 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiener Chaos Expansion based Neural Operator for Singular Stochastic Partial Differential Equations
Mar 09, 2026In this paper, we explore how our recently developed Wiener Chaos Expansion (WCE)-based neural operator (NO) can be applied to singular stochastic partial differential equations, e.g., the dynamic $\boldsymbolΦ^4_2$ model simulated in the recent works. Unlike the previous WCE-NO which solves SPDEs by simply inserting Wick-Hermite features into the backbone NO model, we leverage feature-wise linear modulation (FiLM) to appropriately capture the dependency between the solution of singular SPDE and its smooth remainder. The resulting WCE-FiLM-NO shows excellent performance on $\boldsymbolΦ^4_2$, as measured by relative $L_2$ loss, out-of-distribution $L_2$ loss, and autocorrelation score; all without the help of renormalisation factor. In addition, we also show the potential of simulating $\boldsymbolΦ^4_3$ data, which is more aligned with real scientific practice in statistical quantum field theory. To the best of our knowledge, this is among the first works to develop an efficient data-driven surrogate for the dynamical $\boldsymbolΦ^4_3$ model.
Expanding the Chaos: Neural Operator for Stochastic (Partial) Differential Equations
Jan 03, 2026Stochastic differential equations (SDEs) and stochastic partial differential equations (SPDEs) are fundamental tools for modeling stochastic dynamics across the natural sciences and modern machine learning. Developing deep learning models for approximating their solution operators promises not only fast, practical solvers, but may also inspire models that resolve classical learning tasks from a new perspective. In this work, we build on classical Wiener chaos expansions (WCE) to design neural operator (NO) architectures for SPDEs and SDEs: we project the driving noise paths onto orthonormal Wick Hermite features and parameterize the resulting deterministic chaos coefficients with neural operators, so that full solution trajectories can be reconstructed from noise in a single forward pass. On the theoretical side, we investigate the classical WCE results for the class of multi-dimensional SDEs and semilinear SPDEs considered here by explicitly writing down the associated coupled ODE/PDE systems for their chaos coefficients, which makes the separation between stochastic forcing and deterministic dynamics fully explicit and directly motivates our model designs. On the empirical side, we validate our models on a diverse suite of problems: classical SPDE benchmarks, diffusion one-step sampling on images, topological interpolation on graphs, financial extrapolation, parameter estimation, and manifold SDEs for flood prediction, demonstrating competitive accuracy and broad applicability. Overall, our results indicate that WCE-based neural operators provide a practical and scalable way to learn SDE/SPDE solution operators across diverse domains.
ACT as Human: Multimodal Large Language Model Data Annotation with Critical Thinking
Nov 13, 2025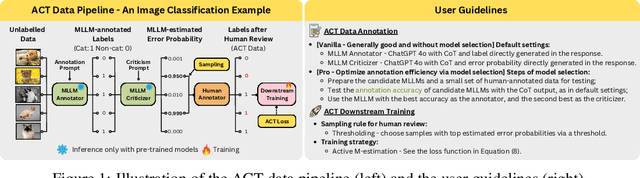



Supervised learning relies on high-quality labeled data, but obtaining such data through human annotation is both expensive and time-consuming. Recent work explores using large language models (LLMs) for annotation, but LLM-generated labels still fall short of human-level quality. To address this problem, we propose the Annotation with Critical Thinking (ACT) data pipeline, where LLMs serve not only as annotators but also as judges to critically identify potential errors. Human effort is then directed towards reviewing only the most "suspicious" cases, significantly improving the human annotation efficiency. Our major contributions are as follows: (1) ACT is applicable to a wide range of domains, including natural language processing (NLP), computer vision (CV), and multimodal understanding, by leveraging multimodal-LLMs (MLLMs). (2) Through empirical studies, we derive 7 insights on how to enhance annotation quality while efficiently reducing the human cost, and then translate these findings into user-friendly guidelines. (3) We theoretically analyze how to modify the loss function so that models trained on ACT data achieve similar performance to those trained on fully human-annotated data. Our experiments show that the performance gap can be reduced to less than 2% on most benchmark datasets while saving up to 90% of human costs.
Graph Pseudotime Analysis and Neural Stochastic Differential Equations for Analyzing Retinal Degeneration Dynamics and Beyond
Feb 10, 2025
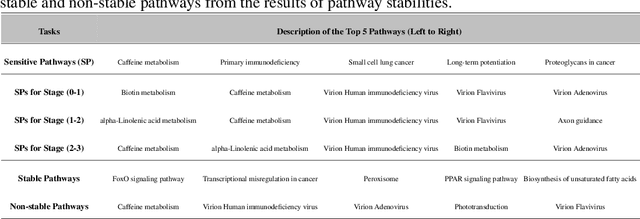


Understanding disease progression at the molecular pathway level usually requires capturing both structural dependencies between pathways and the temporal dynamics of disease evolution. In this work, we solve the former challenge by developing a biologically informed graph-forming method to efficiently construct pathway graphs for subjects from our newly curated JR5558 mouse transcriptomics dataset. We then develop Graph-level Pseudotime Analysis (GPA) to infer graph-level trajectories that reveal how disease progresses at the population level, rather than in individual subjects. Based on the trajectories estimated by GPA, we identify the most sensitive pathways that drive disease stage transitions. In addition, we measure changes in pathway features using neural stochastic differential equations (SDEs), which enables us to formally define and compute pathway stability and disease bifurcation points (points of no return), two fundamental problems in disease progression research. We further extend our theory to the case when pathways can interact with each other, enabling a more comprehensive and multi-faceted characterization of disease phenotypes. The comprehensive experimental results demonstrate the effectiveness of our framework in reconstructing the dynamics of the pathway, identifying critical transitions, and providing novel insights into the mechanistic understanding of disease evolution.
Contrastive Learning Meets Pseudo-label-assisted Mixup Augmentation: A Comprehensive Graph Representation Framework from Local to Global
Jan 30, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable effectiveness in various graph representation learning tasks. However, most existing GNNs focus primarily on capturing local information through explicit graph convolution, often neglecting global message-passing. This limitation hinders the establishment of a collaborative interaction between global and local information, which is crucial for comprehensively understanding graph data. To address these challenges, we propose a novel framework called Comprehensive Graph Representation Learning (ComGRL). ComGRL integrates local information into global information to derive powerful representations. It achieves this by implicitly smoothing local information through flexible graph contrastive learning, ensuring reliable representations for subsequent global exploration. Then ComGRL transfers the locally derived representations to a multi-head self-attention module, enhancing their discriminative ability by uncovering diverse and rich global correlations. To further optimize local information dynamically under the self-supervision of pseudo-labels, ComGRL employs a triple sampling strategy to construct mixed node pairs and applies reliable Mixup augmentation across attributes and structure for local contrastive learning. This approach broadens the receptive field and facilitates coordination between local and global representation learning, enabling them to reinforce each other. Experimental results across six widely used graph datasets demonstrate that ComGRL achieves excellent performance in node classification tasks. The code could be available at https://github.com/JinluWang1002/ComGRL.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
Dual-Frequency Filtering Self-aware Graph Neural Networks for Homophilic and Heterophilic Graphs
Nov 18, 2024
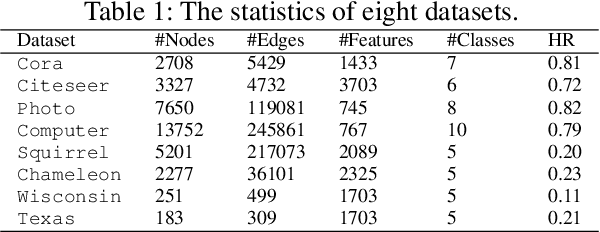
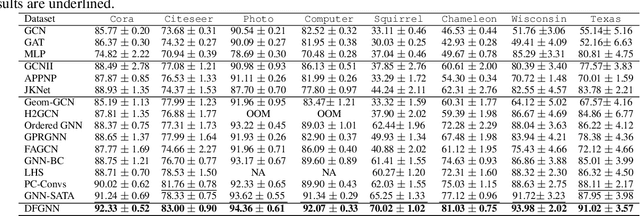

Graph Neural Networks (GNNs) have excelled in handling graph-structured data, attracting significant research interest. However, two primary challenges have emerged: interference between topology and attributes distorting node representations, and the low-pass filtering nature of most GNNs leading to the oversight of valuable high-frequency information in graph signals. These issues are particularly pronounced in heterophilic graphs. To address these challenges, we propose Dual-Frequency Filtering Self-aware Graph Neural Networks (DFGNN). DFGNN integrates low-pass and high-pass filters to extract smooth and detailed topological features, using frequency-specific constraints to minimize noise and redundancy in the respective frequency bands. The model dynamically adjusts filtering ratios to accommodate both homophilic and heterophilic graphs. Furthermore, DFGNN mitigates interference by aligning topological and attribute representations through dynamic correspondences between their respective frequency bands, enhancing overall model performance and expressiveness. Extensive experiments conducted on benchmark datasets demonstrate that DFGNN outperforms state-of-the-art methods in classification performance, highlighting its effectiveness in handling both homophilic and heterophilic graphs.
When Graph Neural Networks Meet Dynamic Mode Decomposition
Oct 08, 2024



Graph Neural Networks (GNNs) have emerged as fundamental tools for a wide range of prediction tasks on graph-structured data. Recent studies have drawn analogies between GNN feature propagation and diffusion processes, which can be interpreted as dynamical systems. In this paper, we delve deeper into this perspective by connecting the dynamics in GNNs to modern Koopman theory and its numerical method, Dynamic Mode Decomposition (DMD). We illustrate how DMD can estimate a low-rank, finite-dimensional linear operator based on multiple states of the system, effectively approximating potential nonlinear interactions between nodes in the graph. This approach allows us to capture complex dynamics within the graph accurately and efficiently. We theoretically establish a connection between the DMD-estimated operator and the original dynamic operator between system states. Building upon this foundation, we introduce a family of DMD-GNN models that effectively leverage the low-rank eigenfunctions provided by the DMD algorithm. We further discuss the potential of enhancing our approach by incorporating domain-specific constraints such as symmetry into the DMD computation, allowing the corresponding GNN models to respect known physical properties of the underlying system. Our work paves the path for applying advanced dynamical system analysis tools via GNNs. We validate our approach through extensive experiments on various learning tasks, including directed graphs, large-scale graphs, long-range interactions, and spatial-temporal graphs. We also empirically verify that our proposed models can serve as powerful encoders for link prediction tasks. The results demonstrate that our DMD-enhanced GNNs achieve state-of-the-art performance, highlighting the effectiveness of integrating DMD into GNN frameworks.
Diffusing to the Top: Boost Graph Neural Networks with Minimal Hyperparameter Tuning
Oct 08, 2024



Graph Neural Networks (GNNs) are proficient in graph representation learning and achieve promising performance on versatile tasks such as node classification and link prediction. Usually, a comprehensive hyperparameter tuning is essential for fully unlocking GNN's top performance, especially for complicated tasks such as node classification on large graphs and long-range graphs. This is usually associated with high computational and time costs and careful design of appropriate search spaces. This work introduces a graph-conditioned latent diffusion framework (GNN-Diff) to generate high-performing GNNs based on the model checkpoints of sub-optimal hyperparameters selected by a light-tuning coarse search. We validate our method through 166 experiments across four graph tasks: node classification on small, large, and long-range graphs, as well as link prediction. Our experiments involve 10 classic and state-of-the-art target models and 20 publicly available datasets. The results consistently demonstrate that GNN-Diff: (1) boosts the performance of GNNs with efficient hyperparameter tuning; and (2) presents high stability and generalizability on unseen data across multiple generation runs. The code is available at https://github.com/lequanlin/GNN-Diff.
A Riemannian Approach to Ground Metric Learning for Optimal Transport
Sep 16, 2024
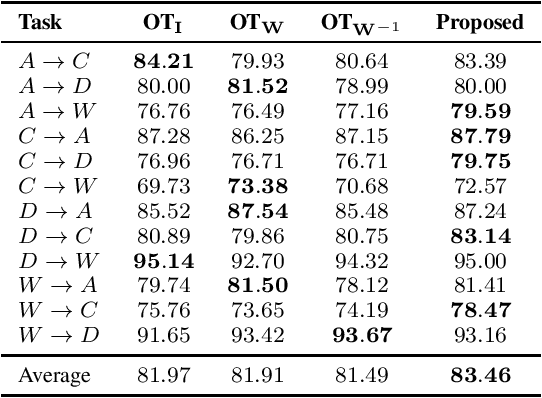
Optimal transport (OT) theory has attracted much attention in machine learning and signal processing applications. OT defines a notion of distance between probability distributions of source and target data points. A crucial factor that influences OT-based distances is the ground metric of the embedding space in which the source and target data points lie. In this work, we propose to learn a suitable latent ground metric parameterized by a symmetric positive definite matrix. We use the rich Riemannian geometry of symmetric positive definite matrices to jointly learn the OT distance along with the ground metric. Empirical results illustrate the efficacy of the learned metric in OT-based domain adaptation.