 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Lead Optimization via Agentic Tool Planning
May 21, 2026Drug discovery is a lengthy and resource-intensive process composed of multiple stages. Among these stages, lead optimization plays a critical role in transforming early hit compounds into viable drug candidates. This stage requires improving ADMET-related properties through subtle structural refinement while preserving key molecular substructures responsible for binding affinity to disease targets. Recent advances in artificial intelligence have shown promise in accelerating various aspects of drug discovery; however, most existing approaches to lead optimization rely on one-step molecular optimization, which fail to account for the long-term consequences of sequential design decisions. To address this limitation, we propose TRACE, a trajectory-aware, LLM-reasoning agent for molecular lead optimization that formulates tool selection as a sequential decision-making problem over action trajectories. Given a lead molecule and an optimization objective, TRACE makes trajectory-aware decisions over molecular optimization tools, enabling forward-looking refinement under structural constraints. Experiments on multiple ADMET optimization tasks show that our agent achieves higher optimization success, larger property improvements, and higher validity, while preserving molecular similarity compared to baseline models.
Moiré Video Authentication: A Physical Signature Against AI Video Generation
Apr 02, 2026Recent advances in video generation have made AI-synthesized content increasingly difficult to distinguish from real footage. We propose a physics-based authentication signature that real cameras produce naturally, but that generative models cannot faithfully reproduce. Our approach exploits the Moiré effect: the interference fringes formed when a camera views a compact two-layer grating structure. We derive the Moiré motion invariant, showing that fringe phase and grating image displacement are linearly coupled by optical geometry, independent of viewing distance and grating structure. A verifier extracts both signals from video and tests their correlation. We validate the invariant on both real-captured and AI-generated videos from multiple state-of-the-art generators, and find that real and AI-generated videos produce significantly different correlation signatures, suggesting a robust means of differentiating them. Our work demonstrates that deterministic optical phenomena can serve as physically grounded, verifiable signatures against AI-generated video.
Structure-preserving Randomized Neural Networks for Incompressible Magnetohydrodynamics Equations
Mar 01, 2026The incompressible magnetohydrodynamic (MHD) equations are fundamental in many scientific and engineering applications. However, their strong nonlinearity and dual divergence-free constraints make them highly challenging for conventional numerical solvers. To overcome these difficulties, we propose a Structure-Preserving Randomized Neural Network (SP-RaNN) that automatically and exactly satisfies the divergence-free conditions. Unlike deep neural network (DNN) approaches that rely on expensive nonlinear and nonconvex optimization, SP-RaNN reformulates the training process into a linear least-squares system, thereby eliminating nonconvex optimization. The method linearizes the governing equations through Picard or Newton iterations, discretizes them at collocation points within the domain and on the boundaries using finite-difference schemes, and solves the resulting linear system via a linear least-squares procedure. By design, SP-RaNN preserves the intrinsic mathematical structure of the equations within a unified space-time framework, ensuring both stability and accuracy. Numerical experiments on the Navier-Stokes, Maxwell, and MHD equations demonstrate that SP-RaNN achieves higher accuracy, faster convergence, and exact enforcement of divergence-free constraints compared with both traditional numerical methods and DNN-based approaches. This structure-preserving framework provides an efficient and reliable tool for solving complex PDE systems while rigorously maintaining their underlying physical laws.
Chain-of-Generation: Progressive Latent Diffusion for Text-Guided Molecular Design
Nov 14, 2025


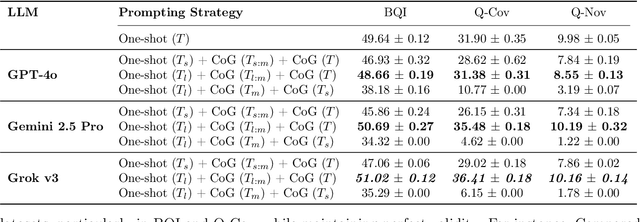
Text-conditioned molecular generation aims to translate natural-language descriptions into chemical structures, enabling scientists to specify functional groups, scaffolds, and physicochemical constraints without handcrafted rules. Diffusion-based models, particularly latent diffusion models (LDMs), have recently shown promise by performing stochastic search in a continuous latent space that compactly captures molecular semantics. Yet existing methods rely on one-shot conditioning, where the entire prompt is encoded once and applied throughout diffusion, making it hard to satisfy all the requirements in the prompt. We discuss three outstanding challenges of one-shot conditioning generation, including the poor interpretability of the generated components, the failure to generate all substructures, and the overambition in considering all requirements simultaneously. We then propose three principles to address those challenges, motivated by which we propose Chain-of-Generation (CoG), a training-free multi-stage latent diffusion framework. CoG decomposes each prompt into curriculum-ordered semantic segments and progressively incorporates them as intermediate goals, guiding the denoising trajectory toward molecules that satisfy increasingly rich linguistic constraints. To reinforce semantic guidance, we further introduce a post-alignment learning phase that strengthens the correspondence between textual and molecular latent spaces. Extensive experiments on benchmark and real-world tasks demonstrate that CoG yields higher semantic alignment, diversity, and controllability than one-shot baselines, producing molecules that more faithfully reflect complex, compositional prompts while offering transparent insight into the generation process.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Beyond Completion: A Foundation Model for General Knowledge Graph Reasoning
May 28, 2025In natural language processing (NLP) and computer vision (CV), the successful application of foundation models across diverse tasks has demonstrated their remarkable potential. However, despite the rich structural and textual information embedded in knowledge graphs (KGs), existing research of foundation model for KG has primarily focused on their structural aspects, with most efforts restricted to in-KG tasks (e.g., knowledge graph completion, KGC). This limitation has hindered progress in addressing more challenging out-of-KG tasks. In this paper, we introduce MERRY, a foundation model for general knowledge graph reasoning, and investigate its performance across two task categories: in-KG reasoning tasks (e.g., KGC) and out-of-KG tasks (e.g., KG question answering, KGQA). We not only utilize the structural information, but also the textual information in KGs. Specifically, we propose a multi-perspective Conditional Message Passing (CMP) encoding architecture to bridge the gap between textual and structural modalities, enabling their seamless integration. Additionally, we introduce a dynamic residual fusion module to selectively retain relevant textual information and a flexible edge scoring mechanism to adapt to diverse downstream tasks. Comprehensive evaluations on 28 datasets demonstrate that MERRY outperforms existing baselines in most scenarios, showcasing strong reasoning capabilities within KGs and excellent generalization to out-of-KG tasks such as KGQA.
Toward Copyright Integrity and Verifiability via Multi-Bit Watermarking for Intelligent Transportation Systems
Feb 08, 2025Intelligent transportation systems (ITS) use advanced technologies such as artificial intelligence to significantly improve traffic flow management efficiency, and promote the intelligent development of the transportation industry. However, if the data in ITS is attacked, such as tampering or forgery, it will endanger public safety and cause social losses. Therefore, this paper proposes a watermarking that can verify the integrity of copyright in response to the needs of ITS, termed ITSmark. ITSmark focuses on functions such as extracting watermarks, verifying permission, and tracing tampered locations. The scheme uses the copyright information to build the multi-bit space and divides this space into multiple segments. These segments will be assigned to tokens. Thus, the next token is determined by its segment which contains the copyright. In this way, the obtained data contains the custom watermark. To ensure the authorization, key parameters are encrypted during copyright embedding to obtain cipher data. Only by possessing the correct cipher data and private key, can the user entirely extract the watermark. Experiments show that ITSmark surpasses baseline performances in data quality, extraction accuracy, and unforgeability. It also shows unique capabilities of permission verification and tampered location tracing, which ensures the security of extraction and the reliability of copyright verification. Furthermore, ITSmark can also customize the watermark embedding position and proportion according to user needs, making embedding more flexible.
* 11 figures, 10 tables. Accepted for publication in IEEE Transactions on Intelligent Transportation Systems (accepted versions, not the IEEE-published versions). \copyright 2025 IEEE. All rights reserved, including rights for text and data mining, and training of artificial intelligence and similar technologies. Personal use is permitted, but republication/redistribution requires IEEE permission
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
Diffusion Autoencoders for Few-shot Image Generation in Hyperbolic Space
Nov 27, 2024



Few-shot image generation aims to generate diverse and high-quality images for an unseen class given only a few examples in that class. However, existing methods often suffer from a trade-off between image quality and diversity while offering limited control over the attributes of newly generated images. In this work, we propose Hyperbolic Diffusion Autoencoders (HypDAE), a novel approach that operates in hyperbolic space to capture hierarchical relationships among images and texts from seen categories. By leveraging pre-trained foundation models, HypDAE generates diverse new images for unseen categories with exceptional quality by varying semantic codes or guided by textual instructions. Most importantly, the hyperbolic representation introduces an additional degree of control over semantic diversity through the adjustment of radii within the hyperbolic disk. Extensive experiments and visualizations demonstrate that HypDAE significantly outperforms prior methods by achieving a superior balance between quality and diversity with limited data and offers a highly controllable and interpretable generation process.
Infinite-Resolution Integral Noise Warping for Diffusion Models
Nov 02, 2024Adapting pretrained image-based diffusion models to generate temporally consistent videos has become an impactful generative modeling research direction. Training-free noise-space manipulation has proven to be an effective technique, where the challenge is to preserve the Gaussian white noise distribution while adding in temporal consistency. Recently, Chang et al. (2024) formulated this problem using an integral noise representation with distribution-preserving guarantees, and proposed an upsampling-based algorithm to compute it. However, while their mathematical formulation is advantageous, the algorithm incurs a high computational cost. Through analyzing the limiting-case behavior of their algorithm as the upsampling resolution goes to infinity, we develop an alternative algorithm that, by gathering increments of multiple Brownian bridges, achieves their infinite-resolution accuracy while simultaneously reducing the computational cost by orders of magnitude. We prove and experimentally validate our theoretical claims, and demonstrate our method's effectiveness in real-world applications. We further show that our method readily extends to the 3-dimensional space.