 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Matter Equally: Dynamic In-context Vector Distillation with Decisive-Token Supervision for Long-form Medical Report Generation
May 26, 2026Distilling demonstration effects into hidden-space interventions offers a lightweight alternative to full finetuning. However, existing multimodal variants are mostly evaluated on short-form tasks, where outputs end after a few tokens. Extending these methods to long-form generation exposes a fundamental yet underexamined limitation: token-level distillation implicitly treats all output tokens as equally informative, but long-form outputs are dominated by high-frequency template and grammatical tokens, while the tokens that actually determine output quality are sparsely distributed. In medical report generation (MRG), two such decisive tokens stand out: pathology-related tokens that determine diagnostic content, and the end-of-sequence (EOS) event that determines termination. Both receive insufficient supervision under uniform cross-entropy, and autoregressive decoding further compounds the problem by drifting away from teacher-forced trajectories. We propose DIVE, a frozen-backbone distillation framework that addresses long-form report generation through two complementary mechanisms matched to these failures. Decisive-token supervision restores supervision balance by upweighting the cross-entropy contribution of pathology-related tokens and the EOS event, ensuring that content fidelity and termination are learned during training rather than imposed at decoding time. State-conditioned dynamic steering replaces fixed open-loop residuals with hidden-state-dependent adapters, allowing the injected signal to adapt as decoding drifts. Experiments on MIMIC-CXR and CheXpert Plus with two medical VLM backbones show that DIVE consistently ranks among the strongest methods across lexical and clinical-proxy metrics. Our method achieves the best BLEU-4, ROUGE-L, and RadGraph F1 in all dataset--backbone settings, while remaining competitive on coarse label-level CheXbert F1.
Modality-Aware and Anatomical Vector-Quantized Autoencoding for Multimodal Brain MRI
Apr 06, 2026Learning a robust Variational Autoencoder (VAE) is a fundamental step for many deep learning applications in medical image analysis, such as MRI synthesizes. Existing brain VAEs predominantly focus on single-modality data (i.e., T1-weighted MRI), overlooking the complementary diagnostic value of other modalities like T2-weighted MRIs. Here, we propose a modality-aware and anatomically grounded 3D vector-quantized VAE (VQ-VAE) for reconstructing multi-modal brain MRIs. Called NeuroQuant, it first learns a shared latent representation across modalities using factorized multi-axis attention, which can capture relationships between distant brain regions. It then employs a dual-stream 3D encoder that explicitly separates the encoding of modality-invariant anatomical structures from modality-dependent appearance. Next, the anatomical encoding is discretized using a shared codebook and combined with modality-specific appearance features via Feature-wise Linear Modulation (FiLM) during the decoding phase. This entire approach is trained using a joint 2D/3D strategy in order to account for the slice-based acquisition of 3D MRI data. Extensive experiments on two multi-modal brain MRI datasets demonstrate that NeuroQuant achieves superior reconstruction fidelity compared to existing VAEs, enabling a scalable foundation for downstream generative modeling and cross-modal brain image analysis.
A Generative Foundation Model for Multimodal Histopathology
Apr 04, 2026Accurate diagnosis and treatment of complex diseases require integrating histological, molecular, and clinical data, yet in practice these modalities are often incomplete owing to tissue scarcity, assay cost, and workflow constraints. Existing computational approaches attempt to impute missing modalities from available data but rely on task-specific models trained on narrow, single source-target pairs, limiting their generalizability. Here we introduce MuPD (Multimodal Pathology Diffusion), a generative foundation model that embeds hematoxylin and eosin (H&E)-stained histology, molecular RNA profiles, and clinical text into a shared latent space through a diffusion transformer with decoupled cross-modal attention. Pretrained on 100 million histology image patches, 1.6 million text-histology pairs, and 10.8 million RNA-histology pairs spanning 34 human organs, MuPD supports diverse cross-modal synthesis tasks with minimal or no task-specific fine-tuning. For text-conditioned and image-to-image generation, MuPD synthesizes histologically faithful tissue architectures, reducing Fréchet inception distance (FID) scores by 50% relative to domain-specific models and improving few-shot classification accuracy by up to 47% through synthetic data augmentation. For RNA-conditioned histology generation, MuPD reduces FID by 23% compared with the next-best method while preserving cell-type distributions across five cancer types. As a virtual stainer, MuPD translates H&E images to immunohistochemistry and multiplex immunofluorescence, improving average marker correlation by 37% over existing approaches. These results demonstrate that a single, unified generative model pretrained across heterogeneous pathology modalities can substantially outperform specialized alternatives, providing a scalable computational framework for multimodal histopathology.
When Understanding Becomes a Risk: Authenticity and Safety Risks in the Emerging Image Generation Paradigm
Mar 25, 2026Recently, multimodal large language models (MLLMs) have emerged as a unified paradigm for language and image generation. Compared with diffusion models, MLLMs possess a much stronger capability for semantic understanding, enabling them to process more complex textual inputs and comprehend richer contextual meanings. However, this enhanced semantic ability may also introduce new and potentially greater safety risks. Taking diffusion models as a reference point, we systematically analyze and compare the safety risks of emerging MLLMs along two dimensions: unsafe content generation and fake image synthesis. Across multiple unsafe generation benchmark datasets, we observe that MLLMs tend to generate more unsafe images than diffusion models. This difference partly arises because diffusion models often fail to interpret abstract prompts, producing corrupted outputs, whereas MLLMs can comprehend these prompts and generate unsafe content. For current advanced fake image detectors, MLLM-generated images are also notably harder to identify. Even when detectors are retrained with MLLMs-specific data, they can still be bypassed by simply providing MLLMs with longer and more descriptive inputs. Our measurements indicate that the emerging safety risks of the cutting-edge generative paradigm, MLLMs, have not been sufficiently recognized, posing new challenges to real-world safety.
Suppressing Prior-Comparison Hallucinations in Radiology Report Generation via Semantically Decoupled Latent Steering
Feb 27, 2026Automated radiology report generation using vision-language models (VLMs) is limited by the risk of prior-comparison hallucination, where the model generates historical findings unsupported by the current study. We address this challenge with a training-free, inference-time control framework termed Semantically Decoupled Latent Steering (SDLS). Unlike generic activation steering, which often suffers from semantic entanglement, our approach constructs a semantic-free intervention vector via large language model (LLM)-driven semantic decomposition followed by $QR$-based orthogonalization. This orthogonalization step is critical. It leverages geometric constraints to filter out the clinical semantics often entangled in standard principal component analysis (PCA) directions, ensuring that the steering vector targets only the ``historical comparison" axis. We validate our method on the BiomedGPT foundation model, demonstrating that it overcomes the trade-off between hallucination suppression and clinical accuracy. Extensive experiments on MIMIC-CXR, and zero-shot transfer evaluation on CheXpert Plus and IU-Xray, demonstrate the robustness of our approach. Quantitative evaluations on MIMIC-CXR show that our approach significantly reduces the probability of historical hallucinations (FilBERT score decreases from 0.2373 to 0.1889) and improves clinical label fidelity (CheXpert macro-F1 increases from 0.2242 to 0.3208). Supplementary evaluations confirm that the structural integrity of the clinical narrative is maintained.
Redefining the Down-Sampling Scheme of U-Net for Precision Biomedical Image Segmentation
Feb 23, 2026U-Net architectures have been instrumental in advancing biomedical image segmentation (BIS) but often struggle with capturing long-range information. One reason is the conventional down-sampling techniques that prioritize computational efficiency at the expense of information retention. This paper introduces a simple but effective strategy, we call it Stair Pooling, which moderates the pace of down-sampling and reduces information loss by leveraging a sequence of concatenated small and narrow pooling operations in varied orientations. Specifically, our method modifies the reduction in dimensionality within each 2D pooling step from $\frac{1}{4}$ to $\frac{1}{2}$. This approach can also be adapted for 3D pooling to preserve even more information. Such preservation aids the U-Net in more effectively reconstructing spatial details during the up-sampling phase, thereby enhancing its ability to capture long-range information and improving segmentation accuracy. Extensive experiments on three BIS benchmarks demonstrate that the proposed Stair Pooling can increase both 2D and 3D U-Net performance by an average of 3.8\% in Dice scores. Moreover, we leverage the transfer entropy to select the optimal down-sampling paths and quantitatively show how the proposed Stair Pooling reduces the information loss.
Sparse Models, Sparse Safety: Unsafe Routes in Mixture-of-Experts LLMs
Feb 09, 2026By introducing routers to selectively activate experts in Transformer layers, the mixture-of-experts (MoE) architecture significantly reduces computational costs in large language models (LLMs) while maintaining competitive performance, especially for models with massive parameters. However, prior work has largely focused on utility and efficiency, leaving the safety risks associated with this sparse architecture underexplored. In this work, we show that the safety of MoE LLMs is as sparse as their architecture by discovering unsafe routes: routing configurations that, once activated, convert safe outputs into harmful ones. Specifically, we first introduce the Router Safety importance score (RoSais) to quantify the safety criticality of each layer's router. Manipulation of only the high-RoSais router(s) can flip the default route into an unsafe one. For instance, on JailbreakBench, masking 5 routers in DeepSeek-V2-Lite increases attack success rate (ASR) by over 4$\times$ to 0.79, highlighting an inherent risk that router manipulation may naturally occur in MoE LLMs. We further propose a Fine-grained token-layer-wise Stochastic Optimization framework to discover more concrete Unsafe Routes (F-SOUR), which explicitly considers the sequentiality and dynamics of input tokens. Across four representative MoE LLM families, F-SOUR achieves an average ASR of 0.90 and 0.98 on JailbreakBench and AdvBench, respectively. Finally, we outline defensive perspectives, including safety-aware route disabling and router training, as promising directions to safeguard MoE LLMs. We hope our work can inform future red-teaming and safeguarding of MoE LLMs. Our code is provided in https://github.com/TrustAIRLab/UnsafeMoE.
Integrating Anatomical Priors into a Causal Diffusion Model
Sep 10, 2025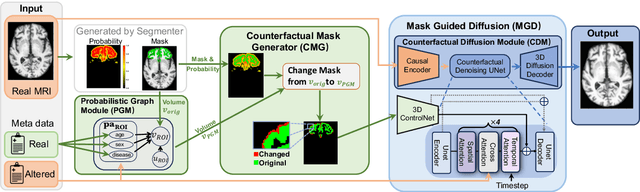
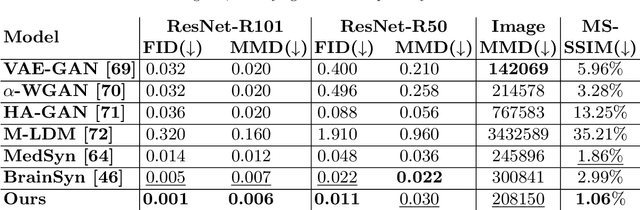
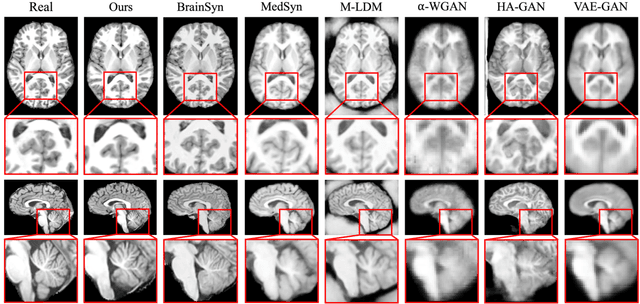

3D brain MRI studies often examine subtle morphometric differences between cohorts that are hard to detect visually. Given the high cost of MRI acquisition, these studies could greatly benefit from image syntheses, particularly counterfactual image generation, as seen in other domains, such as computer vision. However, counterfactual models struggle to produce anatomically plausible MRIs due to the lack of explicit inductive biases to preserve fine-grained anatomical details. This shortcoming arises from the training of the models aiming to optimize for the overall appearance of the images (e.g., via cross-entropy) rather than preserving subtle, yet medically relevant, local variations across subjects. To preserve subtle variations, we propose to explicitly integrate anatomical constraints on a voxel-level as prior into a generative diffusion framework. Called Probabilistic Causal Graph Model (PCGM), the approach captures anatomical constraints via a probabilistic graph module and translates those constraints into spatial binary masks of regions where subtle variations occur. The masks (encoded by a 3D extension of ControlNet) constrain a novel counterfactual denoising UNet, whose encodings are then transferred into high-quality brain MRIs via our 3D diffusion decoder. Extensive experiments on multiple datasets demonstrate that PCGM generates structural brain MRIs of higher quality than several baseline approaches. Furthermore, we show for the first time that brain measurements extracted from counterfactuals (generated by PCGM) replicate the subtle effects of a disease on cortical brain regions previously reported in the neuroscience literature. This achievement is an important milestone in the use of synthetic MRIs in studies investigating subtle morphological differences.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
Excessive Reasoning Attack on Reasoning LLMs
Jun 17, 2025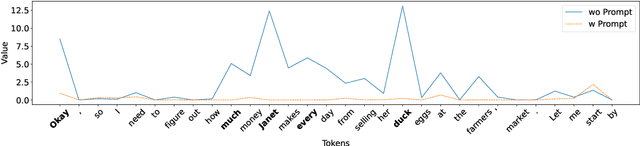


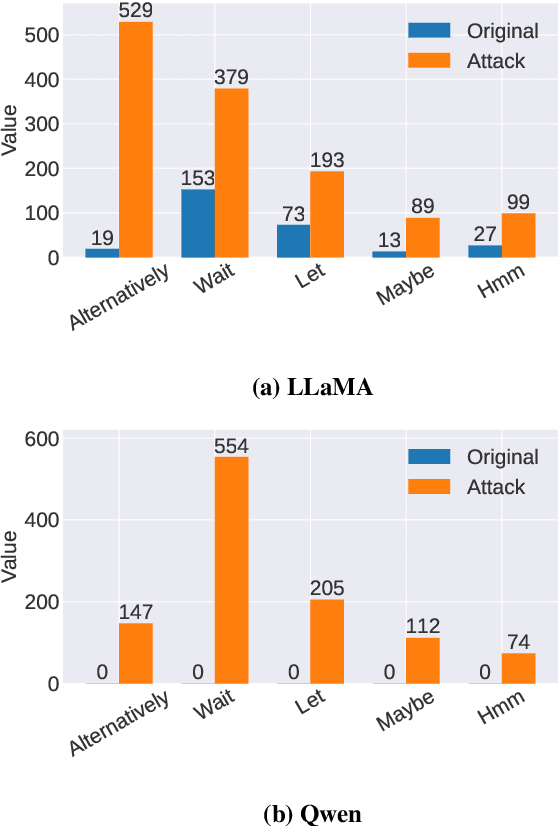
Recent reasoning large language models (LLMs), such as OpenAI o1 and DeepSeek-R1, exhibit strong performance on complex tasks through test-time inference scaling. However, prior studies have shown that these models often incur significant computational costs due to excessive reasoning, such as frequent switching between reasoning trajectories (e.g., underthinking) or redundant reasoning on simple questions (e.g., overthinking). In this work, we expose a novel threat: adversarial inputs can be crafted to exploit excessive reasoning behaviors and substantially increase computational overhead without compromising model utility. Therefore, we propose a novel loss framework consisting of three components: (1) Priority Cross-Entropy Loss, a modification of the standard cross-entropy objective that emphasizes key tokens by leveraging the autoregressive nature of LMs; (2) Excessive Reasoning Loss, which encourages the model to initiate additional reasoning paths during inference; and (3) Delayed Termination Loss, which is designed to extend the reasoning process and defer the generation of final outputs. We optimize and evaluate our attack for the GSM8K and ORCA datasets on DeepSeek-R1-Distill-LLaMA and DeepSeek-R1-Distill-Qwen. Empirical results demonstrate a 3x to 9x increase in reasoning length with comparable utility performance. Furthermore, our crafted adversarial inputs exhibit transferability, inducing computational overhead in o3-mini, o1-mini, DeepSeek-R1, and QWQ models.