 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicScore: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 22, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
Knowledge Restoration-driven Prompt Optimization: Unlocking LLM Potential for Open-Domain Relational Triplet Extraction
Jan 21, 2026Open-domain Relational Triplet Extraction (ORTE) is the foundation for mining structured knowledge without predefined schemas. Despite the impressive in-context learning capabilities of Large Language Models (LLMs), existing methods are hindered by their reliance on static, heuristic-driven prompting strategies. Due to the lack of reflection mechanisms required to internalize erroneous signals, these methods exhibit vulnerability in semantic ambiguity, often making erroneous extraction patterns permanent. To address this bottleneck, we propose a Knowledge Reconstruction-driven Prompt Optimization (KRPO) framework to assist LLMs in continuously improving their extraction capabilities for complex ORTE task flows. Specifically, we design a self-evaluation mechanism based on knowledge restoration, which provides intrinsic feedback signals by projecting structured triplets into semantic consistency scores. Subsequently, we propose a prompt optimizer based on a textual gradient that can internalize historical experiences to iteratively optimize prompts, which can better guide LLMs to handle subsequent extraction tasks. Furthermore, to alleviate relation redundancy, we design a relation canonicalization memory that collects representative relations and provides semantically distinct schemas for the triplets. Extensive experiments across three datasets show that KRPO significantly outperforms strong baselines in the extraction F1 score.
\textsc{LogicScore}: Fine-grained Logic Evaluation of Conciseness, Completeness, and Determinateness in Attributed Question Answering
Jan 21, 2026Current evaluation methods for Attributed Question Answering (AQA) suffer from \textit{attribution myopia}: they emphasize verification of isolated statements and their attributions but overlook the global logical integrity of long-form answers. Consequently, Large Language Models (LLMs) often produce factually grounded yet logically incoherent responses with elusive deductive gaps. To mitigate this limitation, we present \textsc{LogicScore}, a unified evaluation framework that shifts the paradigm from local assessment to global reasoning scrutiny. Grounded in Horn Rules, our approach integrates a backward verification mechanism to systematically evaluate three key reasoning dimensions: \textit{Completeness} (logically sound deduction), \textit{Conciseness} (non-redundancy), and \textit{Determinateness} (consistent answer entailment). Extensive experiments across three multi-hop QA datasets (HotpotQA, MusiQue, and 2WikiMultiHopQA) and over 20 LLMs (including GPT-5, Gemini-3-Pro, LLaMA3, and task-specific tuned models) reveal a critical capability gap: leading models often achieve high attribution scores (e.g., 92.85\% precision for Gemini-3 Pro) but struggle with global reasoning quality (e.g., 35.11\% Conciseness for Gemini-3 Pro). Our work establishes a robust standard for logical evaluation, highlighting the need to prioritize reasoning coherence alongside factual grounding in LLM development. Codes are available at: https://github.com/zhichaoyan11/LogicScore.
Cumulative Path-Level Semantic Reasoning for Inductive Knowledge Graph Completion
Jan 09, 2026Conventional Knowledge Graph Completion (KGC) methods aim to infer missing information in incomplete Knowledge Graphs (KGs) by leveraging existing information, which struggle to perform effectively in scenarios involving emerging entities. Inductive KGC methods can handle the emerging entities and relations in KGs, offering greater dynamic adaptability. While existing inductive KGC methods have achieved some success, they also face challenges, such as susceptibility to noisy structural information during reasoning and difficulty in capturing long-range dependencies in reasoning paths. To address these challenges, this paper proposes the Cumulative Path-Level Semantic Reasoning for inductive knowledge graph completion (CPSR) framework, which simultaneously captures both the structural and semantic information of KGs to enhance the inductive KGC task. Specifically, the proposed CPSR employs a query-dependent masking module to adaptively mask noisy structural information while retaining important information closely related to the targets. Additionally, CPSR introduces a global semantic scoring module that evaluates both the individual contributions and the collective impact of nodes along the reasoning path within KGs. The experimental results demonstrate that CPSR achieves state-of-the-art performance.
Contrastive Learning Meets Pseudo-label-assisted Mixup Augmentation: A Comprehensive Graph Representation Framework from Local to Global
Jan 30, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness in various graph representation learning tasks. However, most existing GNNs focus primarily on capturing local information through explicit graph convolution, often neglecting global message-passing. This limitation hinders the establishment of a collaborative interaction between global and local information, which is crucial for comprehensively understanding graph data. To address these challenges, we propose a novel framework called Comprehensive Graph Representation Learning (ComGRL). ComGRL integrates local information into global information to derive powerful representations. It achieves this by implicitly smoothing local information through flexible graph contrastive learning, ensuring reliable representations for subsequent global exploration. Then ComGRL transfers the locally derived representations to a multi-head self-attention module, enhancing their discriminative ability by uncovering diverse and rich global correlations. To further optimize local information dynamically under the self-supervision of pseudo-labels, ComGRL employs a triple sampling strategy to construct mixed node pairs and applies reliable Mixup augmentation across attributes and structure for local contrastive learning. This approach broadens the receptive field and facilitates coordination between local and global representation learning, enabling them to reinforce each other. Experimental results across six widely used graph datasets demonstrate that ComGRL achieves excellent performance in node classification tasks. The code could be available at https://github.com/JinluWang1002/ComGRL.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
Effective Instruction Parsing Plugin for Complex Logical Query Answering on Knowledge Graphs
Oct 27, 2024

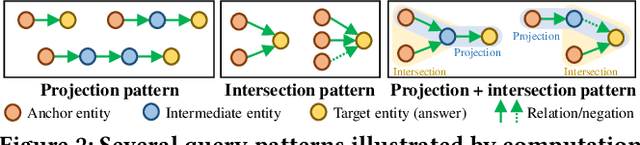

Knowledge Graph Query Embedding (KGQE) aims to embed First-Order Logic (FOL) queries in a low-dimensional KG space for complex reasoning over incomplete KGs. To enhance the generalization of KGQE models, recent studies integrate various external information (such as entity types and relation context) to better capture the logical semantics of FOL queries. The whole process is commonly referred to as Query Pattern Learning (QPL). However, current QPL methods typically suffer from the pattern-entity alignment bias problem, leading to the learned defective query patterns limiting KGQE models' performance. To address this problem, we propose an effective Query Instruction Parsing Plugin (QIPP) that leverages the context awareness of Pre-trained Language Models (PLMs) to capture latent query patterns from code-like query instructions. Unlike the external information introduced by previous QPL methods, we first propose code-like instructions to express FOL queries in an alternative format. This format utilizes textual variables and nested tuples to convey the logical semantics within FOL queries, serving as raw materials for a PLM-based instruction encoder to obtain complete query patterns. Building on this, we design a query-guided instruction decoder to adapt query patterns to KGQE models. To further enhance QIPP's effectiveness across various KGQE models, we propose a query pattern injection mechanism based on compressed optimization boundaries and an adaptive normalization component, allowing KGQE models to utilize query patterns more efficiently. Extensive experiments demonstrate that our plug-and-play method improves the performance of eight basic KGQE models and outperforms two state-of-the-art QPL methods.
Atomic Fact Decomposition Helps Attributed Question Answering
Oct 22, 2024



Attributed Question Answering (AQA) aims to provide both a trustworthy answer and a reliable attribution report for a given question. Retrieval is a widely adopted approach, including two general paradigms: Retrieval-Then-Read (RTR) and post-hoc retrieval. Recently, Large Language Models (LLMs) have shown remarkable proficiency, prompting growing interest in AQA among researchers. However, RTR-based AQA often suffers from irrelevant knowledge and rapidly changing information, even when LLMs are adopted, while post-hoc retrieval-based AQA struggles with comprehending long-form answers with complex logic, and precisely identifying the content needing revision and preserving the original intent. To tackle these problems, this paper proposes an Atomic fact decomposition-based Retrieval and Editing (ARE) framework, which decomposes the generated long-form answers into molecular clauses and atomic facts by the instruction-tuned LLMs. Notably, the instruction-tuned LLMs are fine-tuned using a well-constructed dataset, generated from large scale Knowledge Graphs (KGs). This process involves extracting one-hop neighbors from a given set of entities and transforming the result into coherent long-form text. Subsequently, ARE leverages a search engine to retrieve evidences related to atomic facts, inputting these evidences into an LLM-based verifier to determine whether the facts require expansion for re-retrieval or editing. Furthermore, the edited facts are backtracked into the original answer, with evidence aggregated based on the relationship between molecular clauses and atomic facts. Extensive evaluations demonstrate the superior performance of our proposed method over the state-of-the-arts on several datasets, with an additionally proposed new metric $Attr_{p}$ for evaluating the precision of evidence attribution.
Query-Enhanced Adaptive Semantic Path Reasoning for Inductive Knowledge Graph Completion
Jun 04, 2024Conventional Knowledge graph completion (KGC) methods aim to infer missing information in incomplete Knowledge Graphs (KGs) by leveraging existing information, which struggle to perform effectively in scenarios involving emerging entities. Inductive KGC methods can handle the emerging entities and relations in KGs, offering greater dynamic adaptability. While existing inductive KGC methods have achieved some success, they also face challenges, such as susceptibility to noisy structural information during reasoning and difficulty in capturing long-range dependencies in reasoning paths. To address these challenges, this paper proposes the Query-Enhanced Adaptive Semantic Path Reasoning (QASPR) framework, which simultaneously captures both the structural and semantic information of KGs to enhance the inductive KGC task. Specifically, the proposed QASPR employs a query-dependent masking module to adaptively mask noisy structural information while retaining important information closely related to the targets. Additionally, QASPR introduces a global semantic scoring module that evaluates both the individual contributions and the collective impact of nodes along the reasoning path within KGs. The experimental results demonstrate that QASPR achieves state-of-the-art performance.
Large Language Models-guided Dynamic Adaptation for Temporal Knowledge Graph Reasoning
May 23, 2024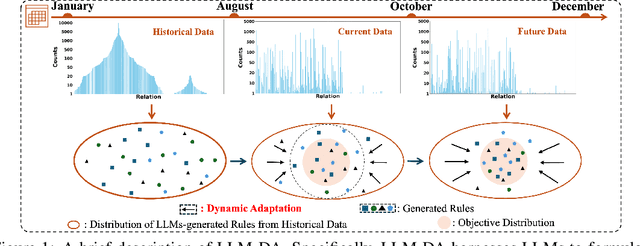
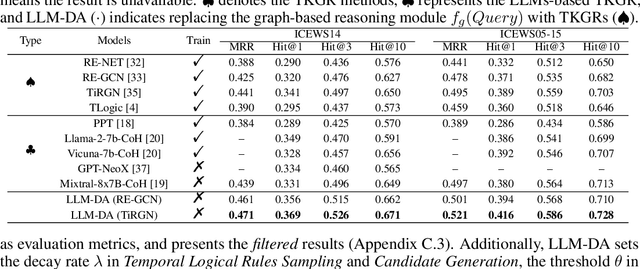
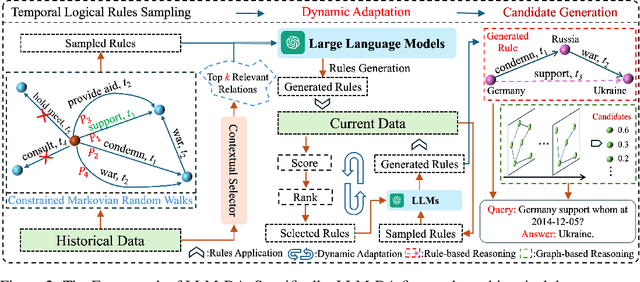

Temporal Knowledge Graph Reasoning (TKGR) is the process of utilizing temporal information to capture complex relations within a Temporal Knowledge Graph (TKG) to infer new knowledge. Conventional methods in TKGR typically depend on deep learning algorithms or temporal logical rules. However, deep learning-based TKGRs often lack interpretability, whereas rule-based TKGRs struggle to effectively learn temporal rules that capture temporal patterns. Recently, Large Language Models (LLMs) have demonstrated extensive knowledge and remarkable proficiency in temporal reasoning. Consequently, the employment of LLMs for Temporal Knowledge Graph Reasoning (TKGR) has sparked increasing interest among researchers. Nonetheless, LLMs are known to function as black boxes, making it challenging to comprehend their reasoning process. Additionally, due to the resource-intensive nature of fine-tuning, promptly updating LLMs to integrate evolving knowledge within TKGs for reasoning is impractical. To address these challenges, in this paper, we propose a Large Language Models-guided Dynamic Adaptation (LLM-DA) method for reasoning on TKGs. Specifically, LLM-DA harnesses the capabilities of LLMs to analyze historical data and extract temporal logical rules. These rules unveil temporal patterns and facilitate interpretable reasoning. To account for the evolving nature of TKGs, a dynamic adaptation strategy is proposed to update the LLM-generated rules with the latest events. This ensures that the extracted rules always incorporate the most recent knowledge and better generalize to the predictions on future events. Experimental results show that without the need of fine-tuning, LLM-DA significantly improves the accuracy of reasoning over several common datasets, providing a robust framework for TKGR tasks.