 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Robot Policy Learning via Variational Neural Dynamics
Jun 25, 2026Robots deployed in the real world rarely operate under a single fixed dynamics model: wind changes, payloads vary, batteries drain, contacts shift, and hardware wears. Yet most learning-based controllers are trained once and deployed as if learning were complete. This prevents the robot from using deployment experience to further improve task performance. In this work, we propose a continual learning framework that uses real-world experience to improve robot policies under hidden and recurring dynamics. Our method learns a condition-aware dynamics model from real state-action trajectories by combining an analytical physics prior with a neural residual for unmodeled effects. A recurrent encoder infers the current hidden condition from recent interaction, and this estimate conditions both the residual model and the policy. Policy learning is performed via differentiable simulation using diverse learned dynamics sampled from the latent model. At deployment, these sampled conditions are replaced by conditions inferred online from recent real interaction, allowing the policy to recover recurring dynamics by recognition rather than residual re-fitting. Through extensive simulation studies and real-world experiments, we demonstrate that the framework improves policy performance under diverse unobserved disturbances. On real quadrotor trajectory tracking under changing wind, the policy recovers from recurring disturbances in roughly 1s, about 5x faster than online residual re-fitting. It also reduces large-disturbance hover and tracking errors by 65.7% and 53.3% over the state-of-the-art online adaptation approaches
Audio Editing in the Era of Foundation Models: A Survey
Jun 22, 2026Audio editing aims to modify a given synthetic or real-world audio signal to satisfy specific user needs. As a promising yet challenging direction in AIGC, it has attracted increasing attention. Recent advances in audio generation have made powerful generative models central to modern audio editing systems. This rapid progress has created a growing need to organize emerging tasks, methods, and resources into a coherent view. In this survey, we provide a comprehensive review of audio editing in the era of foundation models. We first present a unified taxonomy of existing editing tasks and then summarize the major foundation-model paradigms that support modern audio editing, covering representative approaches from both training-based and training-free perspectives. We further discuss related resources, including datasets, evaluation protocols, and data construction tools. Finally, we identify open challenges in this field and outline promising directions for future research. The project page is released at https://github.com/DaViD-Pigeon/AudioEditSurvey.
Spatial-Omni: Spatial Audio Understanding Integration in Multimodal LLMs via FOA Encoding
Jun 09, 2026Recent multimodal large language models mainly process audio as monaural signals, thereby discarding the spatial cues contained in spatial audio for sound localization, spatial relation reasoning, and spatial scene understanding. We propose Spatial-Omni, a lightweight method that implements SO-Encoder to inject First-Order Ambisonics (FOA) spatial audio into existing Omni LLMs as an independent modality, without modifying their original audio encoders. SO-Encoder provides spatial tokens with limited additional context cost and improves spatial audio understanding through efficient staged training. To support training and evaluation, we construct SO-Dataset, SO-QA, and SO-Bench from open-source data, real recordings, and simulations, containing 400K FOA spatial audio clips and 2.1M spatial question answering pairs. SO-Bench covers 16 spatial audio understanding subtasks, including basic detection and location estimation, spatial relation understanding, and complex spatial reasoning. Experiments show that Spatial-Omni outperforms existing open-source Large Audio-Language Models (LALMs) and Omni LLM models on spatial audio understanding tasks while retaining a reasonable level of general audio understanding. Code and data are available at https://github.com/dieKarotte/Spatial-Omni.
Comprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios
May 27, 2026Recent advances in speech generation have enabled high-fidelity synthesis, yet systematic evaluation of models under long-context conditions remains largely underexplored. A comprehensive evaluation benchmark for long-form speech is indispensable for two reasons: 1) existing test scenarios are often confined to limited domains, creating a significant gap with the diverse downstream applications; 2) existing metrics overlook critical long-text factors such as consistency and coherence, failing to generalize reliably. To this end, we propose Swanbench-Speech, a comprehensive benchmark that decomposes long-form speech quality into specific, disentangled dimensions. SwanBench-Speech has three key properties. 1) Rich speech scenarios: Focusing on long-form speech generation and dialog generation, SwanBench-Speech covers acoustics, semantics, and expressiveness challenges, and consists of 1,101 samples spanning 17 common speech scenarios; 2) Comprehensive evaluation dimensions: Along the acoustics, semantics, and expressiveness axes, SwanBench-Speech defines an automated evaluation protocol with seven metrics to provide a comprehensive, accurate, and standardized assessment; 3) Valuable Insights: Through extensive experiments, we reveal that current models still struggle in highly expressive scenarios and exhibit a notable gap in consistency and hierarchy compared to real recordings.
Cross-Modal Coreference Alignment: Enabling Reliable Information Transfer in Omni-LLMs
Apr 07, 2026Omni Large Language Models (Omni-LLMs) have demonstrated impressive capabilities in holistic multi-modal perception, yet they consistently falter in complex scenarios requiring synergistic omni-modal reasoning. Beyond understanding global multimodal context, effective reasoning also hinges on fine-grained cross-modal alignment, especially identifying shared referents across modalities, yet this aspect has been largely overlooked. To bridge this gap, we formalize the challenge as a cross-modal coreference problem, where a model must localize a referent in a source modality and re-identify it in a target modality. Building on this paradigm, we introduce CrossOmni, a dataset comprising nine tasks equipped with human-designed reasoning rationales to evaluate and enhance this capability. Experiments on 13 Omni-LLMs reveal systematic weaknesses in cross-modal coreference, which we attribute to the absence of coreference-aware thinking patterns. To address this, we enhance cross-modal alignment via two strategies: a training-free In-Context Learning method and a training-based SFT+GRPO framework designed to induce such thinking patterns. Both approaches yield substantial performance gains and generalize effectively to collaborative reasoning tasks. Overall, our findings highlight cross-modal coreference as a crucial missing piece for advancing robust omni-modal reasoning.
Learning Agile Quadrotor Flight in the Real World
Feb 10, 2026Learning-based controllers have achieved impressive performance in agile quadrotor flight but typically rely on massive training in simulation, necessitating accurate system identification for effective Sim2Real transfer. However, even with precise modeling, fixed policies remain susceptible to out-of-distribution scenarios, ranging from external aerodynamic disturbances to internal hardware degradation. To ensure safety under these evolving uncertainties, such controllers are forced to operate with conservative safety margins, inherently constraining their agility outside of controlled settings. While online adaptation offers a potential remedy, safely exploring physical limits remains a critical bottleneck due to data scarcity and safety risks. To bridge this gap, we propose a self-adaptive framework that eliminates the need for precise system identification or offline Sim2Real transfer. We introduce Adaptive Temporal Scaling (ATS) to actively explore platform physical limits, and employ online residual learning to augment a simple nominal model. {Based on the learned hybrid model, we further propose Real-world Anchored Short-horizon Backpropagation Through Time (RASH-BPTT) to achieve efficient and robust in-flight policy updates. Extensive experiments demonstrate that our quadrotor reliably executes agile maneuvers near actuator saturation limits. The system evolves a conservative base policy with a peak speed of 1.9 m/s to 7.3 m/s within approximately 100 seconds of flight time. These findings underscore that real-world adaptation serves not merely to compensate for modeling errors, but as a practical mechanism for sustained performance improvement in aggressive flight regimes.
Synthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches
Jan 20, 2026Recent advances in singing voice synthesis (SVS) have attracted substantial attention from both academia and industry. With the advent of large language models and novel generative paradigms, producing controllable, high-fidelity singing voices has become an attainable goal. Yet the field still lacks a comprehensive survey that systematically analyzes deep-learning-based singing voice synthesis systems and their enabling technologies. To address the aforementioned issue, this survey first categorizes existing systems by task type and then organizes current architectures into two major paradigms: cascaded and end-to-end approaches. Moreover, we provide an in-depth analysis of core technologies, covering singing modeling and control techniques. Finally, we review relevant datasets, annotation tools, and evaluation benchmarks that support training and assessment. In appendix, we introduce training strategies and further discussion of SVS. This survey provides an up-to-date review of the literature on SVS models, which would be a useful reference for both researchers and engineers. Related materials are available at https://github.com/David-Pigeon/SyntheticSingers.
STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation
Jul 09, 2025Recent breakthroughs in singing voice synthesis (SVS) have heightened the demand for high-quality annotated datasets, yet manual annotation remains prohibitively labor-intensive and resource-intensive. Existing automatic singing annotation (ASA) methods, however, primarily tackle isolated aspects of the annotation pipeline. To address this fundamental challenge, we present STARS, which is, to our knowledge, the first unified framework that simultaneously addresses singing transcription, alignment, and refined style annotation. Our framework delivers comprehensive multi-level annotations encompassing: (1) precise phoneme-audio alignment, (2) robust note transcription and temporal localization, (3) expressive vocal technique identification, and (4) global stylistic characterization including emotion and pace. The proposed architecture employs hierarchical acoustic feature processing across frame, word, phoneme, note, and sentence levels. The novel non-autoregressive local acoustic encoders enable structured hierarchical representation learning. Experimental validation confirms the framework's superior performance across multiple evaluation dimensions compared to existing annotation approaches. Furthermore, applications in SVS training demonstrate that models utilizing STARS-annotated data achieve significantly enhanced perceptual naturalness and precise style control. This work not only overcomes critical scalability challenges in the creation of singing datasets but also pioneers new methodologies for controllable singing voice synthesis. Audio samples are available at https://gwx314.github.io/stars-demo/.
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
May 20, 2025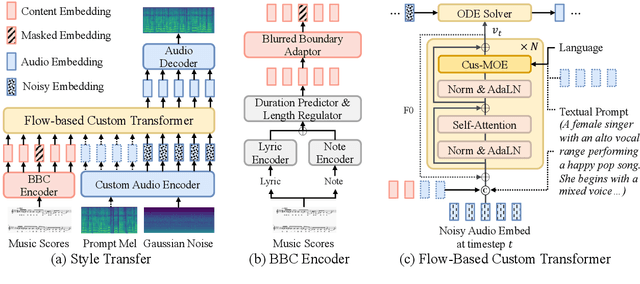
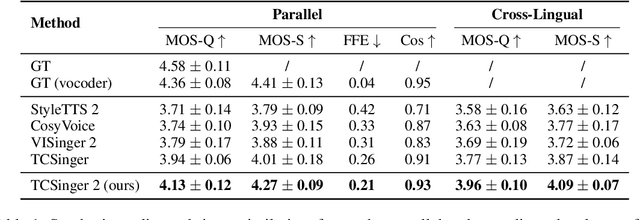
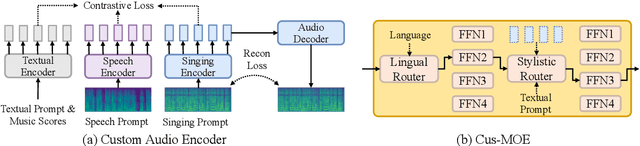
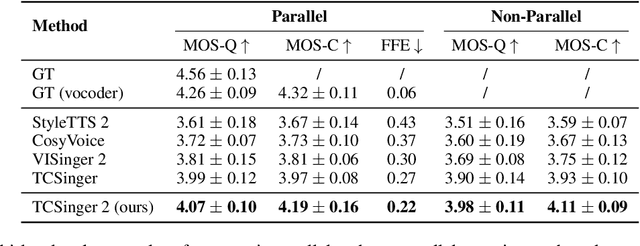
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks.
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Apr 29, 2025Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts, with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs, with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges. We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting. ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning, considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts. 2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control. We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics. The demos and dataset are available at https://aaronz345.github.io/ISDramaDemo.