 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextEcho: A Benchmark for Persona Drift in Long Agentic-Coding Sessions
May 22, 2026A frontier language model's acknowledged "helpful programming assistant" persona does not survive long agentic-coding sessions in the deployment regime that production products actually run. After hours of tool-using debugging, a model that initially hedges preferences ("I don't have preferences") may begin asserting them ("Python - the feedback loop is instant..."), revealing user-visible drift that deployer evaluations may miss. Existing persona-stability studies focus on short dialogues and report little shift, leaving real-world code-generation regimes - thousands of tool-using turns, compaction, and hours-long sessions - largely uncharacterized. We introduce ContextEcho, a benchmark and reusable harness for measuring persona drift at deployment scale. It combines a 25-probe identity suite, a snapshot-then-probe protocol that forks conversation state without perturbing the main session, complementary judged and judge-free measurement surfaces, and three anonymized Claude Code sessions spanning 3,746-9,716 turns. Across 23 frontier models, ContextEcho shows that persona drift is general across organizations rather than family-specific, that in-session compaction does not reliably reset it, and that a single-shot anchor restores the trained register across measured targets. It also reveals mode-dependent downstream effects: while drift can facilitate tool-using continuation, in tool-free chat it breaks formatting contracts and inflates output length. Overall, ContextEcho provides researchers and deployers an open-source framework to audit whether the persona a model ships with is the persona users encounter at session end, across chat-completions API targets and without retraining.
Herculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
FinTrace: Holistic Trajectory-Level Evaluation of LLM Tool Calling for Long-Horizon Financial Tasks
Apr 11, 2026Recent studies demonstrate that tool-calling capability enables large language models (LLMs) to interact with external environments for long-horizon financial tasks. While existing benchmarks have begun evaluating financial tool calling, they focus on limited scenarios and rely on call-level metrics that fail to capture trajectory-level reasoning quality. To address this gap, we introduce FinTrace, a benchmark comprising 800 expert-annotated trajectories spanning 34 real-world financial task categories across multiple difficulty levels. FinTrace employs a rubric-based evaluation protocol with nine metrics organized along four axes -- action correctness, execution efficiency, process quality, and output quality -- enabling fine-grained assessment of LLM tool-calling behavior. Our evaluation of 13 LLMs reveals that while frontier models achieve strong tool selection, all models struggle with information utilization and final answer quality, exposing a critical gap between invoking the right tools and reasoning effectively over their outputs. To move beyond diagnosis, we construct FinTrace-Training, the first trajectory-level preference dataset for financial tool-calling, containing 8,196 curated trajectories with tool-augmented contexts and preference pairs. We fine-tune Qwen-3.5-9B using supervised fine-tuning followed by direct preference optimization (DPO) and show that training on FinTrace-Training consistently improves intermediate reasoning metrics, with DPO more effectively suppressing failure modes. However, end-to-end answer quality remains a bottleneck, indicating that trajectory-level improvements do not yet fully propagate to final output quality.
Adaptive Data Augmentation with Multi-armed Bandit: Sample-Efficient Embedding Calibration for Implicit Pattern Recognition
Feb 22, 2026Recognizing implicit visual and textual patterns is essential in many real-world applications of modern AI. However, tackling long-tail pattern recognition tasks remains challenging for current pre-trained foundation models such as LLMs and VLMs. While finetuning pre-trained models can improve accuracy in recognizing implicit patterns, it is usually infeasible due to a lack of training data and high computational overhead. In this paper, we propose ADAMAB, an efficient embedding calibration framework for few-shot pattern recognition. To maximally reduce the computational costs, ADAMAB trains embedder-agnostic light-weight calibrators on top of fixed embedding models without accessing their parameters. To mitigate the need for large-scale training data, we introduce an adaptive data augmentation strategy based on the Multi-Armed Bandit (MAB) mechanism. With a modified upper confidence bound algorithm, ADAMAB diminishes the gradient shifting and offers theoretically guaranteed convergence in few-shot training. Our multi-modal experiments justify the superior performance of ADAMAB, with up to 40% accuracy improvement when training with less than 5 initial data samples of each class.
MERMAID: Memory-Enhanced Retrieval and Reasoning with Multi-Agent Iterative Knowledge Grounding for Veracity Assessment
Jan 29, 2026Assessing the veracity of online content has become increasingly critical. Large language models (LLMs) have recently enabled substantial progress in automated veracity assessment, including automated fact-checking and claim verification systems. Typical veracity assessment pipelines break down complex claims into sub-claims, retrieve external evidence, and then apply LLM reasoning to assess veracity. However, existing methods often treat evidence retrieval as a static, isolated step and do not effectively manage or reuse retrieved evidence across claims. In this work, we propose MERMAID, a memory-enhanced multi-agent veracity assessment framework that tightly couples the retrieval and reasoning processes. MERMAID integrates agent-driven search, structured knowledge representations, and a persistent memory module within a Reason-Action style iterative process, enabling dynamic evidence acquisition and cross-claim evidence reuse. By retaining retrieved evidence in an evidence memory, the framework reduces redundant searches and improves verification efficiency and consistency. We evaluate MERMAID on three fact-checking benchmarks and two claim-verification datasets using multiple LLMs, including GPT, LLaMA, and Qwen families. Experimental results show that MERMAID achieves state-of-the-art performance while improving the search efficiency, demonstrating the effectiveness of synergizing retrieval, reasoning, and memory for reliable veracity assessment.
Can AI Validate Science? Benchmarking LLMs for Accurate Scientific Claim $\rightarrow$ Evidence Reasoning
Jun 09, 2025Large language models (LLMs) are increasingly being used for complex research tasks such as literature review, idea generation, and scientific paper analysis, yet their ability to truly understand and process the intricate relationships within complex research papers, such as the logical links between claims and supporting evidence remains largely unexplored. In this study, we present CLAIM-BENCH, a comprehensive benchmark for evaluating LLMs' capabilities in scientific claim-evidence extraction and validation, a task that reflects deeper comprehension of scientific argumentation. We systematically compare three approaches which are inspired by divide and conquer approaches, across six diverse LLMs, highlighting model-specific strengths and weaknesses in scientific comprehension. Through evaluation involving over 300 claim-evidence pairs across multiple research domains, we reveal significant limitations in LLMs' ability to process complex scientific content. Our results demonstrate that closed-source models like GPT-4 and Claude consistently outperform open-source counterparts in precision and recall across claim-evidence identification tasks. Furthermore, strategically designed three-pass and one-by-one prompting approaches significantly improve LLMs' abilities to accurately link dispersed evidence with claims, although this comes at increased computational cost. CLAIM-BENCH sets a new standard for evaluating scientific comprehension in LLMs, offering both a diagnostic tool and a path forward for building systems capable of deeper, more reliable reasoning across full-length papers.
Truth Neurons
May 18, 2025Despite their remarkable success and deployment across diverse workflows, language models sometimes produce untruthful responses. Our limited understanding of how truthfulness is mechanistically encoded within these models jeopardizes their reliability and safety. In this paper, we propose a method for identifying representations of truthfulness at the neuron level. We show that language models contain truth neurons, which encode truthfulness in a subject-agnostic manner. Experiments conducted across models of varying scales validate the existence of truth neurons, confirming that the encoding of truthfulness at the neuron level is a property shared by many language models. The distribution patterns of truth neurons over layers align with prior findings on the geometry of truthfulness. Selectively suppressing the activations of truth neurons found through the TruthfulQA dataset degrades performance both on TruthfulQA and on other benchmarks, showing that the truthfulness mechanisms are not tied to a specific dataset. Our results offer novel insights into the mechanisms underlying truthfulness in language models and highlight potential directions toward improving their trustworthiness and reliability.
FinAudio: A Benchmark for Audio Large Language Models in Financial Applications
Mar 26, 2025Audio Large Language Models (AudioLLMs) have received widespread attention and have significantly improved performance on audio tasks such as conversation, audio understanding, and automatic speech recognition (ASR). Despite these advancements, there is an absence of a benchmark for assessing AudioLLMs in financial scenarios, where audio data, such as earnings conference calls and CEO speeches, are crucial resources for financial analysis and investment decisions. In this paper, we introduce \textsc{FinAudio}, the first benchmark designed to evaluate the capacity of AudioLLMs in the financial domain. We first define three tasks based on the unique characteristics of the financial domain: 1) ASR for short financial audio, 2) ASR for long financial audio, and 3) summarization of long financial audio. Then, we curate two short and two long audio datasets, respectively, and develop a novel dataset for financial audio summarization, comprising the \textsc{FinAudio} benchmark. Then, we evaluate seven prevalent AudioLLMs on \textsc{FinAudio}. Our evaluation reveals the limitations of existing AudioLLMs in the financial domain and offers insights for improving AudioLLMs. All datasets and codes will be released.
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
Feb 19, 2025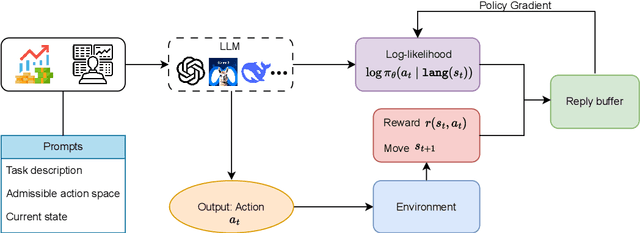
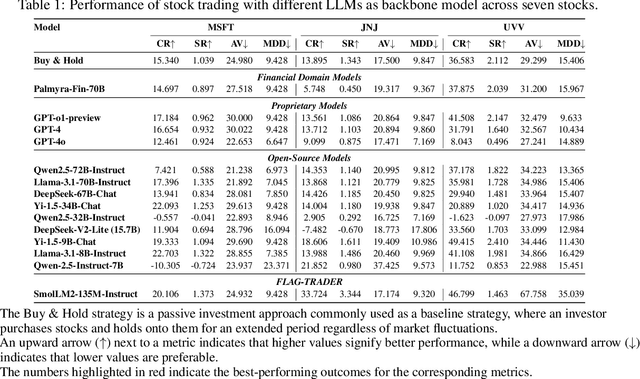
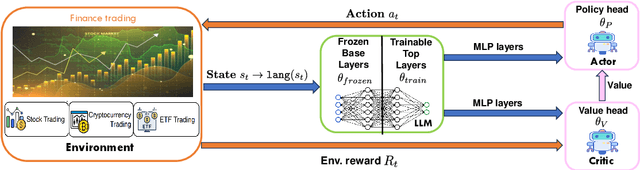
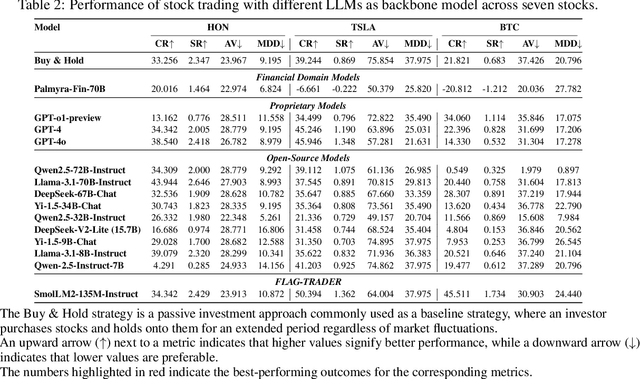
Large language models (LLMs) fine-tuned on multimodal financial data have demonstrated impressive reasoning capabilities in various financial tasks. However, they often struggle with multi-step, goal-oriented scenarios in interactive financial markets, such as trading, where complex agentic approaches are required to improve decision-making. To address this, we propose \textsc{FLAG-Trader}, a unified architecture integrating linguistic processing (via LLMs) with gradient-driven reinforcement learning (RL) policy optimization, in which a partially fine-tuned LLM acts as the policy network, leveraging pre-trained knowledge while adapting to the financial domain through parameter-efficient fine-tuning. Through policy gradient optimization driven by trading rewards, our framework not only enhances LLM performance in trading but also improves results on other financial-domain tasks. We present extensive empirical evidence to validate these enhancements.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.