 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Short Alignment for Effective Long-Context Modeling in LLMs
Jun 13, 2025Large language models (LLMs) have exhibited impressive performance and surprising emergent properties. However, their effectiveness remains limited by the fixed context window of the transformer architecture, posing challenges for long-context modeling. Among these challenges, length generalization -- the ability to generalize to sequences longer than those seen during training -- is a classical and fundamental problem. In this work, we propose a fresh perspective on length generalization, shifting the focus from the conventional emphasis on input features such as positional encodings or data structures to the output distribution of the model. Specifically, through case studies on synthetic tasks, we highlight the critical role of \textbf{long-short alignment} -- the consistency of output distributions across sequences of varying lengths. Extending this insight to natural language tasks, we propose a metric called Long-Short Misalignment to quantify this phenomenon, uncovering a strong correlation between the metric and length generalization performance. Building on these findings, we develop a regularization term that promotes long-short alignment during training. Extensive experiments validate the effectiveness of our approach, offering new insights for achieving more effective long-context modeling in LLMs. Code is available at https://github.com/PKU-ML/LongShortAlignment.
Synthetic Poisoning Attacks: The Impact of Poisoned MRI Image on U-Net Brain Tumor Segmentation
Feb 06, 2025Deep learning-based medical image segmentation models, such as U-Net, rely on high-quality annotated datasets to achieve accurate predictions. However, the increasing use of generative models for synthetic data augmentation introduces potential risks, particularly in the absence of rigorous quality control. In this paper, we investigate the impact of synthetic MRI data on the robustness and segmentation accuracy of U-Net models for brain tumor segmentation. Specifically, we generate synthetic T1-contrast-enhanced (T1-Ce) MRI scans using a GAN-based model with a shared encoding-decoding framework and shortest-path regularization. To quantify the effect of synthetic data contamination, we train U-Net models on progressively "poisoned" datasets, where synthetic data proportions range from 16.67% to 83.33%. Experimental results on a real MRI validation set reveal a significant performance degradation as synthetic data increases, with Dice coefficients dropping from 0.8937 (33.33% synthetic) to 0.7474 (83.33% synthetic). Accuracy and sensitivity exhibit similar downward trends, demonstrating the detrimental effect of synthetic data on segmentation robustness. These findings underscore the importance of quality control in synthetic data integration and highlight the risks of unregulated synthetic augmentation in medical image analysis. Our study provides critical insights for the development of more reliable and trustworthy AI-driven medical imaging systems.
SciSafeEval: A Comprehensive Benchmark for Safety Alignment of Large Language Models in Scientific Tasks
Oct 02, 2024



Large language models (LLMs) have had a transformative impact on a variety of scientific tasks across disciplines such as biology, chemistry, medicine, and physics. However, ensuring the safety alignment of these models in scientific research remains an underexplored area, with existing benchmarks primarily focus on textual content and overlooking key scientific representations such as molecular, protein, and genomic languages. Moreover, the safety mechanisms of LLMs in scientific tasks are insufficiently studied. To address these limitations, we introduce SciSafeEval, a comprehensive benchmark designed to evaluate the safety alignment of LLMs across a range of scientific tasks. SciSafeEval spans multiple scientific languages - including textual, molecular, protein, and genomic - and covers a wide range of scientific domains. We evaluate LLMs in zero-shot, few-shot and chain-of-thought settings, and introduce a 'jailbreak' enhancement feature that challenges LLMs equipped with safety guardrails, rigorously testing their defenses against malicious intention. Our benchmark surpasses existing safety datasets in both scale and scope, providing a robust platform for assessing the safety and performance of LLMs in scientific contexts. This work aims to facilitate the responsible development and deployment of LLMs, promoting alignment with safety and ethical standards in scientific research.
Look Ahead or Look Around? A Theoretical Comparison Between Autoregressive and Masked Pretraining
Jul 01, 2024

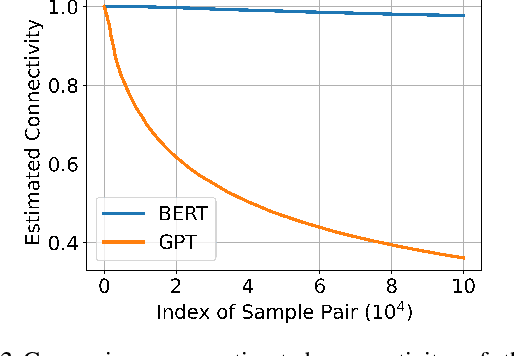

In recent years, the rise of generative self-supervised learning (SSL) paradigms has exhibited impressive performance across visual, language, and multi-modal domains. While the varied designs of generative SSL objectives lead to distinct properties in downstream tasks, a theoretical understanding of these differences remains largely unexplored. In this paper, we establish the first theoretical comparisons between two leading generative SSL paradigms: autoregressive SSL and masked SSL. Through establishing theoretical frameworks, we elucidate the strengths and limitations of autoregressive and masked SSL within the primary evaluation tasks of classification and content generation. Our findings demonstrate that in classification tasks, the flexibility of targeted tokens in masked SSL fosters more inter-sample connections compared to the fixed position of target tokens in autoregressive SSL, which yields superior clustering performance. In content generation tasks, the misalignment between the flexible lengths of test samples and the fixed length of unmasked texts in masked SSL (vs. flexible lengths of conditional texts in autoregressive SSL) hinders its generation performance. To leverage each other's strengths and mitigate weaknesses, we propose diversity-enhanced autoregressive and variable-length masked objectives, which substantially improve the classification performance of autoregressive SSL and the generation performance of masked SSL. Code is available at https://github.com/PKU-ML/LookAheadLookAround.