 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPA-AD: A Two-Stage Pseudo Anomaly-Guided Method for Bearing Time-Series Anomaly Detection
Jun 02, 2026This paper proposes a two-stage pseudo anomaly-guided anomaly detection method (\textbf{T}wo-stage \textbf{P}seudo \textbf{A}nomaly-guided \textbf{A}nomaly \textbf{D}etection, \textbf{TPA-AD}) for axle-box bearing time-series anomaly detection (time series anomaly detection, TSAD) under the setting where only normal samples are available for training. The method first generates pseudo-anomalous windows near the normal boundary using a reconstruction model and per-feature target-error control. It then learns anomaly-sensitive representations through contrastive learning between normal and pseudo-anomalous windows, and finally produces window-level and point-level anomaly scores using k-nearest neighbors (KNN). Compared with existing methods that rely on known fault categories, real anomaly priors, or random anomaly injection, TPA-AD improves the separability of the normal boundary by constructing pseudo-anomalies in boundary neighborhoods and can jointly handle continuous and discrete features in mixed-variable scenarios. The main experiments are conducted on bearing fault detection datasets and degradation-process datasets, with an additional exploratory extension on $13$ public TSAD datasets. The results show that the proposed method yields relatively stable anomaly responses, is sensitive to degradation evolution, and demonstrates a certain degree of broader applicability on public TSAD benchmarks and real high-speed-train-related bearing data.
Building Low-Altitude Communication Networks: A Digital Twin-Based Optimization Framework
Apr 20, 2026Low-altitude communication networks (LACNs) serve as the critical infrastructure of the emerging low-altitude economy (LAE), supporting services such as drone delivery and infrastructure inspection. However, LACNs operate in highly dynamic three-dimensional (3D) environments characterized by high mobility and predominantly line-of-sight (LoS) propagation, creating strong coupling among key performance objectives including coverage, interference mitigation, handover management, and sensing capability. Isolated tuning of individual objectives cannot capture these cross-objective interactions, rendering conventional approaches based on experience-driven tuning and repeated field trials inefficient and costly. To address these challenges, we propose DT-MOO, a Digital Twin-based Multi-Objective Optimization framework for LACNs. By constructing a high-fidelity virtual replica that integrates realistic environmental models, electromagnetic (EM) propagation, and traffic dynamics within a unified environment, DT-MOO enables joint evaluation and systematic optimization of interdependent network parameters, scoring candidate configurations by their combined effect on multiple objectives. As the foundational validation of the framework, we report real-world experiments in a 5G-enabled LACN focusing on coverage-interference co-optimization, where DT-MOO increases the high-quality coverage rate from 14.0% to 52.9% across all evaluated altitudes compared to an operator-provisioned, experience-based baseline, while achieving a net SINR gain under stringent criteria despite local spatial trade-offs, confirming its ability to handle coupled objectives in practical LACN deployment.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
PeroMAS: A Multi-agent System of Perovskite Material Discovery
Feb 10, 2026As a pioneer of the third-generation photovoltaic revolution, Perovskite Solar Cells (PSCs) are renowned for their superior optoelectronic performance and cost potential. The development process of PSCs is precise and complex, involving a series of closed-loop workflows such as literature retrieval, data integration, experimental design, and synthesis. However, existing AI perovskite approaches focus predominantly on discrete models, including material design, process optimization,and property prediction. These models fail to propagate physical constraints across the workflow, hindering end-to-end optimization. In this paper, we propose a multi-agent system for perovskite material discovery, named PeroMAS. We first encapsulated a series of perovskite-specific tools into Model Context Protocols (MCPs). By planning and invoking these tools, PeroMAS can design perovskite materials under multi-objective constraints, covering the entire process from literature retrieval and data extraction to property prediction and mechanism analysis. Furthermore, we construct an evaluation benchmark by perovskite human experts to assess this multi-agent system. Results demonstrate that, compared to single Large Language Model (LLM) or traditional search strategies, our system significantly enhances discovery efficiency. It successfully identified candidate materials satisfying multi-objective constraints. Notably, we verify PeroMAS's effectiveness in the physical world through real synthesis experiments.
CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
Automatic Neuronal Activity Segmentation in Fast Four Dimensional Spatio-Temporal Fluorescence Imaging using Bayesian Approach
Dec 22, 2025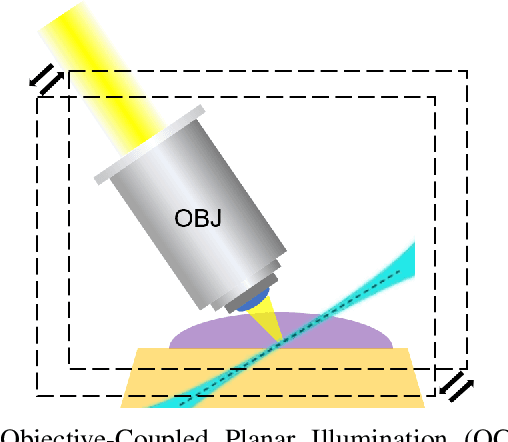
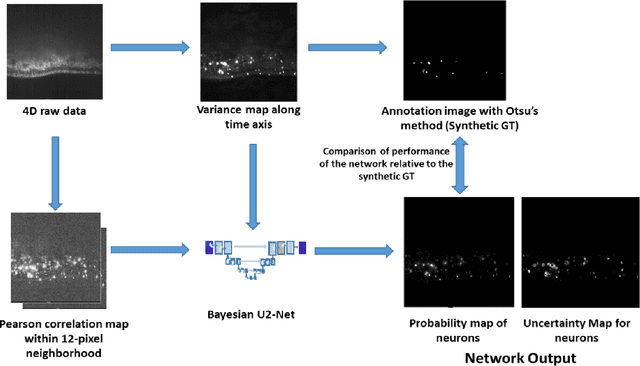
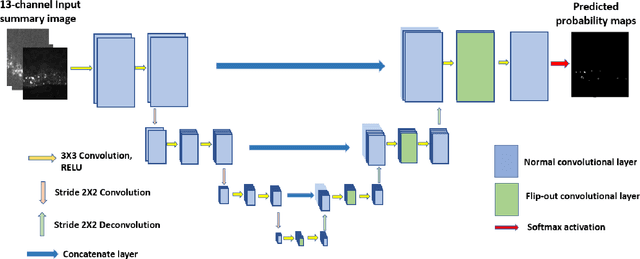
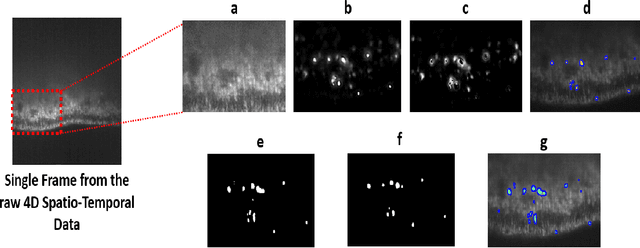
Fluorescence Microcopy Calcium Imaging is a fundamental tool to in-vivo record and analyze large scale neuronal activities simultaneously at a single cell resolution. Automatic and precise detection of behaviorally relevant neuron activity from the recordings is critical to study the mapping of brain activity in organisms. However a perpetual bottleneck to this problem is the manual segmentation which is time and labor intensive and lacks generalizability. To this end, we present a Bayesian Deep Learning Framework to detect neuronal activities in 4D spatio-temporal data obtained by light sheet microscopy. Our approach accounts for the use of temporal information by calculating pixel wise correlation maps and combines it with spatial information given by the mean summary image. The Bayesian framework not only produces probability segmentation maps but also models the uncertainty pertaining to active neuron detection. To evaluate the accuracy of our framework we implemented the test of reproducibility to assert the generalization of the network to detect neuron activity. The network achieved a mean Dice Score of 0.81 relative to the synthetic Ground Truth obtained by Otsu's method and a mean Dice Score of 0.79 between the first and second run for test of reproducibility. Our method successfully deployed can be used for rapid detection of active neuronal activities for behavioural studies.
Near-Field Beam Training Through Beam Diverging
Sep 19, 2025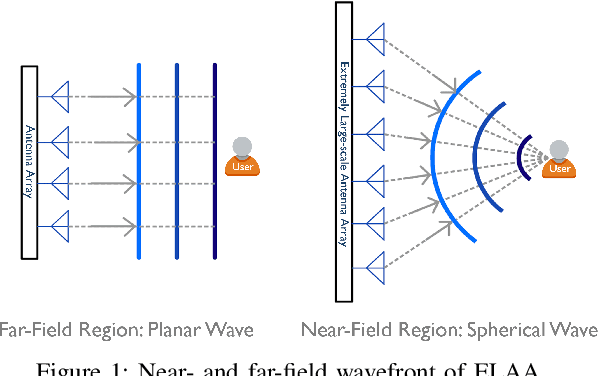
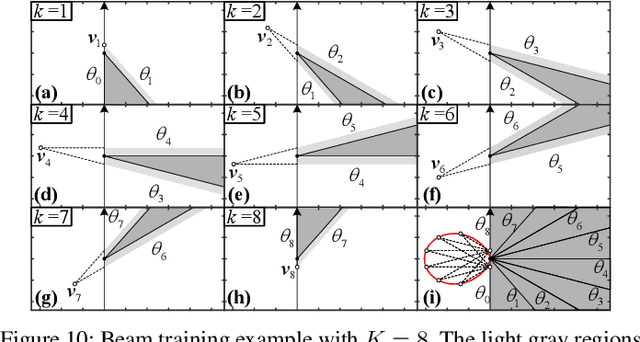
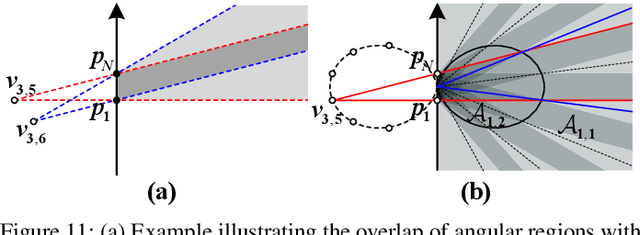
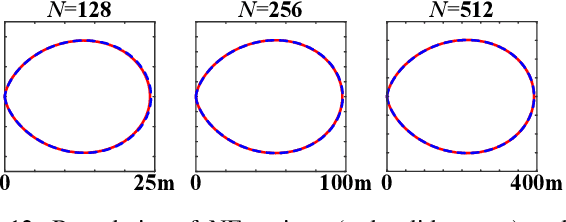
This paper investigates beam training techniques for near-field (NF) extremely large-scale antenna arrays (ELAAs). Existing NF beam training methods predominantly rely on beam focusing, where the base station (BS) transmits highly spatially selective beams to locate the user equipment (UE). However, these beam-focusing-based schemes suffer from both high beam sweeping overhead and limited accuracy in the NF, primarily due to the narrow beams' high susceptibility to misalignment. To address this, we propose a novel NF beam training paradigm using diverging beams. Specifically, we introduce the beam diverging effect and exploit it for low-overhead, high-accuracy beam training. First, we design a diverging codeword to induce the beam diverging effect with a single radio frequency (RF) chain. Next, we develop a diverging polar-domain codebook (DPC) along with a hierarchical method that enables angular-domain localization of the UE with only 2 log_2(N) pilots, where N denotes the number of antennas. Finally, we enhance beam training performance through two additional techniques: a DPC angular range reduction strategy to improve the effectiveness of beam diverging, and a pilot set expansion method to increase overall beam training accuracy. Numerical results show that our algorithm achieves near-optimal accuracy with a small pilot overhead, outperforming existing methods.
3D Near-Field Beam Training for Uniform Planar Arrays through Beam Diverging
Sep 19, 2025In future 6G communication systems, large-scale antenna arrays promise enhanced signal strength and spatial resolution, but they also increase the complexity of beam training. Moreover, as antenna counts grow and carrier wavelengths shrink, the channel model transits from far-field (FF) planar waves to near-field (NF) spherical waves, further complicating the beam training process. This paper focuses on millimeter-wave (mmWave) systems equipped with large-scale uniform planar arrays (UPAs), which produce 3D beam patterns and introduce additional challenges for NF beam training. Existing methods primarily rely on either FF steering or NF focusing codewords, both of which are highly sensitive to mismatches in user equipment (UE) location, leading to high sensitivity to even slight mismatch and excessive training overhead. In contrast, we introduce a novel beam training approach leveraging the beam-diverging effect, which enables adjustable wide-beam coverage using only a single radio frequency (RF) chain. Specifically, we first analyze the spatial characteristics of this effect in UPA systems and leverage them to construct hierarchical codebooks for coarse UE localization. Then, we develop a 3D sampling mechanism to build an NF refinement codebook for precise beam training. Numerical results demonstrate that the proposed algorithm achieves superior beam training performance while maintaining low training overhead.
Medical-Knowledge Driven Multiple Instance Learning for Classifying Severe Abdominal Anomalies on Prenatal Ultrasound
Jul 02, 2025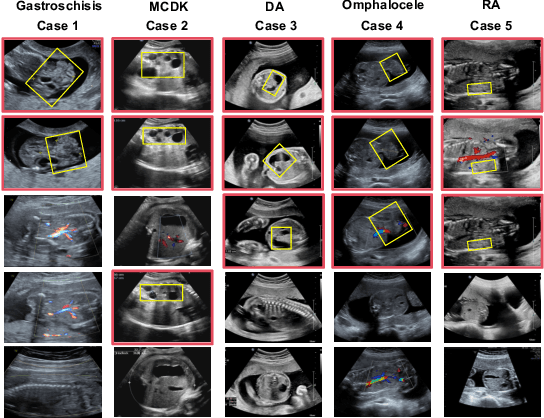
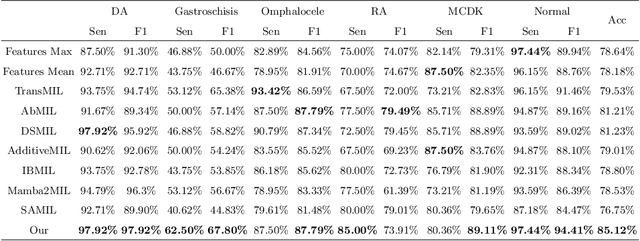
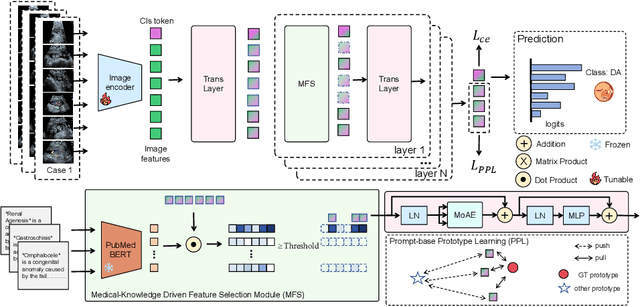

Fetal abdominal malformations are serious congenital anomalies that require accurate diagnosis to guide pregnancy management and reduce mortality. Although AI has demonstrated significant potential in medical diagnosis, its application to prenatal abdominal anomalies remains limited. Most existing studies focus on image-level classification and rely on standard plane localization, placing less emphasis on case-level diagnosis. In this paper, we develop a case-level multiple instance learning (MIL)-based method, free of standard plane localization, for classifying fetal abdominal anomalies in prenatal ultrasound. Our contribution is three-fold. First, we adopt a mixture-of-attention-experts module (MoAE) to weight different attention heads for various planes. Secondly, we propose a medical-knowledge-driven feature selection module (MFS) to align image features with medical knowledge, performing self-supervised image token selection at the case-level. Finally, we propose a prompt-based prototype learning (PPL) to enhance the MFS. Extensively validated on a large prenatal abdominal ultrasound dataset containing 2,419 cases, with a total of 24,748 images and 6 categories, our proposed method outperforms the state-of-the-art competitors. Codes are available at:https://github.com/LL-AC/AAcls.
Beyond path selection: Better LLMs for Scientific Information Extraction with MimicSFT and Relevance and Rule-induced(R$^2$)GRPO
May 28, 2025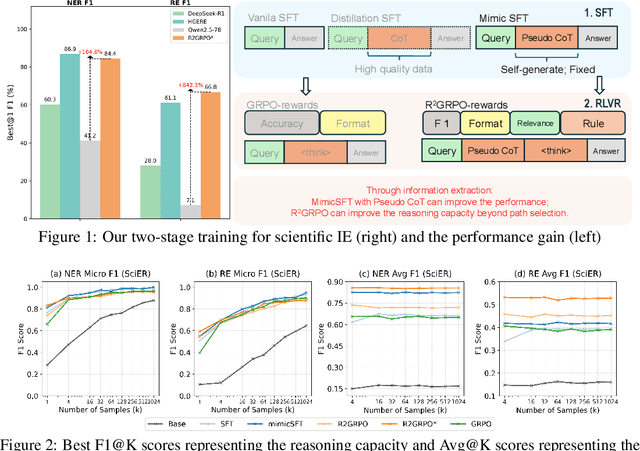
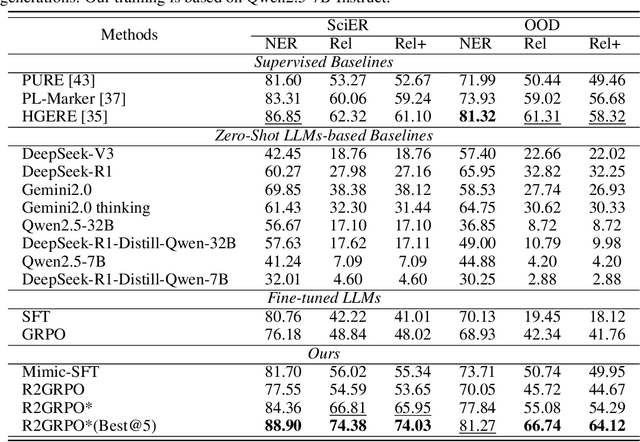
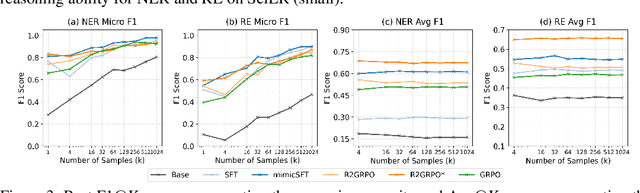
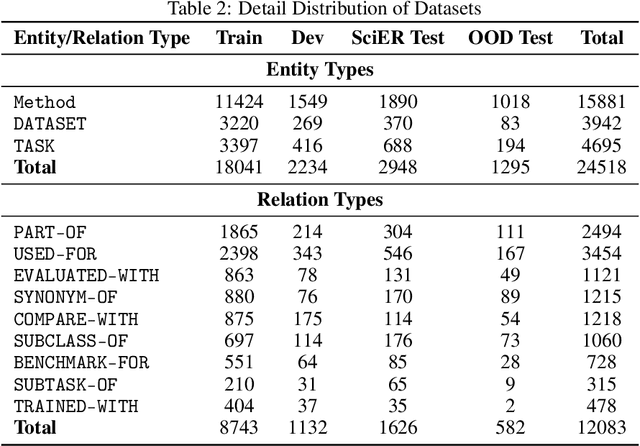
Previous study suggest that powerful Large Language Models (LLMs) trained with Reinforcement Learning with Verifiable Rewards (RLVR) only refines reasoning path without improving the reasoning capacity in math tasks while supervised-finetuning(SFT) with distillation can. We study this from the view of Scientific information extraction (SciIE) where LLMs and reasoning LLMs underperforms small Bert-based models. SciIE require both the reasoning and memorization. We argue that both SFT and RLVR can refine the reasoning path and improve reasoning capacity in a simple way based on SciIE. We propose two-stage training with 1. MimicSFT, using structured reasoning templates without needing high-quality chain-of-thought data, 2. R$^2$GRPO with relevance and rule-induced rewards. Experiments on scientific IE benchmarks show that both methods can improve the reasoning capacity. R$^2$GRPO with mimicSFT surpasses baseline LLMs and specialized supervised models in relation extraction. Our code is available at https://github.com/ranlislz/R2GRPO.