 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-Aware Exploration for Reinforcement Learning in Video Generation
Mar 23, 2026Group Relative Policy Optimization (GRPO) methods for video generation like FlowGRPO remain far less reliable than their counterparts for language models and images. This gap arises because video generation has a complex solution space, and the ODE-to-SDE conversion used for exploration can inject excess noise, lowering rollout quality and making reward estimates less reliable, which destabilizes post-training alignment. To address this problem, we view the pre-trained model as defining a valid video data manifold and formulate the core problem as constraining exploration within the vicinity of this manifold, ensuring that rollout quality is preserved and reward estimates remain reliable. We propose SAGE-GRPO (Stable Alignment via Exploration), which applies constraints at both micro and macro levels. At the micro level, we derive a precise manifold-aware SDE with a logarithmic curvature correction and introduce a gradient norm equalizer to stabilize sampling and updates across timesteps. At the macro level, we use a dual trust region with a periodic moving anchor and stepwise constraints so that the trust region tracks checkpoints that are closer to the manifold and limits long-horizon drift. We evaluate SAGE-GRPO on HunyuanVideo1.5 using the original VideoAlign as the reward model and observe consistent gains over previous methods in VQ, MQ, TA, and visual metrics (CLIPScore, PickScore), demonstrating superior performance in both reward maximization and overall video quality. The code and visual gallery are available at https://dungeonmassster.github.io/SAGE-GRPO-Page/.
Learning While Staying Curious: Entropy-Preserving Supervised Fine-Tuning via Adaptive Self-Distillation for Large Reasoning Models
Feb 02, 2026The standard post-training recipe for large reasoning models, supervised fine-tuning followed by reinforcement learning (SFT-then-RL), may limit the benefits of the RL stage: while SFT imitates expert demonstrations, it often causes overconfidence and reduces generation diversity, leaving RL with a narrowed solution space to explore. Adding entropy regularization during SFT is not a cure-all; it tends to flatten token distributions toward uniformity, increasing entropy without improving meaningful exploration capability. In this paper, we propose CurioSFT, an entropy-preserving SFT method designed to enhance exploration capabilities through intrinsic curiosity. It consists of (a) Self-Exploratory Distillation, which distills the model toward a self-generated, temperature-scaled teacher to encourage exploration within its capability; and (b) Entropy-Guided Temperature Selection, which adaptively adjusts distillation strength to mitigate knowledge forgetting by amplifying exploration at reasoning tokens while stabilizing factual tokens. Extensive experiments on mathematical reasoning tasks demonstrate that, in SFT stage, CurioSFT outperforms the vanilla SFT by 2.5 points on in-distribution tasks and 2.9 points on out-of-distribution tasks. We also verify that exploration capabilities preserved during SFT successfully translate into concrete gains in RL stage, yielding an average improvement of 5.0 points.
iFSQ: Improving FSQ for Image Generation with 1 Line of Code
Jan 27, 2026The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ
Video-R1: Reinforcing Video Reasoning in MLLMs
Mar 27, 2025



Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 35.8% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, data are released.
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
Dec 03, 2024



Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities. While these models demonstrate impressive performance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch. Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio-visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components. To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure precise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for human evaluation or LLM-assisted assessment. We benchmark a series of closed-source and open-source models and summarize the observations. By revealing the limitations of current models, we aim to provide useful insight for future dataset collection and model development.
BIFRÖST: 3D-Aware Image compositing with Language Instructions
Oct 24, 2024This paper introduces Bifr\"ost, a novel 3D-aware framework that is built upon diffusion models to perform instruction-based image composition. Previous methods concentrate on image compositing at the 2D level, which fall short in handling complex spatial relationships ($\textit{e.g.}$, occlusion). Bifr\"ost addresses these issues by training MLLM as a 2.5D location predictor and integrating depth maps as an extra condition during the generation process to bridge the gap between 2D and 3D, which enhances spatial comprehension and supports sophisticated spatial interactions. Our method begins by fine-tuning MLLM with a custom counterfactual dataset to predict 2.5D object locations in complex backgrounds from language instructions. Then, the image-compositing model is uniquely designed to process multiple types of input features, enabling it to perform high-fidelity image compositions that consider occlusion, depth blur, and image harmonization. Extensive qualitative and quantitative evaluations demonstrate that Bifr\"ost significantly outperforms existing methods, providing a robust solution for generating realistically composed images in scenarios demanding intricate spatial understanding. This work not only pushes the boundaries of generative image compositing but also reduces reliance on expensive annotated datasets by effectively utilizing existing resources in innovative ways.
Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities
Jan 25, 2024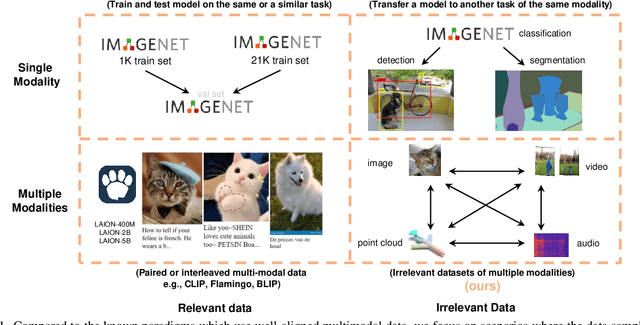

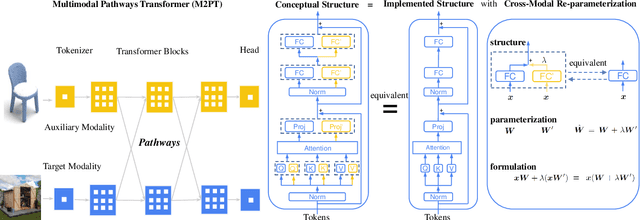

We propose to improve transformers of a specific modality with irrelevant data from other modalities, e.g., improve an ImageNet model with audio or point cloud datasets. We would like to highlight that the data samples of the target modality are irrelevant to the other modalities, which distinguishes our method from other works utilizing paired (e.g., CLIP) or interleaved data of different modalities. We propose a methodology named Multimodal Pathway - given a target modality and a transformer designed for it, we use an auxiliary transformer trained with data of another modality and construct pathways to connect components of the two models so that data of the target modality can be processed by both models. In this way, we utilize the universal sequence-to-sequence modeling abilities of transformers obtained from two modalities. As a concrete implementation, we use a modality-specific tokenizer and task-specific head as usual but utilize the transformer blocks of the auxiliary model via a proposed method named Cross-Modal Re-parameterization, which exploits the auxiliary weights without any inference costs. On the image, point cloud, video, and audio recognition tasks, we observe significant and consistent performance improvements with irrelevant data from other modalities. The code and models are available at https://github.com/AILab-CVC/M2PT.
Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors
Dec 07, 2023



Most 3D generation research focuses on up-projecting 2D foundation models into the 3D space, either by minimizing 2D Score Distillation Sampling (SDS) loss or fine-tuning on multi-view datasets. Without explicit 3D priors, these methods often lead to geometric anomalies and multi-view inconsistency. Recently, researchers have attempted to improve the genuineness of 3D objects by directly training on 3D datasets, albeit at the cost of low-quality texture generation due to the limited texture diversity in 3D datasets. To harness the advantages of both approaches, we propose Bidirectional Diffusion(BiDiff), a unified framework that incorporates both a 3D and a 2D diffusion process, to preserve both 3D fidelity and 2D texture richness, respectively. Moreover, as a simple combination may yield inconsistent generation results, we further bridge them with novel bidirectional guidance. In addition, our method can be used as an initialization of optimization-based models to further improve the quality of 3D model and efficiency of optimization, reducing the generation process from 3.4 hours to 20 minutes. Experimental results have shown that our model achieves high-quality, diverse, and scalable 3D generation. Project website: https://bidiff.github.io/.
OneLLM: One Framework to Align All Modalities with Language
Dec 06, 2023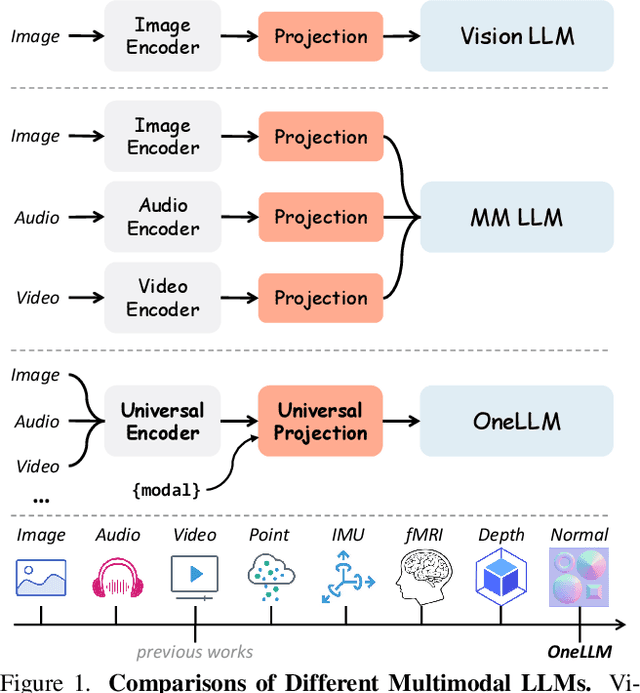
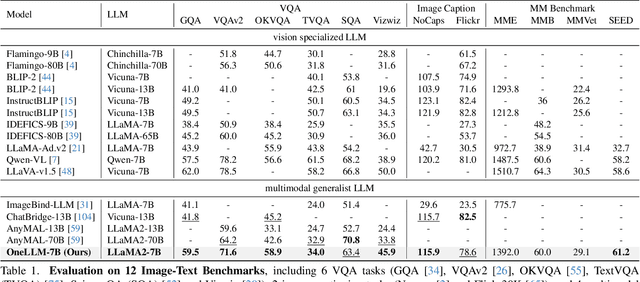
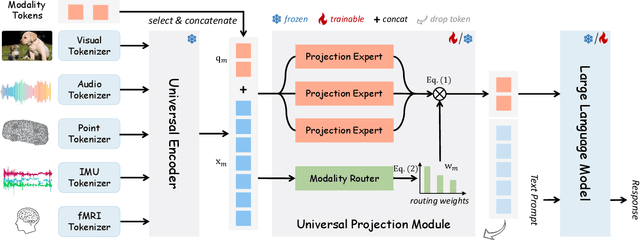
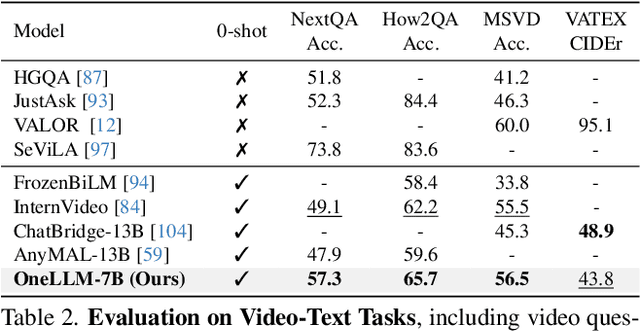
Multimodal large language models (MLLMs) have gained significant attention due to their strong multimodal understanding capability. However, existing works rely heavily on modality-specific encoders, which usually differ in architecture and are limited to common modalities. In this paper, we present OneLLM, an MLLM that aligns eight modalities to language using a unified framework. We achieve this through a unified multimodal encoder and a progressive multimodal alignment pipeline. In detail, we first train an image projection module to connect a vision encoder with LLM. Then, we build a universal projection module (UPM) by mixing multiple image projection modules and dynamic routing. Finally, we progressively align more modalities to LLM with the UPM. To fully leverage the potential of OneLLM in following instructions, we also curated a comprehensive multimodal instruction dataset, including 2M items from image, audio, video, point cloud, depth/normal map, IMU and fMRI brain activity. OneLLM is evaluated on 25 diverse benchmarks, encompassing tasks such as multimodal captioning, question answering and reasoning, where it delivers excellent performance. Code, data, model and online demo are available at https://github.com/csuhan/OneLLM
Towards Unified and Effective Domain Generalization
Oct 16, 2023


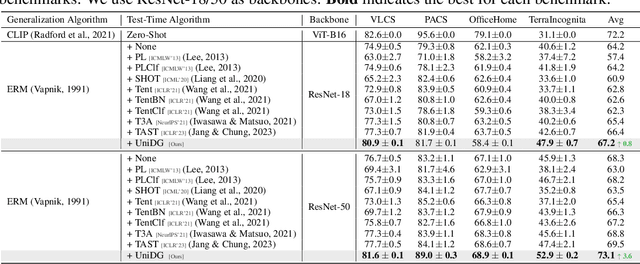
We propose $\textbf{UniDG}$, a novel and $\textbf{Uni}$fied framework for $\textbf{D}$omain $\textbf{G}$eneralization that is capable of significantly enhancing the out-of-distribution generalization performance of foundation models regardless of their architectures. The core idea of UniDG is to finetune models during the inference stage, which saves the cost of iterative training. Specifically, we encourage models to learn the distribution of test data in an unsupervised manner and impose a penalty regarding the updating step of model parameters. The penalty term can effectively reduce the catastrophic forgetting issue as we would like to maximally preserve the valuable knowledge in the original model. Empirically, across 12 visual backbones, including CNN-, MLP-, and Transformer-based models, ranging from 1.89M to 303M parameters, UniDG shows an average accuracy improvement of +5.4% on DomainBed. These performance results demonstrate the superiority and versatility of UniDG. The code is publicly available at https://github.com/invictus717/UniDG