play fusion self-distillation module. Specifically, FSDNet forms connections between explicit and implicit feature interactions at each layer, enhancing the sharing of information between different features. The deepest fusion layer is then used as the teacher model, utilizing self-distillation to guide the training of shallow layers. Empirical evaluation across four benchmark datasets validates the framework's efficacy and generalization capabilities. The code is available on https://anonymous.4open.science/r/FSDNet.
Effective Instruction Parsing Plugin for Complex Logical Query Answering on Knowledge Graphs
Oct 27, 2024

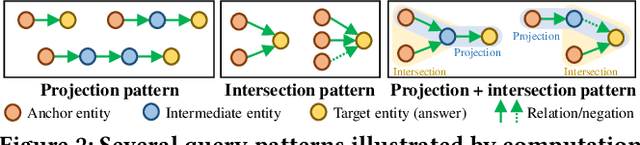

Knowledge Graph Query Embedding (KGQE) aims to embed First-Order Logic (FOL) queries in a low-dimensional KG space for complex reasoning over incomplete KGs. To enhance the generalization of KGQE models, recent studies integrate various external information (such as entity types and relation context) to better capture the logical semantics of FOL queries. The whole process is commonly referred to as Query Pattern Learning (QPL). However, current QPL methods typically suffer from the pattern-entity alignment bias problem, leading to the learned defective query patterns limiting KGQE models' performance. To address this problem, we propose an effective Query Instruction Parsing Plugin (QIPP) that leverages the context awareness of Pre-trained Language Models (PLMs) to capture latent query patterns from code-like query instructions. Unlike the external information introduced by previous QPL methods, we first propose code-like instructions to express FOL queries in an alternative format. This format utilizes textual variables and nested tuples to convey the logical semantics within FOL queries, serving as raw materials for a PLM-based instruction encoder to obtain complete query patterns. Building on this, we design a query-guided instruction decoder to adapt query patterns to KGQE models. To further enhance QIPP's effectiveness across various KGQE models, we propose a query pattern injection mechanism based on compressed optimization boundaries and an adaptive normalization component, allowing KGQE models to utilize query patterns more efficiently. Extensive experiments demonstrate that our plug-and-play method improves the performance of eight basic KGQE models and outperforms two state-of-the-art QPL methods.
Intent-guided Heterogeneous Graph Contrastive Learning for Recommendation
Jul 28, 2024



Contrastive Learning (CL)-based recommender systems have gained prominence in the context of Heterogeneous Graph (HG) due to their capacity to enhance the consistency of representations across different views. However, existing frameworks often neglect the fact that user-item interactions within HG are governed by diverse latent intents (e.g., brand preferences or demographic characteristics of item audiences), which are pivotal in capturing fine-grained relations. The exploration of these underlying intents, particularly through the lens of meta-paths in HGs, presents us with two principal challenges: i) How to integrate CL with intents; ii) How to mitigate noise from meta-path-driven intents. To address these challenges, we propose an innovative framework termed Intent-guided Heterogeneous Graph Contrastive Learning (IHGCL), which designed to enhance CL-based recommendation by capturing the intents contained within meta-paths. Specifically, the IHGCL framework includes: i) a meta-path-based Dual Contrastive Learning (DCL) approach to effectively integrate intents into the recommendation, constructing intent-intent contrast and intent-interaction contrast; ii) a Bottlenecked AutoEncoder (BAE) that combines mask propagation with the information bottleneck principle to significantly reduce noise perturbations introduced by meta-paths. Empirical evaluations conducted across six distinct datasets demonstrate the superior performance of our IHGCL framework relative to conventional baseline methods. Our model implementation is available at https://github.com/wangyu0627/IHGCL.
Synergistic Deep Graph Clustering Network
Jun 22, 2024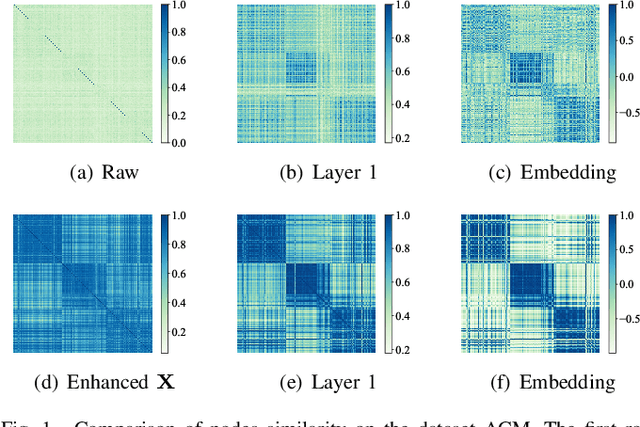
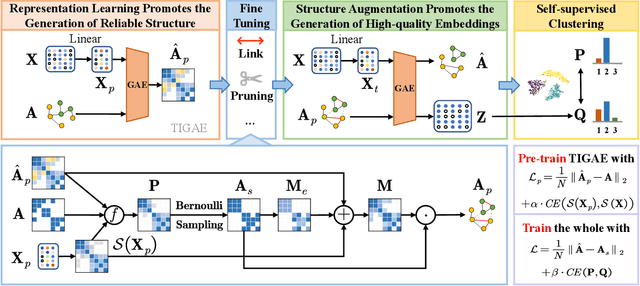
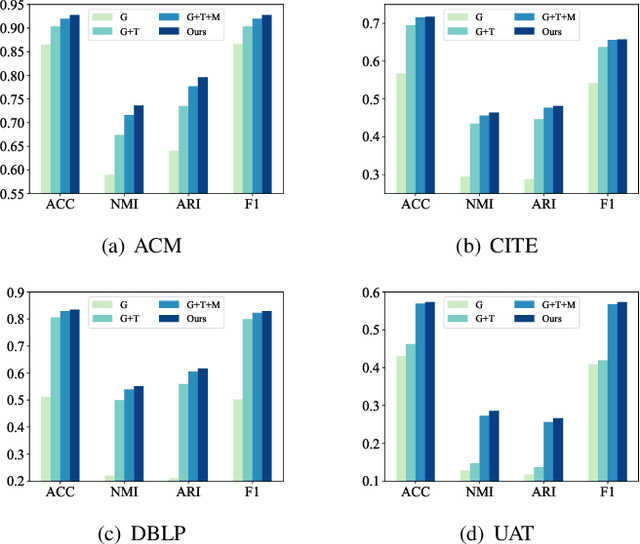
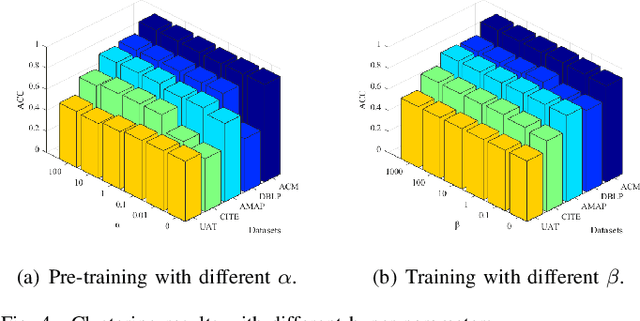
Employing graph neural networks (GNNs) to learn cohesive and discriminative node representations for clustering has shown promising results in deep graph clustering. However, existing methods disregard the reciprocal relationship between representation learning and structure augmentation. This study suggests that enhancing embedding and structure synergistically becomes imperative for GNNs to unleash their potential in deep graph clustering. A reliable structure promotes obtaining more cohesive node representations, while high-quality node representations can guide the augmentation of the structure, enhancing structural reliability in return. Moreover, the generalization ability of existing GNNs-based models is relatively poor. While they perform well on graphs with high homogeneity, they perform poorly on graphs with low homogeneity. To this end, we propose a graph clustering framework named Synergistic Deep Graph Clustering Network (SynC). In our approach, we design a Transform Input Graph Auto-Encoder (TIGAE) to obtain high-quality embeddings for guiding structure augmentation. Then, we re-capture neighborhood representations on the augmented graph to obtain clustering-friendly embeddings and conduct self-supervised clustering. Notably, representation learning and structure augmentation share weights, significantly reducing the number of model parameters. Additionally, we introduce a structure fine-tuning strategy to improve the model's generalization. Extensive experiments on benchmark datasets demonstrate the superiority and effectiveness of our method. The code is released on GitHub and Code Ocean.
Accelerating Complex Disease Treatment through Network Medicine and GenAI: A Case Study on Drug Repurposing for Breast Cancer
Jun 18, 2024The objective of this research is to introduce a network specialized in predicting drugs that can be repurposed by investigating real-world evidence sources, such as clinical trials and biomedical literature. Specifically, it aims to generate drug combination therapies for complex diseases (e.g., cancer, Alzheimer's). We present a multilayered network medicine approach, empowered by a highly configured ChatGPT prompt engineering system, which is constructed on the fly to extract drug mentions in clinical trials. Additionally, we introduce a novel algorithm that connects real-world evidence with disease-specific signaling pathways (e.g., KEGG database). This sheds light on the repurposability of drugs if they are found to bind with one or more protein constituents of a signaling pathway. To demonstrate, we instantiated the framework for breast cancer and found that, out of 46 breast cancer signaling pathways, the framework identified 38 pathways that were covered by at least two drugs. This evidence signals the potential for combining those drugs. Specifically, the most covered signaling pathway, ID hsa:2064, was covered by 108 drugs, some of which can be combined. Conversely, the signaling pathway ID hsa:1499 was covered by only two drugs, indicating a significant gap for further research. Our network medicine framework, empowered by GenAI, shows promise in identifying drug combinations with a high degree of specificity, knowing the exact signaling pathways and proteins that serve as targets. It is noteworthy that ChatGPT successfully accelerated the process of identifying drug mentions in clinical trials, though further investigations are required to determine the relationships among the drug mentions.
ConsistencyDet: A Robust Object Detector with a Denoising Paradigm of Consistency Model
Apr 17, 2024



Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on the perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a "one-step denoising" mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subsequently, in the inference stage, the model employs a denoising sampling strategy that commences with bounding boxes randomly sampled from a normal distribution. Through iterative refinement, the model transforms an assortment of arbitrarily generated boxes into definitive detections. Comprehensive evaluations employing standard benchmarks, such as MS-COCO and LVIS, corroborate that ConsistencyDet surpasses other leading-edge detectors in performance metrics. Our code is available at https://github.com/Tankowa/ConsistencyDet.