 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRed-OCR Technical Report
Mar 02, 2026We present FireRed-OCR, a systematic framework to specialize general VLMs into high-performance OCR models. Large Vision-Language Models (VLMs) have demonstrated impressive general capabilities but frequently suffer from ``structural hallucination'' when processing complex documents, limiting their utility in industrial OCR applications. In this paper, we introduce FireRed-OCR, a novel framework designed to transform general-purpose VLMs (based on Qwen3-VL) into pixel-precise structural document parsing experts. To address the scarcity of high-quality structured data, we construct a ``Geometry + Semantics'' Data Factory. Unlike traditional random sampling, our pipeline leverages geometric feature clustering and multi-dimensional tagging to synthesize and curate a highly balanced dataset, effectively handling long-tail layouts and rare document types. Furthermore, we propose a Three-Stage Progressive Training strategy that guides the model from pixel-level perception to logical structure generation. This curriculum includes: (1) Multi-task Pre-alignment to ground the model's understanding of document structure; (2) Specialized SFT for standardizing full-image Markdown output; and (3) Format-Constrained Group Relative Policy Optimization (GRPO), which utilizes reinforcement learning to enforce strict syntactic validity and structural integrity (e.g., table closure, formula syntax). Extensive evaluations on OmniDocBench v1.5 demonstrate that FireRed-OCR achieves state-of-the-art performance with an overall score of 92.94\%, significantly outperforming strong baselines such as DeepSeek-OCR 2 and OCRVerse across text, formula, table, and reading order metrics. We open-source our code and model weights to facilitate the ``General VLM to Specialized Structural Expert'' paradigm.
FireRed-Image-Edit-1.0 Techinical Report
Feb 12, 2026We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
Improving Flow Matching by Aligning Flow Divergence
Jan 31, 2026Conditional flow matching (CFM) stands out as an efficient, simulation-free approach for training flow-based generative models, achieving remarkable performance for data generation. However, CFM is insufficient to ensure accuracy in learning probability paths. In this paper, we introduce a new partial differential equation characterization for the error between the learned and exact probability paths, along with its solution. We show that the total variation gap between the two probability paths is bounded above by a combination of the CFM loss and an associated divergence loss. This theoretical insight leads to the design of a new objective function that simultaneously matches the flow and its divergence. Our new approach improves the performance of the flow-based generative model by a noticeable margin without sacrificing generation efficiency. We showcase the advantages of this enhanced training approach over CFM on several important benchmark tasks, including generative modeling for dynamical systems, DNA sequences, and videos. Code is available at \href{https://github.com/Utah-Math-Data-Science/Flow_Div_Matching}{Utah-Math-Data-Science}.
RMFlow: Refined Mean Flow by a Noise-Injection Step for Multimodal Generation
Jan 31, 2026Mean flow (MeanFlow) enables efficient, high-fidelity image generation, yet its single-function evaluation (1-NFE) generation often cannot yield compelling results. We address this issue by introducing RMFlow, an efficient multimodal generative model that integrates a coarse 1-NFE MeanFlow transport with a subsequent tailored noise-injection refinement step. RMFlow approximates the average velocity of the flow path using a neural network trained with a new loss function that balances minimizing the Wasserstein distance between probability paths and maximizing sample likelihood. RMFlow achieves near state-of-the-art results on text-to-image, context-to-molecule, and time-series generation using only 1-NFE, at a computational cost comparable to the baseline MeanFlows.
Towards Multiscale Graph-based Protein Learning with Geometric Secondary Structural Motifs
Jan 31, 2026Graph neural networks (GNNs) have emerged as powerful tools for learning protein structures by capturing spatial relationships at the residue level. However, existing GNN-based methods often face challenges in learning multiscale representations and modeling long-range dependencies efficiently. In this work, we propose an efficient multiscale graph-based learning framework tailored to proteins. Our proposed framework contains two crucial components: (1) It constructs a hierarchical graph representation comprising a collection of fine-grained subgraphs, each corresponding to a secondary structure motif (e.g., $α$-helices, $β$-strands, loops), and a single coarse-grained graph that connects these motifs based on their spatial arrangement and relative orientation. (2) It employs two GNNs for feature learning: the first operates within individual secondary motifs to capture local interactions, and the second models higher-level structural relationships across motifs. Our modular framework allows a flexible choice of GNN in each stage. Theoretically, we show that our hierarchical framework preserves the desired maximal expressiveness, ensuring no loss of critical structural information. Empirically, we demonstrate that integrating baseline GNNs into our multiscale framework remarkably improves prediction accuracy and reduces computational cost across various benchmarks.
ChatAD: Reasoning-Enhanced Time-Series Anomaly Detection with Multi-Turn Instruction Evolution
Jan 20, 2026LLM-driven Anomaly Detection (AD) helps enhance the understanding and explanatory abilities of anomalous behaviors in Time Series (TS). Existing methods face challenges of inadequate reasoning ability, deficient multi-turn dialogue capability, and narrow generalization. To this end, we 1) propose a multi-agent-based TS Evolution algorithm named TSEvol. On top of it, we 2) introduce the AD reasoning and multi-turn dialogue Dataset TSEData-20K and contribute the Chatbot family for AD, including ChatAD-Llama3-8B, Qwen2.5-7B, and Mistral-7B. Furthermore, 3) we propose the TS Kahneman-Tversky Optimization (TKTO) to enhance ChatAD's cross-task generalization capability. Lastly, 4) we propose a LLM-driven Learning-based AD Benchmark LLADBench to evaluate the performance of ChatAD and nine baselines across seven datasets and tasks. Our three ChatAD models achieve substantial gains, up to 34.50% in accuracy, 34.71% in F1, and a 37.42% reduction in false positives. Besides, via KTKO, our optimized ChatAD achieves competitive performance in reasoning and cross-task generalization on classification, forecasting, and imputation.
Subtyping Breast Lesions via Generative Augmentation based Long-tailed Recognition in Ultrasound
Jul 30, 2025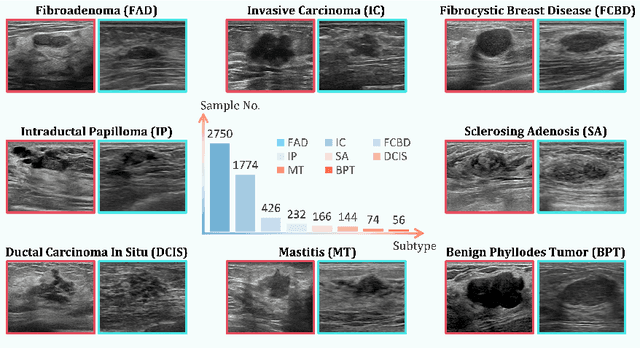
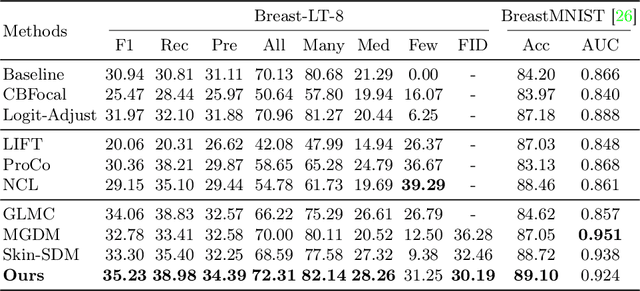
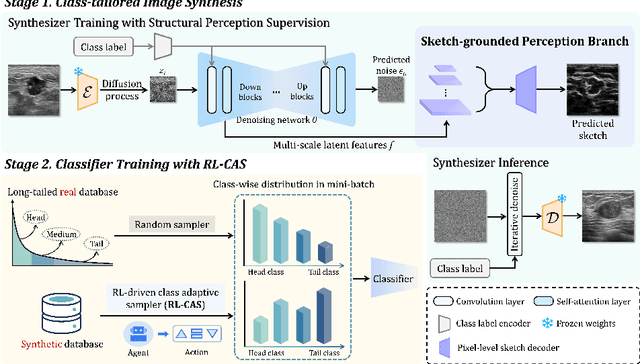
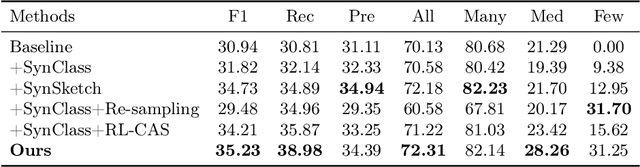
Accurate identification of breast lesion subtypes can facilitate personalized treatment and interventions. Ultrasound (US), as a safe and accessible imaging modality, is extensively employed in breast abnormality screening and diagnosis. However, the incidence of different subtypes exhibits a skewed long-tailed distribution, posing significant challenges for automated recognition. Generative augmentation provides a promising solution to rectify data distribution. Inspired by this, we propose a dual-phase framework for long-tailed classification that mitigates distributional bias through high-fidelity data synthesis while avoiding overuse that corrupts holistic performance. The framework incorporates a reinforcement learning-driven adaptive sampler, dynamically calibrating synthetic-real data ratios by training a strategic multi-agent to compensate for scarcities of real data while ensuring stable discriminative capability. Furthermore, our class-controllable synthetic network integrates a sketch-grounded perception branch that harnesses anatomical priors to maintain distinctive class features while enabling annotation-free inference. Extensive experiments on an in-house long-tailed and a public imbalanced breast US datasets demonstrate that our method achieves promising performance compared to state-of-the-art approaches. More synthetic images can be found at https://github.com/Stinalalala/Breast-LT-GenAug.
Medical-Knowledge Driven Multiple Instance Learning for Classifying Severe Abdominal Anomalies on Prenatal Ultrasound
Jul 02, 2025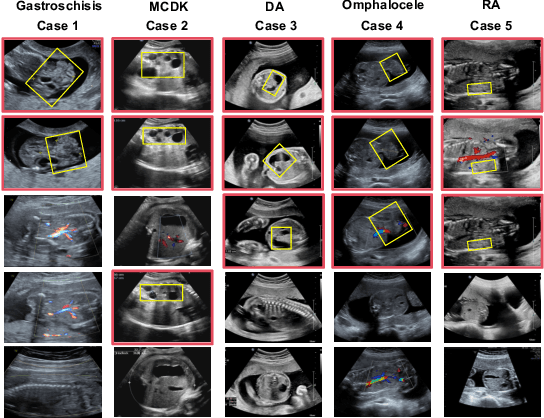
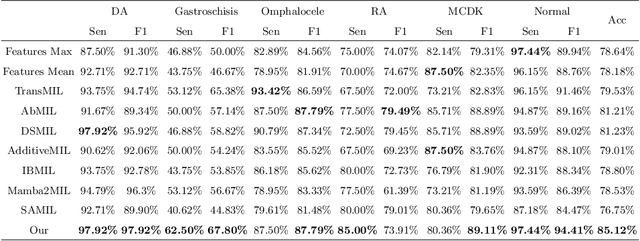
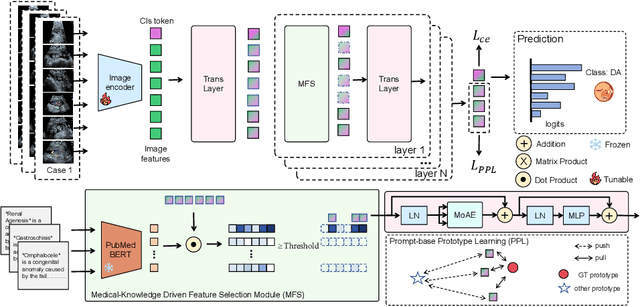

Fetal abdominal malformations are serious congenital anomalies that require accurate diagnosis to guide pregnancy management and reduce mortality. Although AI has demonstrated significant potential in medical diagnosis, its application to prenatal abdominal anomalies remains limited. Most existing studies focus on image-level classification and rely on standard plane localization, placing less emphasis on case-level diagnosis. In this paper, we develop a case-level multiple instance learning (MIL)-based method, free of standard plane localization, for classifying fetal abdominal anomalies in prenatal ultrasound. Our contribution is three-fold. First, we adopt a mixture-of-attention-experts module (MoAE) to weight different attention heads for various planes. Secondly, we propose a medical-knowledge-driven feature selection module (MFS) to align image features with medical knowledge, performing self-supervised image token selection at the case-level. Finally, we propose a prompt-based prototype learning (PPL) to enhance the MFS. Extensively validated on a large prenatal abdominal ultrasound dataset containing 2,419 cases, with a total of 24,748 images and 6 categories, our proposed method outperforms the state-of-the-art competitors. Codes are available at:https://github.com/LL-AC/AAcls.
TarDiff: Target-Oriented Diffusion Guidance for Synthetic Electronic Health Record Time Series Generation
Apr 24, 2025Synthetic Electronic Health Record (EHR) time-series generation is crucial for advancing clinical machine learning models, as it helps address data scarcity by providing more training data. However, most existing approaches focus primarily on replicating statistical distributions and temporal dependencies of real-world data. We argue that fidelity to observed data alone does not guarantee better model performance, as common patterns may dominate, limiting the representation of rare but important conditions. This highlights the need for generate synthetic samples to improve performance of specific clinical models to fulfill their target outcomes. To address this, we propose TarDiff, a novel target-oriented diffusion framework that integrates task-specific influence guidance into the synthetic data generation process. Unlike conventional approaches that mimic training data distributions, TarDiff optimizes synthetic samples by quantifying their expected contribution to improving downstream model performance through influence functions. Specifically, we measure the reduction in task-specific loss induced by synthetic samples and embed this influence gradient into the reverse diffusion process, thereby steering the generation towards utility-optimized data. Evaluated on six publicly available EHR datasets, TarDiff achieves state-of-the-art performance, outperforming existing methods by up to 20.4% in AUPRC and 18.4% in AUROC. Our results demonstrate that TarDiff not only preserves temporal fidelity but also enhances downstream model performance, offering a robust solution to data scarcity and class imbalance in healthcare analytics.
Flip Learning: Weakly Supervised Erase to Segment Nodules in Breast Ultrasound
Mar 27, 2025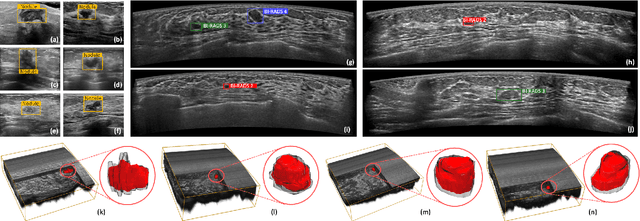
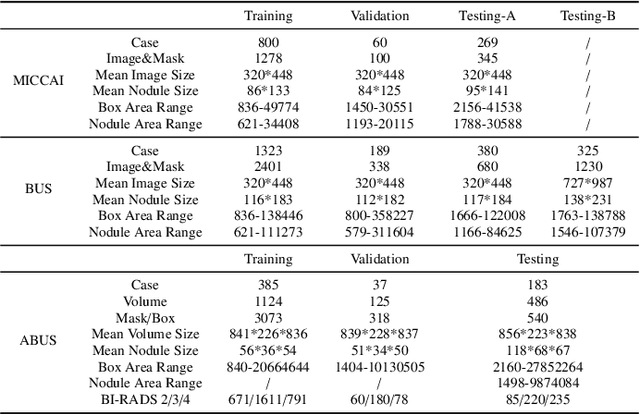
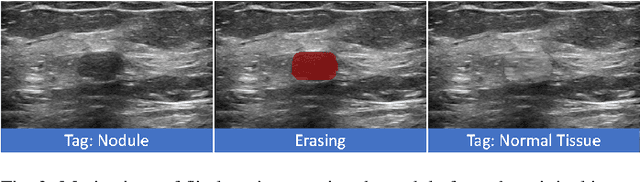
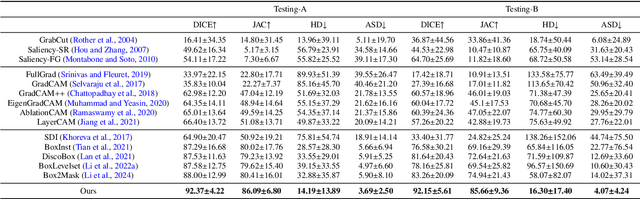
Accurate segmentation of nodules in both 2D breast ultrasound (BUS) and 3D automated breast ultrasound (ABUS) is crucial for clinical diagnosis and treatment planning. Therefore, developing an automated system for nodule segmentation can enhance user independence and expedite clinical analysis. Unlike fully-supervised learning, weakly-supervised segmentation (WSS) can streamline the laborious and intricate annotation process. However, current WSS methods face challenges in achieving precise nodule segmentation, as many of them depend on inaccurate activation maps or inefficient pseudo-mask generation algorithms. In this study, we introduce a novel multi-agent reinforcement learning-based WSS framework called Flip Learning, which relies solely on 2D/3D boxes for accurate segmentation. Specifically, multiple agents are employed to erase the target from the box to facilitate classification tag flipping, with the erased region serving as the predicted segmentation mask. The key contributions of this research are as follows: (1) Adoption of a superpixel/supervoxel-based approach to encode the standardized environment, capturing boundary priors and expediting the learning process. (2) Introduction of three meticulously designed rewards, comprising a classification score reward and two intensity distribution rewards, to steer the agents' erasing process precisely, thereby avoiding both under- and over-segmentation. (3) Implementation of a progressive curriculum learning strategy to enable agents to interact with the environment in a progressively challenging manner, thereby enhancing learning efficiency. Extensively validated on the large in-house BUS and ABUS datasets, our Flip Learning method outperforms state-of-the-art WSS methods and foundation models, and achieves comparable performance as fully-supervised learning algorithms.