 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches
Jan 20, 2026Recent advances in singing voice synthesis (SVS) have attracted substantial attention from both academia and industry. With the advent of large language models and novel generative paradigms, producing controllable, high-fidelity singing voices has become an attainable goal. Yet the field still lacks a comprehensive survey that systematically analyzes deep-learning-based singing voice synthesis systems and their enabling technologies. To address the aforementioned issue, this survey first categorizes existing systems by task type and then organizes current architectures into two major paradigms: cascaded and end-to-end approaches. Moreover, we provide an in-depth analysis of core technologies, covering singing modeling and control techniques. Finally, we review relevant datasets, annotation tools, and evaluation benchmarks that support training and assessment. In appendix, we introduce training strategies and further discussion of SVS. This survey provides an up-to-date review of the literature on SVS models, which would be a useful reference for both researchers and engineers. Related materials are available at https://github.com/David-Pigeon/SyntheticSingers.
ZEBRA: Towards Zero-Shot Cross-Subject Generalization for Universal Brain Visual Decoding
Oct 31, 2025Recent advances in neural decoding have enabled the reconstruction of visual experiences from brain activity, positioning fMRI-to-image reconstruction as a promising bridge between neuroscience and computer vision. However, current methods predominantly rely on subject-specific models or require subject-specific fine-tuning, limiting their scalability and real-world applicability. In this work, we introduce ZEBRA, the first zero-shot brain visual decoding framework that eliminates the need for subject-specific adaptation. ZEBRA is built on the key insight that fMRI representations can be decomposed into subject-related and semantic-related components. By leveraging adversarial training, our method explicitly disentangles these components to isolate subject-invariant, semantic-specific representations. This disentanglement allows ZEBRA to generalize to unseen subjects without any additional fMRI data or retraining. Extensive experiments show that ZEBRA significantly outperforms zero-shot baselines and achieves performance comparable to fully finetuned models on several metrics. Our work represents a scalable and practical step toward universal neural decoding. Code and model weights are available at: https://github.com/xmed-lab/ZEBRA.
Versatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.
Synthetic Poisoning Attacks: The Impact of Poisoned MRI Image on U-Net Brain Tumor Segmentation
Feb 06, 2025Deep learning-based medical image segmentation models, such as U-Net, rely on high-quality annotated datasets to achieve accurate predictions. However, the increasing use of generative models for synthetic data augmentation introduces potential risks, particularly in the absence of rigorous quality control. In this paper, we investigate the impact of synthetic MRI data on the robustness and segmentation accuracy of U-Net models for brain tumor segmentation. Specifically, we generate synthetic T1-contrast-enhanced (T1-Ce) MRI scans using a GAN-based model with a shared encoding-decoding framework and shortest-path regularization. To quantify the effect of synthetic data contamination, we train U-Net models on progressively "poisoned" datasets, where synthetic data proportions range from 16.67% to 83.33%. Experimental results on a real MRI validation set reveal a significant performance degradation as synthetic data increases, with Dice coefficients dropping from 0.8937 (33.33% synthetic) to 0.7474 (83.33% synthetic). Accuracy and sensitivity exhibit similar downward trends, demonstrating the detrimental effect of synthetic data on segmentation robustness. These findings underscore the importance of quality control in synthetic data integration and highlight the risks of unregulated synthetic augmentation in medical image analysis. Our study provides critical insights for the development of more reliable and trustworthy AI-driven medical imaging systems.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024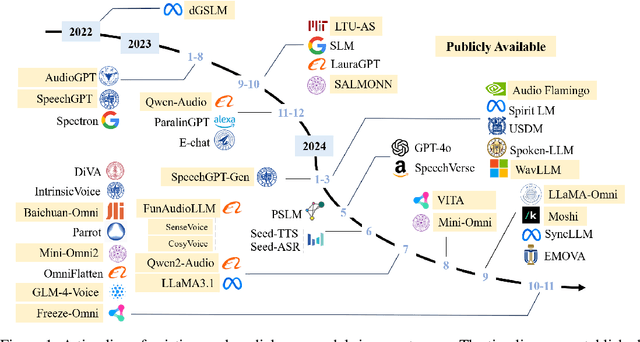

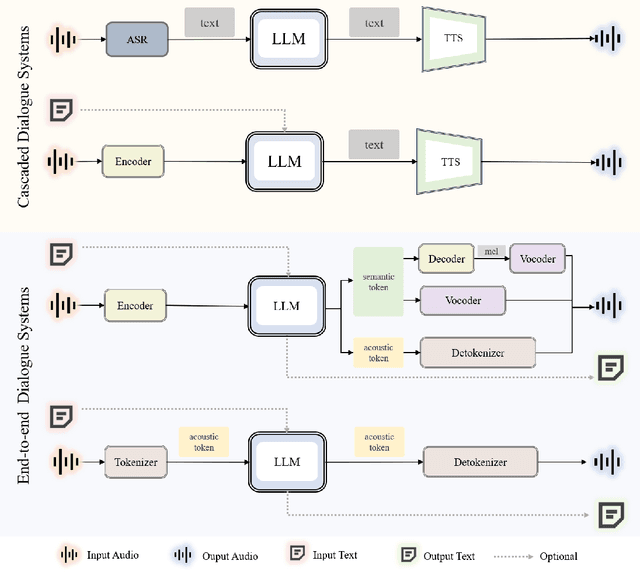
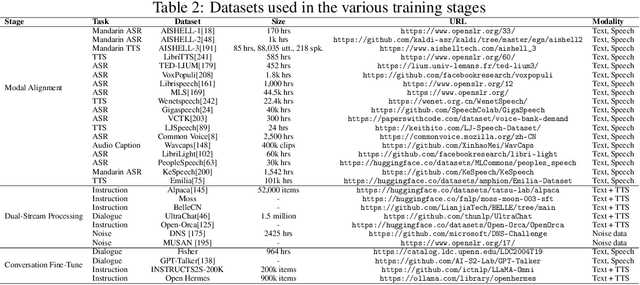
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
SciSafeEval: A Comprehensive Benchmark for Safety Alignment of Large Language Models in Scientific Tasks
Oct 02, 2024



Large language models (LLMs) have had a transformative impact on a variety of scientific tasks across disciplines such as biology, chemistry, medicine, and physics. However, ensuring the safety alignment of these models in scientific research remains an underexplored area, with existing benchmarks primarily focus on textual content and overlooking key scientific representations such as molecular, protein, and genomic languages. Moreover, the safety mechanisms of LLMs in scientific tasks are insufficiently studied. To address these limitations, we introduce SciSafeEval, a comprehensive benchmark designed to evaluate the safety alignment of LLMs across a range of scientific tasks. SciSafeEval spans multiple scientific languages - including textual, molecular, protein, and genomic - and covers a wide range of scientific domains. We evaluate LLMs in zero-shot, few-shot and chain-of-thought settings, and introduce a 'jailbreak' enhancement feature that challenges LLMs equipped with safety guardrails, rigorously testing their defenses against malicious intention. Our benchmark surpasses existing safety datasets in both scale and scope, providing a robust platform for assessing the safety and performance of LLMs in scientific contexts. This work aims to facilitate the responsible development and deployment of LLMs, promoting alignment with safety and ethical standards in scientific research.
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Sep 26, 2024



The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://gtsinger.github.io. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/GTSinger/GTSinger.
A Field-Theoretic Approach to Unlabeled Sensing
Mar 02, 2023We study the recent problem of unlabeled sensing from the information sciences in a field-theoretic framework. Our main result asserts that, for sufficiently generic data, the unique solution can be obtained by solving n + 1 polynomial equations in n unknowns.