 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
Feb 06, 2026We introduce Baichuan-M3, a medical-enhanced large language model engineered to shift the paradigm from passive question-answering to active, clinical-grade decision support. Addressing the limitations of existing systems in open-ended consultations, Baichuan-M3 utilizes a specialized training pipeline to model the systematic workflow of a physician. Key capabilities include: (i) proactive information acquisition to resolve ambiguity; (ii) long-horizon reasoning that unifies scattered evidence into coherent diagnoses; and (iii) adaptive hallucination suppression to ensure factual reliability. Empirical evaluations demonstrate that Baichuan-M3 achieves state-of-the-art results on HealthBench, the newly introduced HealthBench-Hallu and ScanBench, significantly outperforming GPT-5.2 in clinical inquiry, advisory and safety. The models are publicly available at https://huggingface.co/collections/baichuan-inc/baichuan-m3.
TERD: A Unified Framework for Safeguarding Diffusion Models Against Backdoors
Sep 09, 2024



Diffusion models have achieved notable success in image generation, but they remain highly vulnerable to backdoor attacks, which compromise their integrity by producing specific undesirable outputs when presented with a pre-defined trigger. In this paper, we investigate how to protect diffusion models from this dangerous threat. Specifically, we propose TERD, a backdoor defense framework that builds unified modeling for current attacks, which enables us to derive an accessible reversed loss. A trigger reversion strategy is further employed: an initial approximation of the trigger through noise sampled from a prior distribution, followed by refinement through differential multi-step samplers. Additionally, with the reversed trigger, we propose backdoor detection from the noise space, introducing the first backdoor input detection approach for diffusion models and a novel model detection algorithm that calculates the KL divergence between reversed and benign distributions. Extensive evaluations demonstrate that TERD secures a 100% True Positive Rate (TPR) and True Negative Rate (TNR) across datasets of varying resolutions. TERD also demonstrates nice adaptability to other Stochastic Differential Equation (SDE)-based models. Our code is available at https://github.com/PKU-ML/TERD.
PID: Prompt-Independent Data Protection Against Latent Diffusion Models
Jun 14, 2024The few-shot fine-tuning of Latent Diffusion Models (LDMs) has enabled them to grasp new concepts from a limited number of images. However, given the vast amount of personal images accessible online, this capability raises critical concerns about civil privacy. While several previous defense methods have been developed to prevent such misuse of LDMs, they typically assume that the textual prompts used by data protectors exactly match those employed by data exploiters. In this paper, we first empirically demonstrate that breaking this assumption, i.e., in cases where discrepancies exist between the textual conditions used by protectors and exploiters, could substantially reduce the effectiveness of these defenses. Furthermore, considering the visual encoder's independence from textual prompts, we delve into the visual encoder and thoroughly investigate how manipulating the visual encoder affects the few-shot fine-tuning process of LDMs. Drawing on these insights, we propose a simple yet effective method called \textbf{Prompt-Independent Defense (PID)} to safeguard privacy against LDMs. We show that PID can act as a strong privacy shield on its own while requiring significantly less computational power. We believe our studies, along with the comprehensive understanding and new defense method, provide a notable advance toward reliable data protection against LDMs.
Studious Bob Fight Back Against Jailbreaking via Prompt Adversarial Tuning
Feb 09, 2024Although Large Language Models (LLMs) have achieved tremendous success in various applications, they are also susceptible to certain prompts that can induce them to bypass built-in safety measures and provide dangerous or illegal content, a phenomenon known as jailbreak. To protect LLMs from producing harmful information, various defense strategies are proposed, with most focusing on content filtering or adversarial training of models. In this paper, we propose an approach named Prompt Adversarial Tuning (PAT) to train a defense control mechanism, which is then embedded as a prefix to user prompts to implement our defense strategy. We design a training process similar to adversarial training to achieve our optimized goal, alternating between updating attack and defense controls. To our knowledge, we are the first to implement defense from the perspective of prompt tuning. Once employed, our method will hardly impact the operational efficiency of LLMs. Experiments show that our method is effective in both black-box and white-box settings, reducing the success rate of advanced attacks to nearly 0 while maintaining the benign answer rate of 80% to simple benign questions. Our work might potentially chart a new perspective for future explorations in LLM security.
When Adversarial Training Meets Vision Transformers: Recipes from Training to Architecture
Oct 14, 2022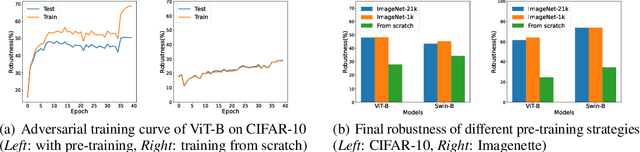
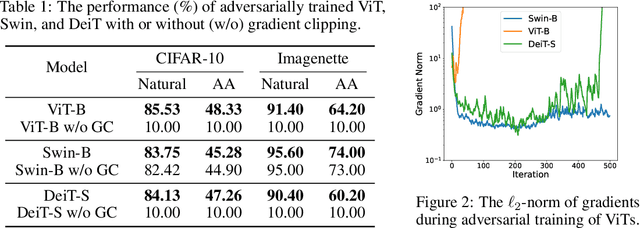
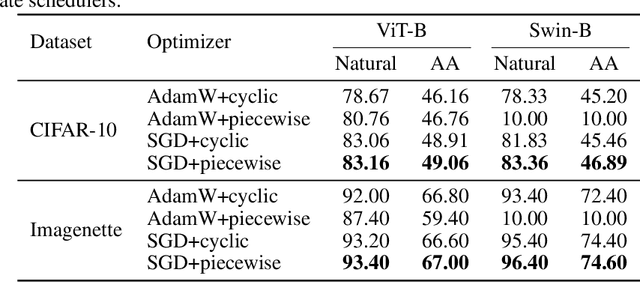
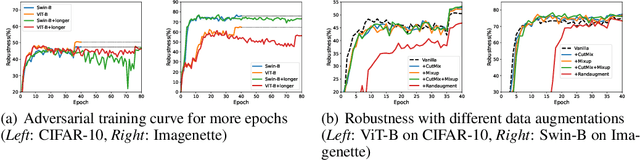
Vision Transformers (ViTs) have recently achieved competitive performance in broad vision tasks. Unfortunately, on popular threat models, naturally trained ViTs are shown to provide no more adversarial robustness than convolutional neural networks (CNNs). Adversarial training is still required for ViTs to defend against such adversarial attacks. In this paper, we provide the first and comprehensive study on the adversarial training recipe of ViTs via extensive evaluation of various training techniques across benchmark datasets. We find that pre-training and SGD optimizer are necessary for ViTs' adversarial training. Further considering ViT as a new type of model architecture, we investigate its adversarial robustness from the perspective of its unique architectural components. We find, when randomly masking gradients from some attention blocks or masking perturbations on some patches during adversarial training, the adversarial robustness of ViTs can be remarkably improved, which may potentially open up a line of work to explore the architectural information inside the newly designed models like ViTs. Our code is available at https://github.com/mo666666/When-Adversarial-Training-Meets-Vision-Transformers.