 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHACMatch Semi-Supervised Rotation Regression with Hardness-Aware Curriculum Pseudo Labeling
Mar 23, 2026Regressing 3D rotations of objects from 2D images is a crucial yet challenging task, with broad applications in autonomous driving, virtual reality, and robotic control. Existing rotation regression models often rely on large amounts of labeled data for training or require additional information beyond 2D images, such as point clouds or CAD models. Therefore, exploring semi-supervised rotation regression using only a limited number of labeled 2D images is highly valuable. While recent work FisherMatch introduces semi-supervised learning to rotation regression, it suffers from rigid entropy-based pseudo-label filtering that fails to effectively distinguish between reliable and unreliable unlabeled samples. To address this limitation, we propose a hardness-aware curriculum learning framework that dynamically selects pseudo-labeled samples based on their difficulty, progressing from easy to complex examples. We introduce both multi-stage and adaptive curriculum strategies to replace fixed-threshold filtering with more flexible, hardness-aware mechanisms. Additionally, we present a novel structured data augmentation strategy specifically tailored for rotation estimation, which assembles composite images from augmented patches to introduce feature diversity while preserving critical geometric integrity. Comprehensive experiments on PASCAL3D+ and ObjectNet3D demonstrate that our method outperforms existing supervised and semi-supervised baselines, particularly in low-data regimes, validating the effectiveness of our curriculum learning framework and structured augmentation approach.
* This is an accepted manuscript of an article published in Computer Vision and Image Understanding
TextResNet: Decoupling and Routing Optimization Signals in Compound AI Systems via Deep Residual Tuning
Feb 09, 2026Textual Gradient-style optimizers (TextGrad) enable gradient-like feedback propagation through compound AI systems. However, they do not work well for deep chains. The root cause of this limitation stems from the Semantic Entanglement problem in these extended workflows. In standard textual backpropagation, feedback signals mix local critiques with upstream contexts, leading to Attribution Ambiguity. To address this challenge, we propose TextResNet, a framework that reformulates the optimization process to achieve precise signal routing via four key innovations. Firstly, in the forward pass, it enforces Additive Semantic Deltas to preserve an Identity Highway for gradient flow. Secondly, in the backward pass, it introduces Semantic Gradient Decomposition via a Semantic Projector to disentangle feedback into causally independent subspaces. Thirdly, it implements Causal Routing, which routes projected signals to their specific components. Finally, it performs Density-Aware Optimization Scheduling to leverage the disentangled signals to dynamically allocate resources to key system bottlenecks. Our results show that TextResNet not only achieves superior performance compared to TextGrad, but also exhibits remarkable stability for agentic tasks in compound AI systems where baselines collapse. Code is available at https://github.com/JeanDiable/TextResNet.
OFA-MAS: One-for-All Multi-Agent System Topology Design based on Mixture-of-Experts Graph Generative Models
Jan 19, 2026Multi-Agent Systems (MAS) offer a powerful paradigm for solving complex problems, yet their performance is critically dependent on the design of their underlying collaboration topology. As MAS become increasingly deployed in web services (e.g., search engines), designing adaptive topologies for diverse cross-domain user queries becomes essential. Current graph learning-based design methodologies often adhere to a "one-for-one" paradigm, where a specialized model is trained for each specific task domain. This approach suffers from poor generalization to unseen domains and fails to leverage shared structural knowledge across different tasks. To address this, we propose OFA-TAD, a one-for-all framework that generates adaptive collaboration graphs for any task described in natural language through a single universal model. Our approach integrates a Task-Aware Graph State Encoder (TAGSE) that filters task-relevant node information via sparse gating, and a Mixture-of-Experts (MoE) architecture that dynamically selects specialized sub-networks to drive node and edge prediction. We employ a three-stage training strategy: unconditional pre-training on canonical topologies for structural priors, large-scale conditional pre-training on LLM-generated datasets for task-topology mappings, and supervised fine-tuning on empirically validated graphs. Experiments across six diverse benchmarks show that OFA-TAD significantly outperforms specialized one-for-one models, generating highly adaptive MAS topologies. Code: https://github.com/Shiy-Li/OFA-MAS.
MORE: Multi-Organ Medical Image REconstruction Dataset
Oct 30, 2025CT reconstruction provides radiologists with images for diagnosis and treatment, yet current deep learning methods are typically limited to specific anatomies and datasets, hindering generalization ability to unseen anatomies and lesions. To address this, we introduce the Multi-Organ medical image REconstruction (MORE) dataset, comprising CT scans across 9 diverse anatomies with 15 lesion types. This dataset serves two key purposes: (1) enabling robust training of deep learning models on extensive, heterogeneous data, and (2) facilitating rigorous evaluation of model generalization for CT reconstruction. We further establish a strong baseline solution that outperforms prior approaches under these challenging conditions. Our results demonstrate that: (1) a comprehensive dataset helps improve the generalization capability of models, and (2) optimization-based methods offer enhanced robustness for unseen anatomies. The MORE dataset is freely accessible under CC-BY-NC 4.0 at our project page https://more-med.github.io/
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
BECAME: BayEsian Continual Learning with Adaptive Model MErging
Apr 03, 2025Continual Learning (CL) strives to learn incrementally across tasks while mitigating catastrophic forgetting. A key challenge in CL is balancing stability (retaining prior knowledge) and plasticity (learning new tasks). While representative gradient projection methods ensure stability, they often limit plasticity. Model merging techniques offer promising solutions, but prior methods typically rely on empirical assumptions and carefully selected hyperparameters. In this paper, we explore the potential of model merging to enhance the stability-plasticity trade-off, providing theoretical insights that underscore its benefits. Specifically, we reformulate the merging mechanism using Bayesian continual learning principles and derive a closed-form solution for the optimal merging coefficient that adapts to the diverse characteristics of tasks. To validate our approach, we introduce a two-stage framework named BECAME, which synergizes the expertise of gradient projection and adaptive merging. Extensive experiments show that our approach outperforms state-of-the-art CL methods and existing merging strategies.
Machine Learning-Based Genomic Linguistic Analysis (Gene Sequence Feature Learning): A Case Study on Predicting Heavy Metal Response Genes in Rice
Mar 20, 2025This study explores the application of machine learning-based genetic linguistics for identifying heavy metal response genes in rice (Oryza sativa). By integrating convolutional neural networks and random forest algorithms, we developed a hybrid model capable of extracting and learning meaningful features from gene sequences, such as k-mer frequencies and physicochemical properties. The model was trained and tested on datasets of genes, achieving high predictive performance (precision: 0.89, F1-score: 0.82). RNA-seq and qRT-PCR experiments conducted on rice leaves which exposed to Hg0, revealed differential expression of genes associated with heavy metal responses, which validated the model's predictions. Co-expression network analysis identified 103 related genes, and a literature review indicated that these genes are highly likely to be involved in heavy metal-related biological processes. By integrating and comparing the analysis results with those of differentially expressed genes (DEGs), the validity of the new machine learning method was further demonstrated. This study highlights the efficacy of combining machine learning with genetic linguistics for large-scale gene prediction. It demonstrates a cost-effective and efficient approach for uncovering molecular mechanisms underlying heavy metal responses, with potential applications in developing stress-tolerant crop varieties.
Qwen2.5-1M Technical Report
Jan 26, 2025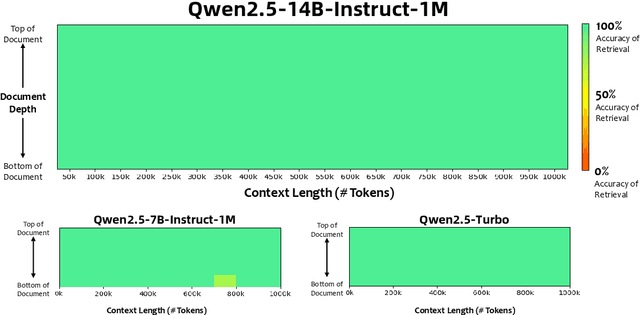

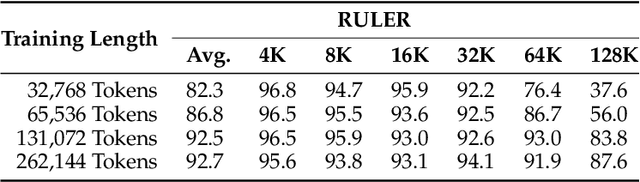
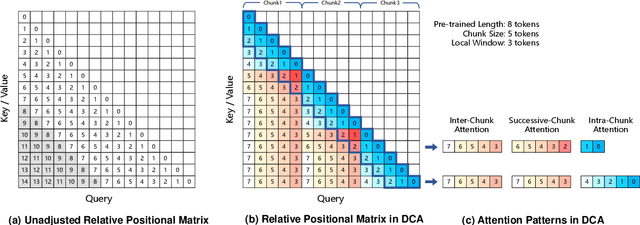
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Qwen2.5 Technical Report
Dec 19, 2024

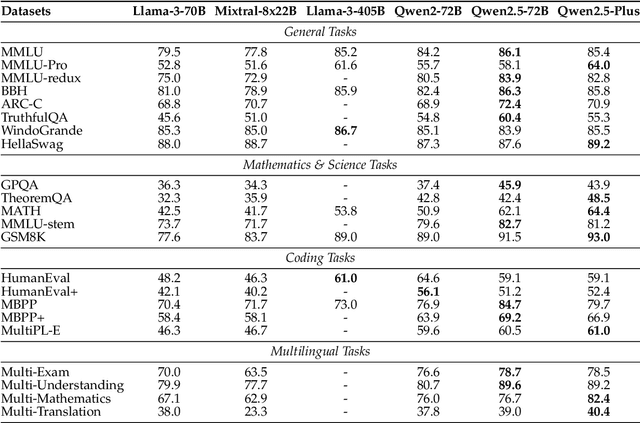
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
KAAE: Numerical Reasoning for Knowledge Graphs via Knowledge-aware Attributes Learning
Nov 20, 2024



Numerical reasoning is pivotal in various artificial intelligence applications, such as natural language processing and recommender systems, where it involves using entities, relations, and attribute values (e.g., weight, length) to infer new factual relations (e.g., the Nile is longer than the Amazon). However, existing approaches encounter two critical challenges in modeling: (1) semantic relevance-the challenge of insufficiently capturing the necessary contextual interactions among entities, relations, and numerical attributes, often resulting in suboptimal inference; and (2) semantic ambiguity-the difficulty in accurately distinguishing ordinal relationships during numerical reasoning, which compromises the generation of high-quality samples and limits the effectiveness of contrastive learning. To address these challenges, we propose the novel Knowledge-Aware Attributes Embedding model (KAAE) for knowledge graph embeddings in numerical reasoning. Specifically, to overcome the challenge of semantic relevance, we introduce a Mixture-of-Experts-Knowledge-Aware (MoEKA) Encoder, designed to integrate the semantics of entities, relations, and numerical attributes into a joint semantic space. To tackle semantic ambiguity, we implement a new ordinal knowledge contrastive learning (OKCL) strategy that generates high-quality ordinal samples from the original data with the aid of ordinal relations, capturing fine-grained semantic nuances essential for accurate numerical reasoning. Experiments on three public benchmark datasets demonstrate the superior performance of KAAE across various attribute value distributions.