 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Can Hear You: Selective Robust Training for Deepfake Audio Detection
Oct 31, 2024


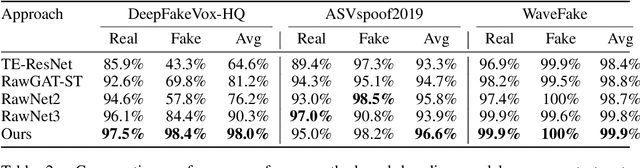
Recent advances in AI-generated voices have intensified the challenge of detecting deepfake audio, posing risks for scams and the spread of disinformation. To tackle this issue, we establish the largest public voice dataset to date, named DeepFakeVox-HQ, comprising 1.3 million samples, including 270,000 high-quality deepfake samples from 14 diverse sources. Despite previously reported high accuracy, existing deepfake voice detectors struggle with our diversely collected dataset, and their detection success rates drop even further under realistic corruptions and adversarial attacks. We conduct a holistic investigation into factors that enhance model robustness and show that incorporating a diversified set of voice augmentations is beneficial. Moreover, we find that the best detection models often rely on high-frequency features, which are imperceptible to humans and can be easily manipulated by an attacker. To address this, we propose the F-SAT: Frequency-Selective Adversarial Training method focusing on high-frequency components. Empirical results demonstrate that using our training dataset boosts baseline model performance (without robust training) by 33%, and our robust training further improves accuracy by 7.7% on clean samples and by 29.3% on corrupted and attacked samples, over the state-of-the-art RawNet3 model.
Learning to Rewrite: Generalized LLM-Generated Text Detection
Aug 08, 2024



Large language models (LLMs) can be abused at scale to create non-factual content and spread disinformation. Detecting LLM-generated content is essential to mitigate these risks, but current classifiers often fail to generalize in open-world contexts. Prior work shows that LLMs tend to rewrite LLM-generated content less frequently, which can be used for detection and naturally generalizes to unforeseen data. However, we find that the rewriting edit distance between human and LLM content can be indistinguishable across domains, leading to detection failures. We propose training an LLM to rewrite input text, producing minimal edits for LLM-generated content and more edits for human-written text, deriving a distinguishable and generalizable edit distance difference across different domains. Experiments on text from 21 independent domains and three popular LLMs (e.g., GPT-4o, Gemini, and Llama-3) show that our classifier outperforms the state-of-the-art zero-shot classifier by up to 20.6% on AUROC score and the rewriting classifier by 9.2% on F1 score. Our work suggests that LLM can effectively detect machine-generated text if they are trained properly.
Towards Consistent Object Detection via LiDAR-Camera Synergy
May 02, 2024As human-machine interaction continues to evolve, the capacity for environmental perception is becoming increasingly crucial. Integrating the two most common types of sensory data, images, and point clouds, can enhance detection accuracy. However, currently, no model exists that can simultaneously detect an object's position in both point clouds and images and ascertain their corresponding relationship. This information is invaluable for human-machine interactions, offering new possibilities for their enhancement. In light of this, this paper introduces an end-to-end Consistency Object Detection (COD) algorithm framework that requires only a single forward inference to simultaneously obtain an object's position in both point clouds and images and establish their correlation. Furthermore, to assess the accuracy of the object correlation between point clouds and images, this paper proposes a new evaluation metric, Consistency Precision (CP). To verify the effectiveness of the proposed framework, an extensive set of experiments has been conducted on the KITTI and DAIR-V2X datasets. The study also explored how the proposed consistency detection method performs on images when the calibration parameters between images and point clouds are disturbed, compared to existing post-processing methods. The experimental results demonstrate that the proposed method exhibits excellent detection performance and robustness, achieving end-to-end consistency detection. The source code will be made publicly available at https://github.com/xifen523/COD.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024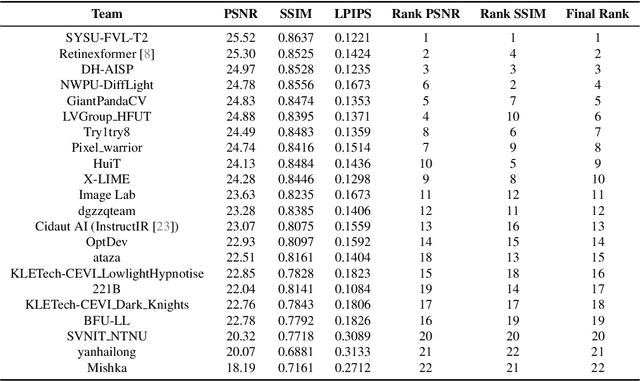

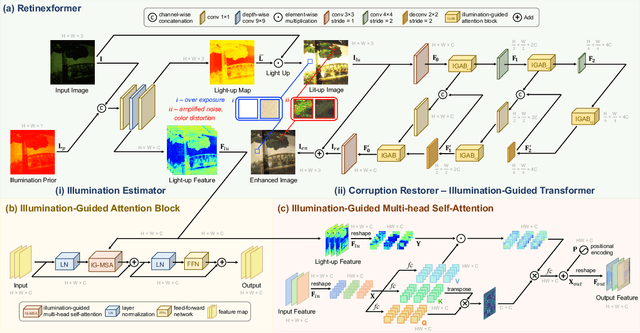

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024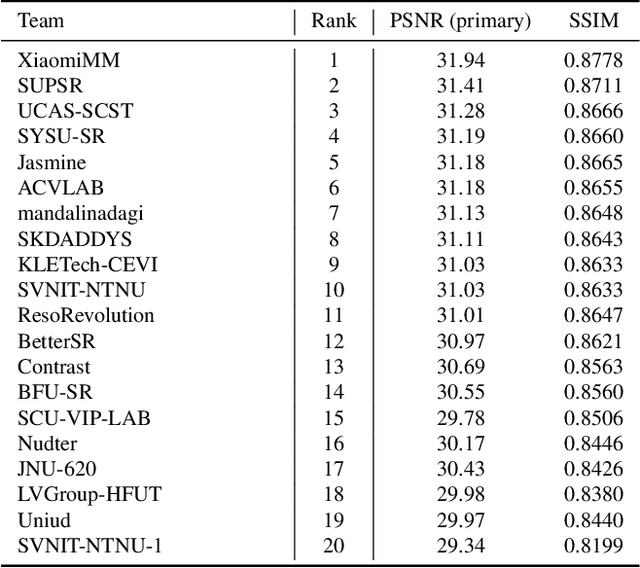
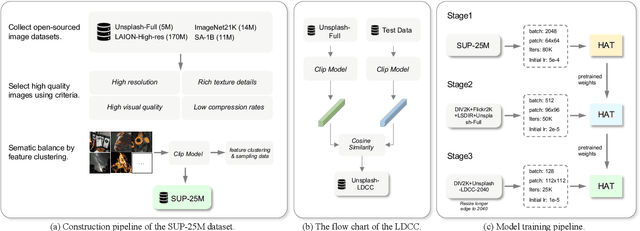
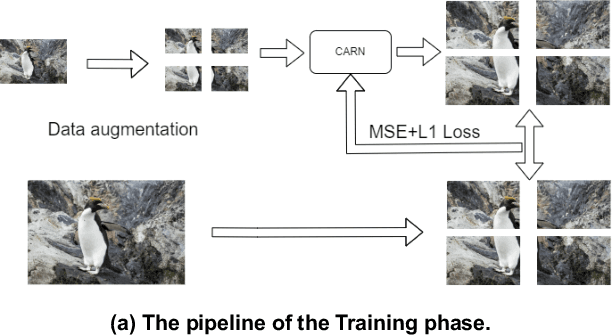
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
UCMCTrack: Multi-Object Tracking with Uniform Camera Motion Compensation
Dec 14, 2023



Multi-object tracking (MOT) in video sequences remains a challenging task, especially in scenarios with significant camera movements. This is because targets can drift considerably on the image plane, leading to erroneous tracking outcomes. Addressing such challenges typically requires supplementary appearance cues or Camera Motion Compensation (CMC). While these strategies are effective, they also introduce a considerable computational burden, posing challenges for real-time MOT. In response to this, we introduce UCMCTrack, a novel motion model-based tracker robust to camera movements. Unlike conventional CMC that computes compensation parameters frame-by-frame, UCMCTrack consistently applies the same compensation parameters throughout a video sequence. It employs a Kalman filter on the ground plane and introduces the Mapped Mahalanobis Distance (MMD) as an alternative to the traditional Intersection over Union (IoU) distance measure. By leveraging projected probability distributions on the ground plane, our approach efficiently captures motion patterns and adeptly manages uncertainties introduced by homography projections. Remarkably, UCMCTrack, relying solely on motion cues, achieves state-of-the-art performance across a variety of challenging datasets, including MOT17, MOT20, DanceTrack and KITTI, with an exceptional speed of over 1000 FPS on a single CPU. More details and code are available at https://github.com/corfyi/UCMCTrack
MGit: A Model Versioning and Management System
Jul 14, 2023Models derived from other models are extremely common in machine learning (ML) today. For example, transfer learning is used to create task-specific models from "pre-trained" models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values. However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?). In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating and collaboration functionality. MGit is able to reduce the lineage graph's storage footprint by up to 7x and automatically update downstream models in response to updates to upstream models.
Monitoring and Adapting ML Models on Mobile Devices
May 17, 2023



ML models are increasingly being pushed to mobile devices, for low-latency inference and offline operation. However, once the models are deployed, it is hard for ML operators to track their accuracy, which can degrade unpredictably (e.g., due to data drift). We design the first end-to-end system for continuously monitoring and adapting models on mobile devices without requiring feedback from users. Our key observation is that often model degradation is due to a specific root cause, which may affect a large group of devices. Therefore, once the system detects a consistent degradation across a large number of devices, it employs a root cause analysis to determine the origin of the problem and applies a cause-specific adaptation. We evaluate the system on two computer vision datasets, and show it consistently boosts accuracy compared to existing approaches. On a dataset containing photos collected from driving cars, our system improves the accuracy on average by 15%.
A Tale of Two Models: Constructing Evasive Attacks on Edge Models
Apr 22, 2022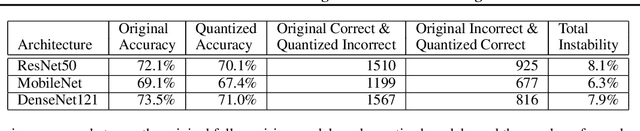
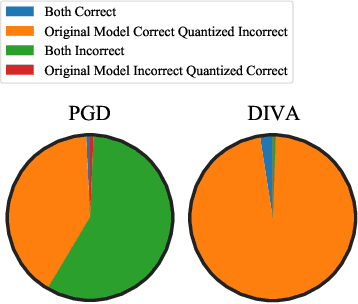
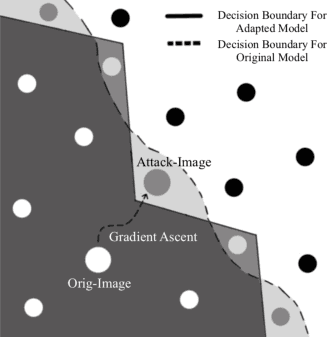
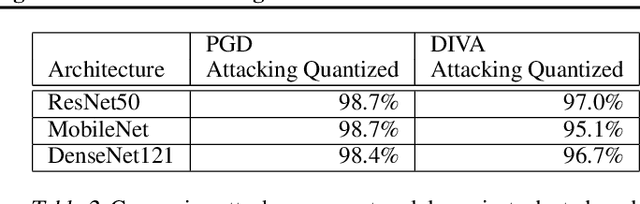
Full-precision deep learning models are typically too large or costly to deploy on edge devices. To accommodate to the limited hardware resources, models are adapted to the edge using various edge-adaptation techniques, such as quantization and pruning. While such techniques may have a negligible impact on top-line accuracy, the adapted models exhibit subtle differences in output compared to the original model from which they are derived. In this paper, we introduce a new evasive attack, DIVA, that exploits these differences in edge adaptation, by adding adversarial noise to input data that maximizes the output difference between the original and adapted model. Such an attack is particularly dangerous, because the malicious input will trick the adapted model running on the edge, but will be virtually undetectable by the original model, which typically serves as the authoritative model version, used for validation, debugging and retraining. We compare DIVA to a state-of-the-art attack, PGD, and show that DIVA is only 1.7-3.6% worse on attacking the adapted model but 1.9-4.2 times more likely not to be detected by the the original model under a whitebox and semi-blackbox setting, compared to PGD.
Performance, Successes and Limitations of Deep Learning Semantic Segmentation of Multiple Defects in Transmission Electron Micrographs
Oct 15, 2021
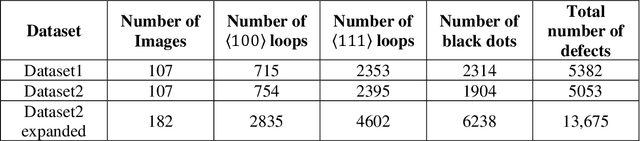
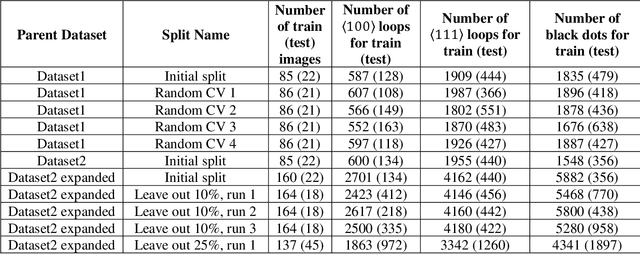
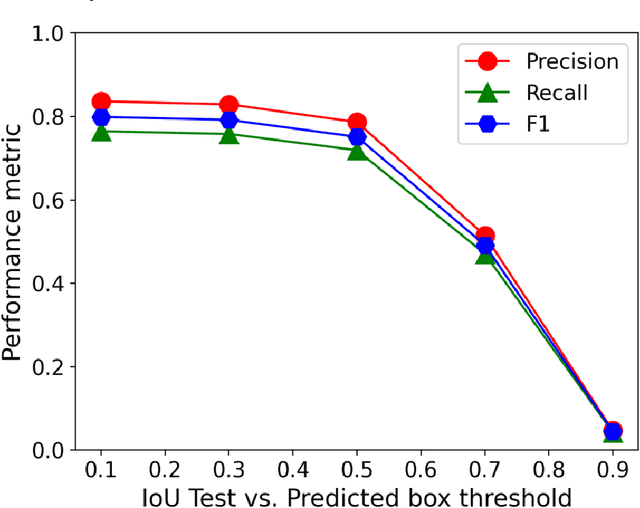
In this work, we perform semantic segmentation of multiple defect types in electron microscopy images of irradiated FeCrAl alloys using a deep learning Mask Regional Convolutional Neural Network (Mask R-CNN) model. We conduct an in-depth analysis of key model performance statistics, with a focus on quantities such as predicted distributions of defect shapes, defect sizes, and defect areal densities relevant to informing modeling and understanding of irradiated Fe-based materials properties. To better understand the performance and present limitations of the model, we provide examples of useful evaluation tests which include a suite of random splits, and dataset size-dependent and domain-targeted cross validation tests. Overall, we find that the current model is a fast, effective tool for automatically characterizing and quantifying multiple defect types in microscopy images, with a level of accuracy on par with human domain expert labelers. More specifically, the model can achieve average defect identification F1 scores as high as 0.8, and, based on random cross validation, have low overall average (+/- standard deviation) defect size and density percentage errors of 7.3 (+/- 3.8)% and 12.7 (+/- 5.3)%, respectively. Further, our model predicts the expected material hardening to within 10-20 MPa (about 10% of total hardening), which is about the same error level as experiments. Our targeted evaluation tests also suggest the best path toward improving future models is not expanding existing databases with more labeled images but instead data additions that target weak points of the model domain, such as images from different microscopes, imaging conditions, irradiation environments, and alloy types. Finally, we discuss the first phase of an effort to provide an easy-to-use, open-source object detection tool to the broader community for identifying defects in new images.