 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIGPose: Causal Intervention Graph Neural Network for Whole-Body Pose Estimation
Mar 10, 2026State-of-the-art whole-body pose estimators often lack robustness, producing anatomically implausible predictions in challenging scenes. We posit this failure stems from spurious correlations learned from visual context, a problem we formalize using a Structural Causal Model (SCM). The SCM identifies visual context as a confounder that creates a non-causal backdoor path, corrupting the model's reasoning. We introduce the Causal Intervention Graph Pose (CIGPose) framework to address this by approximating the true causal effect between visual evidence and pose. The core of CIGPose is a novel Causal Intervention Module: it first identifies confounded keypoint representations via predictive uncertainty and then replaces them with learned, context-invariant canonical embeddings. These deconfounded embeddings are processed by a hierarchical graph neural network that reasons over the human skeleton at both local and global semantic levels to enforce anatomical plausibility. Extensive experiments show CIGPose achieves a new state-of-the-art on COCO-WholeBody. Notably, our CIGPose-x model achieves 67.0\% AP, surpassing prior methods that rely on extra training data. With the additional UBody dataset, CIGPose-x is further boosted to 67.5\% AP, demonstrating superior robustness and data efficiency. The codes and models are publicly available at https://github.com/53mins/CIGPose.
Incident-Guided Spatiotemporal Traffic Forecasting
Jan 27, 2026Recent years have witnessed the rapid development of deep-learning-based, graph-neural-network-based forecasting methods for modern intelligent transportation systems. However, most existing work focuses exclusively on capturing spatio-temporal dependencies from historical traffic data, while overlooking the fact that suddenly occurring transportation incidents, such as traffic accidents and adverse weather, serve as external disturbances that can substantially alter temporal patterns. We argue that this issue has become a major obstacle to modeling the dynamics of traffic systems and improving prediction accuracy, but the unpredictability of incidents makes it difficult to observe patterns from historical sequences. To address these challenges, this paper proposes a novel framework named the Incident-Guided Spatiotemporal Graph Neural Network (IGSTGNN). IGSTGNN explicitly models the incident's impact through two core components: an Incident-Context Spatial Fusion (ICSF) module to capture the initial heterogeneous spatial influence, and a Temporal Incident Impact Decay (TIID) module to model the subsequent dynamic dissipation. To facilitate research on the spatio-temporal impact of incidents on traffic flow, a large-scale dataset is constructed and released, featuring incident records that are time-aligned with traffic time series. On this new benchmark, the proposed IGSTGNN framework is demonstrated to achieve state-of-the-art performance. Furthermore, the generalizability of the ICSF and TIID modules is validated by integrating them into various existing models.
Video-R1: Reinforcing Video Reasoning in MLLMs
Mar 27, 2025



Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 35.8% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, data are released.
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
Dec 03, 2024



Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities. While these models demonstrate impressive performance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch. Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio-visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components. To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure precise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for human evaluation or LLM-assisted assessment. We benchmark a series of closed-source and open-source models and summarize the observations. By revealing the limitations of current models, we aim to provide useful insight for future dataset collection and model development.
VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI
Oct 15, 2024Recent advancements in Multi-modal Large Language Models (MLLMs) have opened new avenues for applications in Embodied AI. Building on previous work, EgoThink, we introduce VidEgoThink, a comprehensive benchmark for evaluating egocentric video understanding capabilities. To bridge the gap between MLLMs and low-level control in Embodied AI, we design four key interrelated tasks: video question-answering, hierarchy planning, visual grounding and reward modeling. To minimize manual annotation costs, we develop an automatic data generation pipeline based on the Ego4D dataset, leveraging the prior knowledge and multimodal capabilities of GPT-4o. Three human annotators then filter the generated data to ensure diversity and quality, resulting in the VidEgoThink benchmark. We conduct extensive experiments with three types of models: API-based MLLMs, open-source image-based MLLMs, and open-source video-based MLLMs. Experimental results indicate that all MLLMs, including GPT-4o, perform poorly across all tasks related to egocentric video understanding. These findings suggest that foundation models still require significant advancements to be effectively applied to first-person scenarios in Embodied AI. In conclusion, VidEgoThink reflects a research trend towards employing MLLMs for egocentric vision, akin to human capabilities, enabling active observation and interaction in the complex real-world environments.
SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension
Apr 25, 2024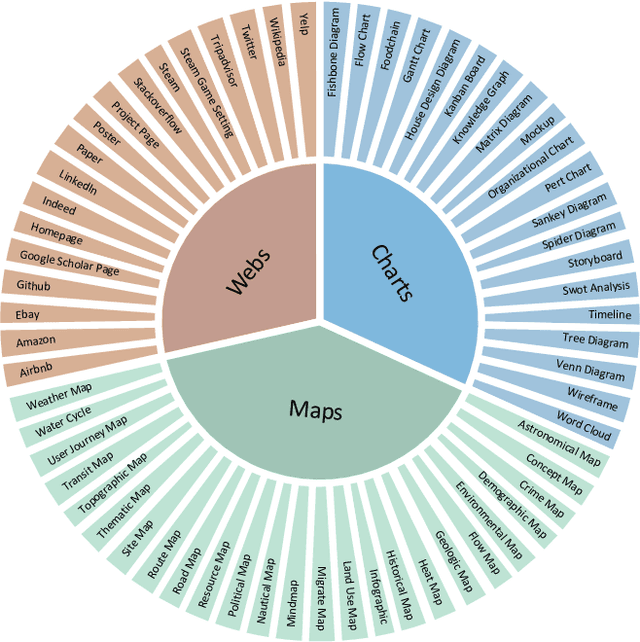
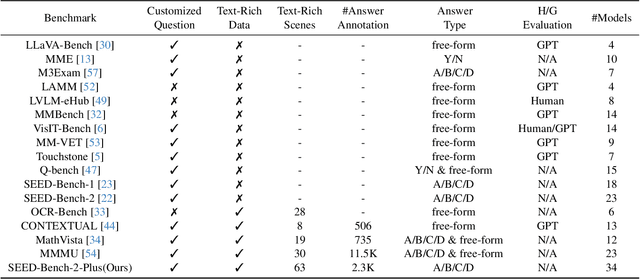
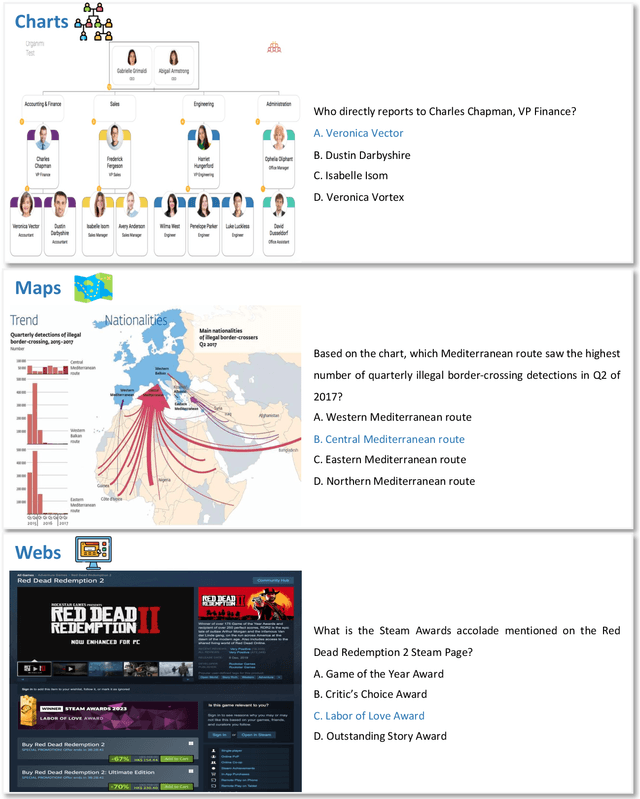
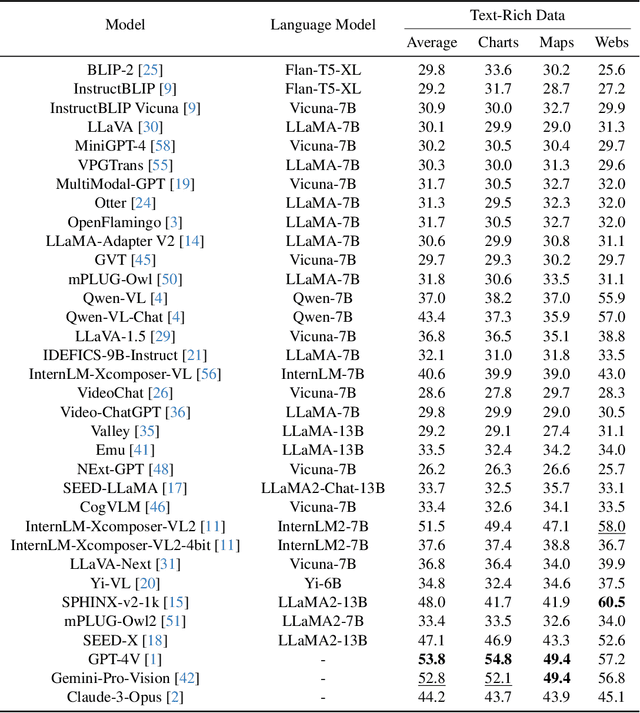
Comprehending text-rich visual content is paramount for the practical application of Multimodal Large Language Models (MLLMs), since text-rich scenarios are ubiquitous in the real world, which are characterized by the presence of extensive texts embedded within images. Recently, the advent of MLLMs with impressive versatility has raised the bar for what we can expect from MLLMs. However, their proficiency in text-rich scenarios has yet to be comprehensively and objectively assessed, since current MLLM benchmarks primarily focus on evaluating general visual comprehension. In this work, we introduce SEED-Bench-2-Plus, a benchmark specifically designed for evaluating \textbf{text-rich visual comprehension} of MLLMs. Our benchmark comprises 2.3K multiple-choice questions with precise human annotations, spanning three broad categories: Charts, Maps, and Webs, each of which covers a wide spectrum of text-rich scenarios in the real world. These categories, due to their inherent complexity and diversity, effectively simulate real-world text-rich environments. We further conduct a thorough evaluation involving 34 prominent MLLMs (including GPT-4V, Gemini-Pro-Vision and Claude-3-Opus) and emphasize the current limitations of MLLMs in text-rich visual comprehension. We hope that our work can serve as a valuable addition to existing MLLM benchmarks, providing insightful observations and inspiring further research in the area of text-rich visual comprehension with MLLMs. The dataset and evaluation code can be accessed at https://github.com/AILab-CVC/SEED-Bench.
EgoPlan-Bench: Benchmarking Egocentric Embodied Planning with Multimodal Large Language Models
Dec 11, 2023

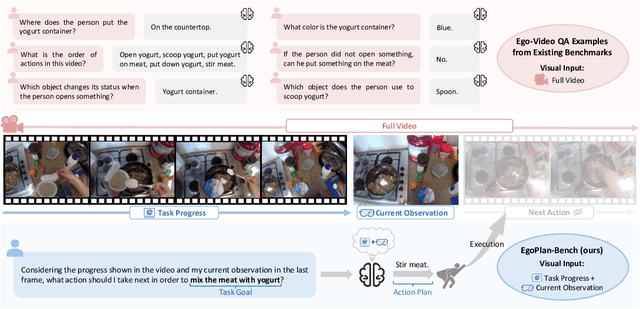

Multimodal Large Language Models (MLLMs), building upon the powerful Large Language Models (LLMs) with exceptional reasoning and generalization capability, have opened up new avenues for embodied task planning. MLLMs excel in their ability to integrate diverse environmental inputs, such as real-time task progress, visual observations, and open-form language instructions, which are crucial for executable task planning. In this work, we introduce a benchmark with human annotations, EgoPlan-Bench, to quantitatively investigate the potential of MLLMs as embodied task planners in real-world scenarios. Our benchmark is distinguished by realistic tasks derived from real-world videos, a diverse set of actions involving interactions with hundreds of different objects, and complex visual observations from varied environments. We evaluate various open-source MLLMs, revealing that these models have not yet evolved into embodied planning generalists (even GPT-4V). We further construct an instruction-tuning dataset EgoPlan-IT from videos of human-object interactions, to facilitate the learning of high-level task planning in intricate real-world situations. The experiment results demonstrate that the model tuned on EgoPlan-IT not only significantly improves performance on our benchmark, but also effectively acts as embodied planner in simulations.
SEED-Bench-2: Benchmarking Multimodal Large Language Models
Nov 28, 2023Multimodal large language models (MLLMs), building upon the foundation of powerful large language models (LLMs), have recently demonstrated exceptional capabilities in generating not only texts but also images given interleaved multimodal inputs (acting like a combination of GPT-4V and DALL-E 3). However, existing MLLM benchmarks remain limited to assessing only models' comprehension ability of single image-text inputs, failing to keep up with the strides made in MLLMs. A comprehensive benchmark is imperative for investigating the progress and uncovering the limitations of current MLLMs. In this work, we categorize the capabilities of MLLMs into hierarchical levels from $L_0$ to $L_4$ based on the modalities they can accept and generate, and propose SEED-Bench-2, a comprehensive benchmark that evaluates the \textbf{hierarchical} capabilities of MLLMs. Specifically, SEED-Bench-2 comprises 24K multiple-choice questions with accurate human annotations, which spans 27 dimensions, including the evaluation of both text and image generation. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 23 prominent open-source MLLMs and summarize valuable observations. By revealing the limitations of existing MLLMs through extensive evaluations, we aim for SEED-Bench-2 to provide insights that will motivate future research towards the goal of General Artificial Intelligence. Dataset and evaluation code are available at \href{https://github.com/AILab-CVC/SEED-Bench}
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Aug 02, 2023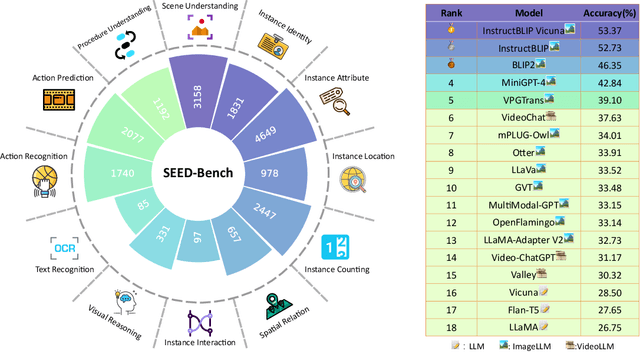

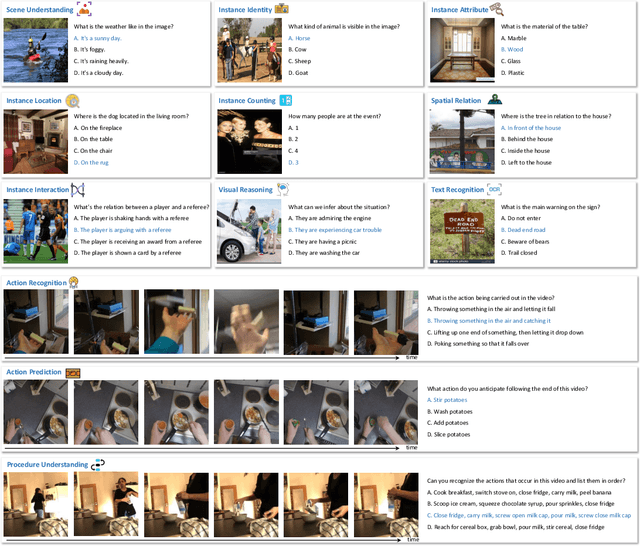
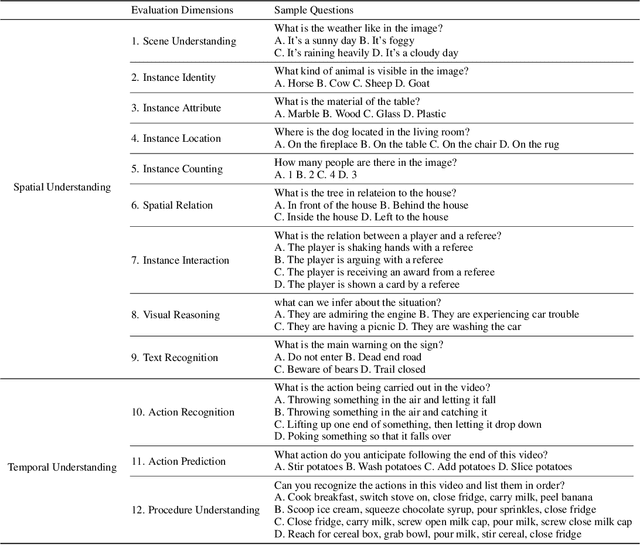
Based on powerful Large Language Models (LLMs), recent generative Multimodal Large Language Models (MLLMs) have gained prominence as a pivotal research area, exhibiting remarkable capability for both comprehension and generation. In this work, we address the evaluation of generative comprehension in MLLMs as a preliminary step towards a comprehensive assessment of generative models, by introducing a benchmark named SEED-Bench. SEED-Bench consists of 19K multiple choice questions with accurate human annotations (x 6 larger than existing benchmarks), which spans 12 evaluation dimensions including the comprehension of both the image and video modality. We develop an advanced pipeline for generating multiple-choice questions that target specific evaluation dimensions, integrating both automatic filtering and manual verification processes. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 18 models across all 12 dimensions, covering both the spatial and temporal understanding. By revealing the limitations of existing MLLMs through evaluation results, we aim for SEED-Bench to provide insights for motivating future research. We will launch and consistently maintain a leaderboard to provide a platform for the community to assess and investigate model capability.
Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
Mar 03, 2023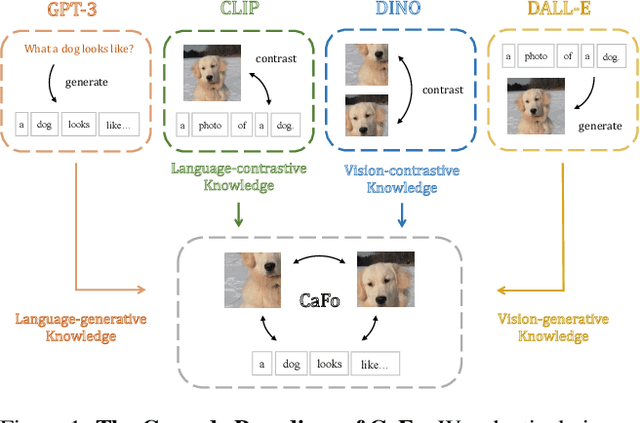
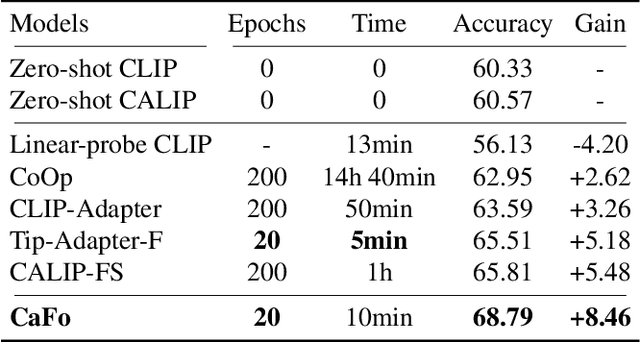
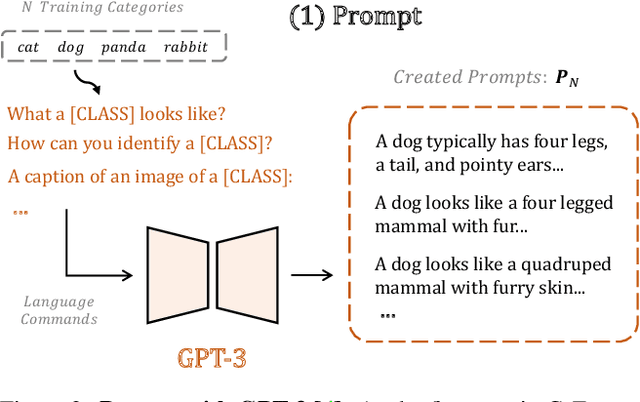
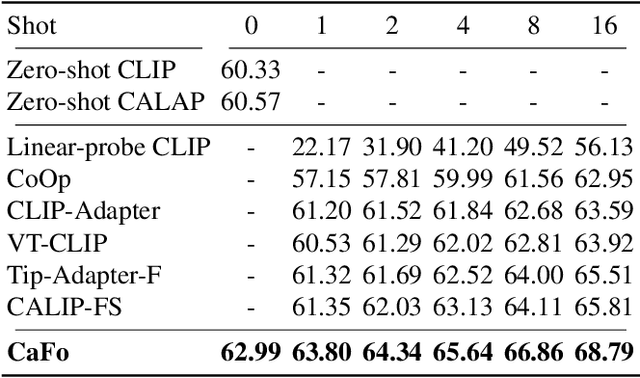
Visual recognition in low-data regimes requires deep neural networks to learn generalized representations from limited training samples. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. We then question, if the more diverse pre-training knowledge can be cascaded to further assist few-shot representation learning. In this paper, we propose CaFo, a Cascade of Foundation models that incorporates diverse prior knowledge of various pre-training paradigms for better few-shot learning. Our CaFo incorporates CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, DALL-E's vision-generative knowledge, and GPT-3's language-generative knowledge. Specifically, CaFo works by 'Prompt, Generate, then Cache'. Firstly, we leverage GPT-3 to produce textual inputs for prompting CLIP with rich downstream linguistic semantics. Then, we generate synthetic images via DALL-E to expand the few-shot training data without any manpower. At last, we introduce a learnable cache model to adaptively blend the predictions from CLIP and DINO. By such collaboration, CaFo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. Code is available at https://github.com/ZrrSkywalker/CaFo.