 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Visual Ignorance in Vision-Language Models
Jun 05, 2026Vision-Language Models (VLMs) frequently rely on language priors, producing confident answers that are weakly grounded in visual evidence. While this behavior is widely observed, its internal mechanisms and its impact on benchmark evaluation remain insufficiently understood. In this work, we study language-prior reliance from both mechanistic and behavioral perspectives. Internally, we combine counterfactual layer replacement with supervised layer-wise MLP probing to trace how ground-truth visual semantics and language-prior semantics compete across the language decoder. Our analysis reveals a multi-stage bottleneck: intermediate layers often fail to effectively retrieve visual information, while later layers can further suppress surviving visual signals in favor of text-space biases. Externally, we introduce a progressive visual decay metric based on multi-step Gaussian blurring, which identifies instances whose answers remain invariant even as visual content is increasingly destroyed. Across twelve visual question-answering benchmarks and three representative VLMs, we find that a substantial fraction of examples remain answerable under severe or total visual obfuscation, indicating that current benchmarks can inadvertently reward visual ignorance. These findings demonstrate that language-prior reliance is a systematic routing failure affecting both model internals and benchmark validity. Finally, we outline critical pathways for future research, highlighting the necessity of designing training distributions and evaluation protocols built on structurally isolated or counterfactual data to enforce genuine cross-modal grounding.
Automated Formal Proofs of Combinatorial Identities via Wilf-Zeilberger Guidance and LLMs
May 06, 2026Automating formal proofs of combinatorial identities is challenging for LLM-based provers, as long-horizon proof planning is required and unconstrained search quickly explodes. Symbolic methods such as the Wilf-Zeilberger (WZ) method can achieve a mechanized proof of combinatorial identities by constructing special auxiliary functions and demonstrating that they satisfy specific recurrence relations. We propose WZ-LLM, a neuro-symbolic framework that turns WZ proof plans into executable proof sketches in Lean 4 and uses an LLM-based prover to discharge the resulting machine-checkable subgoals. We also train a dedicated WZ-Prover via a Lean-kernel-verified bootstrapping loop with expert-verified iteration, followed by DAPO-based refinement. Experiments show that WZ-LLM achieves a 34% proof success rate on LCI-Test (100 classic combinatorial identities), outperforming strong baselines such as DeepSeek-V3 and Goedel-Prover-V2, and delivering consistent gains on CombiBench and PutnamBench-Comb. These results indicate that our framework provides two complementary strengths: improved direct proving for identities beyond the scope of WZ, and substantially higher end-to-end success when WZ sketches guide a specialized prover.
SAE as a Crystal Ball: Interpretable Features Predict Cross-domain Transferability of LLMs without Training
Mar 03, 2026In recent years, pre-trained large language models have achieved remarkable success across diverse tasks. Besides the pivotal role of self-supervised pre-training, their effectiveness in downstream applications also depends critically on the post-training process, which adapts models to task-specific data and objectives. However, this process inevitably introduces model shifts that can influence performance in different domains, and how such shifts transfer remains poorly understood. To open up the black box, we propose the SAE-based Transferability Score (STS), a new metric that leverages sparse autoencoders (SAEs) to forecast post-training transferability. Taking supervised fine-tuning as an example, STS identifies shifted dimensions in SAE representations and calculates their correlations with downstream domains, enabling reliable estimation of transferability \textit{before} fine-tuning. Extensive experiments across multiple models and domains show that STS accurately predicts the transferability of supervised fine-tuning, achieving Pearson correlation coefficients above 0.7 with actual performance changes. Beyond this, we take an initial step toward extending STS to reinforcement learning. We believe that STS can serve as an {\color{black} interpretable} tool for guiding post-training strategies in LLMs. Code is available at https://github.com/PKU-ML/STS.
ProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
Feb 02, 2026LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.
Autoregressive Models Rival Diffusion Models at ANY-ORDER Generation
Jan 19, 2026Diffusion language models enable any-order generation and bidirectional conditioning, offering appealing flexibility for tasks such as infilling, rewriting, and self-correction. However, their formulation-predicting one part of a sequence from another within a single-step dependency-limits modeling depth and often yields lower sample quality and stability than autoregressive (AR) models. To address this, we revisit autoregressive modeling as a foundation and reformulate diffusion-style training into a structured multi-group prediction process. We propose Any-order Any-subset Autoregressive modeling (A3), a generalized framework that extends the standard AR factorization to arbitrary token groups and generation orders. A3 preserves the probabilistic rigor and multi-layer dependency modeling of AR while inheriting diffusion models' flexibility for parallel and bidirectional generation. We implement A3 through a two-stream attention architecture and a progressive adaptation strategy that transitions pretrained AR models toward any-order prediction. Experiments on question answering, commonsense reasoning, and story infilling demonstrate that A3 outperforms diffusion-based models while maintaining flexible decoding. This work offers a unified approach for a flexible, efficient, and novel language modeling paradigm.
Leveraging Flatness to Improve Information-Theoretic Generalization Bounds for SGD
Jan 04, 2026Information-theoretic (IT) generalization bounds have been used to study the generalization of learning algorithms. These bounds are intrinsically data- and algorithm-dependent so that one can exploit the properties of data and algorithm to derive tighter bounds. However, we observe that although the flatness bias is crucial for SGD's generalization, these bounds fail to capture the improved generalization under better flatness and are also numerically loose. This is caused by the inadequate leverage of SGD's flatness bias in existing IT bounds. This paper derives a more flatness-leveraging IT bound for the flatness-favoring SGD. The bound indicates the learned models generalize better if the large-variance directions of the final weight covariance have small local curvatures in the loss landscape. Experiments on deep neural networks show our bound not only correctly reflects the better generalization when flatness is improved, but is also numerically much tighter. This is achieved by a flexible technique called "omniscient trajectory". When applied to Gradient Descent's minimax excess risk on convex-Lipschitz-Bounded problems, it improves representative IT bounds' $Ω(1)$ rates to $O(1/\sqrt{n})$. It also implies a by-pass of memorization-generalization trade-offs.
* Published as a conference paper at ICLR 2025
Recurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025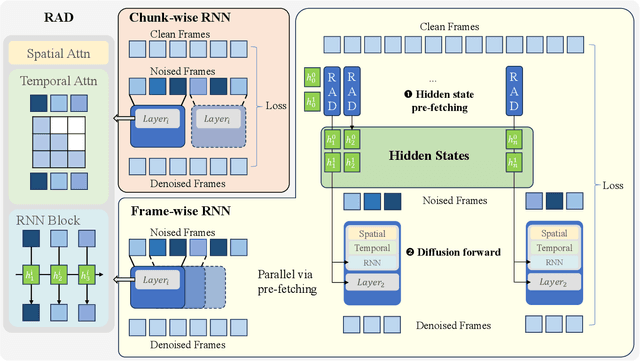
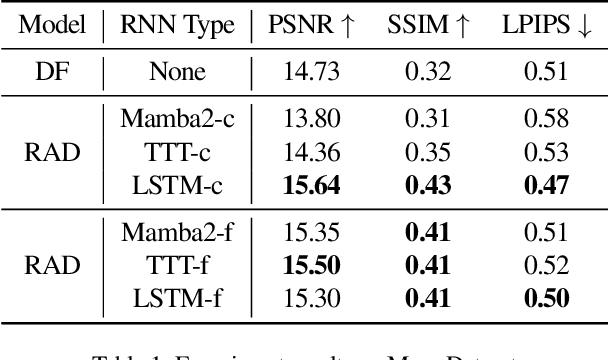
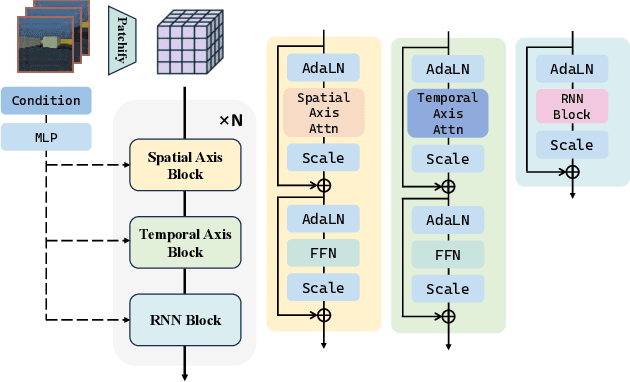
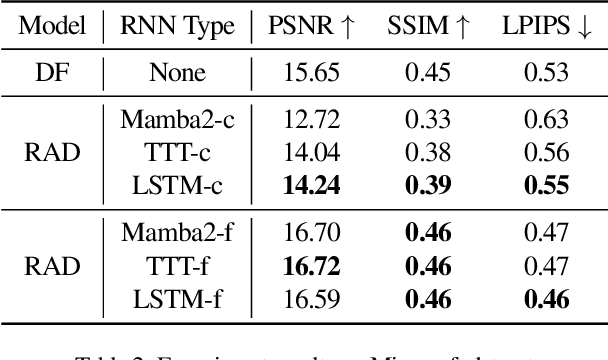
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
S-BEVLoc: BEV-based Self-supervised Framework for Large-scale LiDAR Global Localization
Sep 11, 2025LiDAR-based global localization is an essential component of simultaneous localization and mapping (SLAM), which helps loop closure and re-localization. Current approaches rely on ground-truth poses obtained from GPS or SLAM odometry to supervise network training. Despite the great success of these supervised approaches, substantial cost and effort are required for high-precision ground-truth pose acquisition. In this work, we propose S-BEVLoc, a novel self-supervised framework based on bird's-eye view (BEV) for LiDAR global localization, which eliminates the need for ground-truth poses and is highly scalable. We construct training triplets from single BEV images by leveraging the known geographic distances between keypoint-centered BEV patches. Convolutional neural network (CNN) is used to extract local features, and NetVLAD is employed to aggregate global descriptors. Moreover, we introduce SoftCos loss to enhance learning from the generated triplets. Experimental results on the large-scale KITTI and NCLT datasets show that S-BEVLoc achieves state-of-the-art performance in place recognition, loop closure, and global localization tasks, while offering scalability that would require extra effort for supervised approaches.
Long-Short Alignment for Effective Long-Context Modeling in LLMs
Jun 13, 2025Large language models (LLMs) have exhibited impressive performance and surprising emergent properties. However, their effectiveness remains limited by the fixed context window of the transformer architecture, posing challenges for long-context modeling. Among these challenges, length generalization -- the ability to generalize to sequences longer than those seen during training -- is a classical and fundamental problem. In this work, we propose a fresh perspective on length generalization, shifting the focus from the conventional emphasis on input features such as positional encodings or data structures to the output distribution of the model. Specifically, through case studies on synthetic tasks, we highlight the critical role of \textbf{long-short alignment} -- the consistency of output distributions across sequences of varying lengths. Extending this insight to natural language tasks, we propose a metric called Long-Short Misalignment to quantify this phenomenon, uncovering a strong correlation between the metric and length generalization performance. Building on these findings, we develop a regularization term that promotes long-short alignment during training. Extensive experiments validate the effectiveness of our approach, offering new insights for achieving more effective long-context modeling in LLMs. Code is available at https://github.com/PKU-ML/LongShortAlignment.
Identifying and Understanding Cross-Class Features in Adversarial Training
Jun 05, 2025Adversarial training (AT) has been considered one of the most effective methods for making deep neural networks robust against adversarial attacks, while the training mechanisms and dynamics of AT remain open research problems. In this paper, we present a novel perspective on studying AT through the lens of class-wise feature attribution. Specifically, we identify the impact of a key family of features on AT that are shared by multiple classes, which we call cross-class features. These features are typically useful for robust classification, which we offer theoretical evidence to illustrate through a synthetic data model. Through systematic studies across multiple model architectures and settings, we find that during the initial stage of AT, the model tends to learn more cross-class features until the best robustness checkpoint. As AT further squeezes the training robust loss and causes robust overfitting, the model tends to make decisions based on more class-specific features. Based on these discoveries, we further provide a unified view of two existing properties of AT, including the advantage of soft-label training and robust overfitting. Overall, these insights refine the current understanding of AT mechanisms and provide new perspectives on studying them. Our code is available at https://github.com/PKU-ML/Cross-Class-Features-AT.