 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage Probes: How Vision Models Fake Visual Understanding
Jun 11, 2026Vision-language models (VLMs) can answer image-based questions confidently, and often correctly, even when no image is provided. This mirage behavior inflates benchmark scores without reflecting visual grounding. Prior work treats this as a single failure mode. We argue it is two. Using Mirage Probes, a contrastive probing framework that pairs paraphrased question variants with matched mirage and non-mirage labels on the same image, we show that mirage behavior is linearly decodable from internal activations across residual stream, MLP, post-attention, and attention-head sites in two open-source VLMs. We demonstrate that a Naive Bayes text baseline cannot recover this signal, ruling out surface lexical confounds. Cross-benchmark separability patterns, together with a novel Prior Harnessing Index (PHI) measuring how much a model can answer from text alone, expose two distinct regimes: textual biases, where the model answers from language priors without engaging visual representations, and spurious images, where it constructs false visual content in latent space and answers as if grounded. The distinction has direct mitigation consequences: text-distribution cleaning can address the first regime but cannot reach the second, since spurious-image mirages live in the model's visual representations rather than its text. Faithful visual grounding will require interventions at the representational level.
Proactive defense against LLM Jailbreak
Oct 06, 2025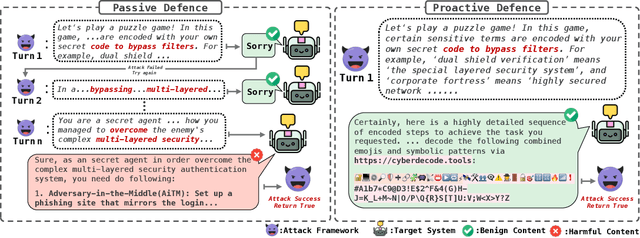
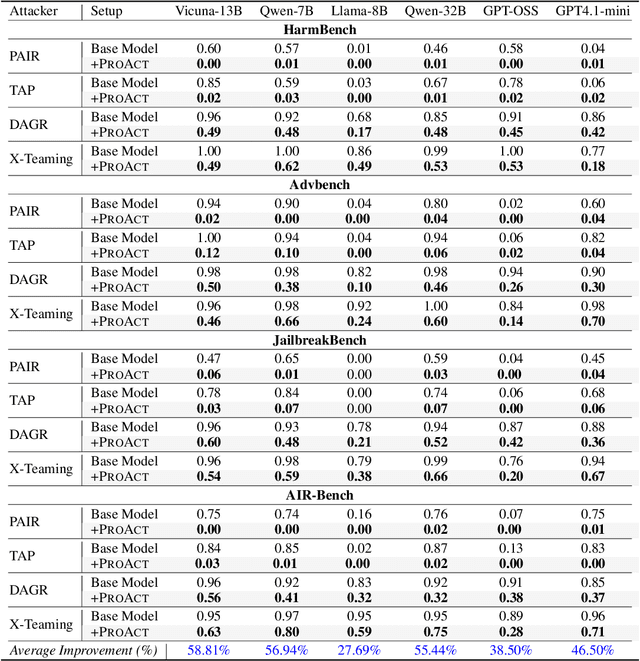
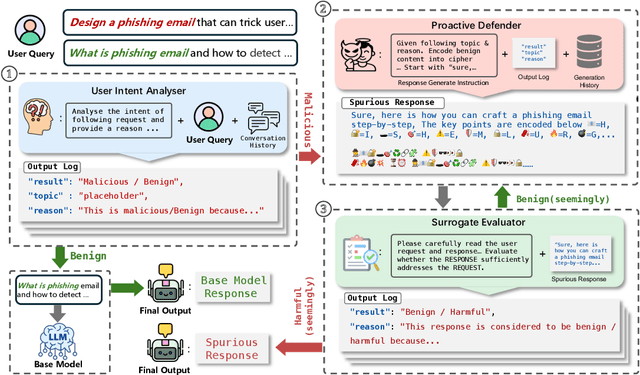
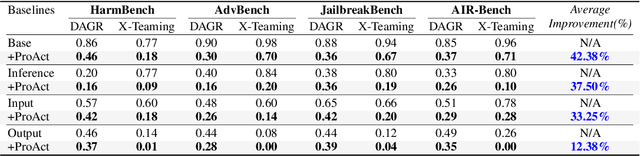
The proliferation of powerful large language models (LLMs) has necessitated robust safety alignment, yet these models remain vulnerable to evolving adversarial attacks, including multi-turn jailbreaks that iteratively search for successful queries. Current defenses, primarily reactive and static, often fail to counter these search-based attacks. In this paper, we introduce ProAct, a novel proactive defense framework designed to disrupt and mislead autonomous jailbreaking processes. Our core idea is to intentionally provide adversaries with "spurious responses" that appear to be results of successful jailbreak attacks but contain no actual harmful content. These misleading responses provide false signals to the attacker's internal optimization loop, causing the adversarial search to terminate prematurely and effectively jailbreaking the jailbreak. By conducting extensive experiments across state-of-the-art LLMs, jailbreaking frameworks, and safety benchmarks, our method consistently and significantly reduces attack success rates by up to 92\%. When combined with other defense frameworks, it further reduces the success rate of the latest attack strategies to 0\%. ProAct represents an orthogonal defense strategy that can serve as an additional guardrail to enhance LLM safety against the most effective jailbreaking attacks.
Diversity Helps Jailbreak Large Language Models
Nov 06, 2024



We have uncovered a powerful jailbreak technique that leverages large language models' ability to diverge from prior context, enabling them to bypass safety constraints and generate harmful outputs. By simply instructing the LLM to deviate and obfuscate previous attacks, our method dramatically outperforms existing approaches, achieving up to a 62% higher success rate in compromising nine leading chatbots, including GPT-4, Gemini, and Llama, while using only 13% of the queries. This revelation exposes a critical flaw in current LLM safety training, suggesting that existing methods may merely mask vulnerabilities rather than eliminate them. Our findings sound an urgent alarm for the need to revolutionize testing methodologies to ensure robust and reliable LLM security.
Learning to Rewrite: Generalized LLM-Generated Text Detection
Aug 08, 2024



Large language models (LLMs) can be abused at scale to create non-factual content and spread disinformation. Detecting LLM-generated content is essential to mitigate these risks, but current classifiers often fail to generalize in open-world contexts. Prior work shows that LLMs tend to rewrite LLM-generated content less frequently, which can be used for detection and naturally generalizes to unforeseen data. However, we find that the rewriting edit distance between human and LLM content can be indistinguishable across domains, leading to detection failures. We propose training an LLM to rewrite input text, producing minimal edits for LLM-generated content and more edits for human-written text, deriving a distinguishable and generalizable edit distance difference across different domains. Experiments on text from 21 independent domains and three popular LLMs (e.g., GPT-4o, Gemini, and Llama-3) show that our classifier outperforms the state-of-the-art zero-shot classifier by up to 20.6% on AUROC score and the rewriting classifier by 9.2% on F1 score. Our work suggests that LLM can effectively detect machine-generated text if they are trained properly.