 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERBA: Verbalizing Model Differences Using Large Language Models
Jul 03, 2025In the current machine learning landscape, we face a "model lake" phenomenon: Given a task, there is a proliferation of trained models with similar performances despite different behavior. For model users attempting to navigate and select from the models, documentation comparing model pairs is helpful. However, for every $N$ models there could be $O(N^2)$ pairwise comparisons, a number prohibitive for the model developers to manually perform pairwise comparisons and prepare documentations. To facilitate fine-grained pairwise comparisons among models, we introduced $\textbf{VERBA}$. Our approach leverages a large language model (LLM) to generate verbalizations of model differences by sampling from the two models. We established a protocol that evaluates the informativeness of the verbalizations via simulation. We also assembled a suite with a diverse set of commonly used machine learning models as a benchmark. For a pair of decision tree models with up to 5% performance difference but 20-25% behavioral differences, $\textbf{VERBA}$ effectively verbalizes their variations with up to 80% overall accuracy. When we included the models' structural information, the verbalization's accuracy further improved to 90%. $\textbf{VERBA}$ opens up new research avenues for improving the transparency and comparability of machine learning models in a post-hoc manner.
Can AI Validate Science? Benchmarking LLMs for Accurate Scientific Claim $\rightarrow$ Evidence Reasoning
Jun 09, 2025Large language models (LLMs) are increasingly being used for complex research tasks such as literature review, idea generation, and scientific paper analysis, yet their ability to truly understand and process the intricate relationships within complex research papers, such as the logical links between claims and supporting evidence remains largely unexplored. In this study, we present CLAIM-BENCH, a comprehensive benchmark for evaluating LLMs' capabilities in scientific claim-evidence extraction and validation, a task that reflects deeper comprehension of scientific argumentation. We systematically compare three approaches which are inspired by divide and conquer approaches, across six diverse LLMs, highlighting model-specific strengths and weaknesses in scientific comprehension. Through evaluation involving over 300 claim-evidence pairs across multiple research domains, we reveal significant limitations in LLMs' ability to process complex scientific content. Our results demonstrate that closed-source models like GPT-4 and Claude consistently outperform open-source counterparts in precision and recall across claim-evidence identification tasks. Furthermore, strategically designed three-pass and one-by-one prompting approaches significantly improve LLMs' abilities to accurately link dispersed evidence with claims, although this comes at increased computational cost. CLAIM-BENCH sets a new standard for evaluating scientific comprehension in LLMs, offering both a diagnostic tool and a path forward for building systems capable of deeper, more reliable reasoning across full-length papers.
FinAudio: A Benchmark for Audio Large Language Models in Financial Applications
Mar 26, 2025Audio Large Language Models (AudioLLMs) have received widespread attention and have significantly improved performance on audio tasks such as conversation, audio understanding, and automatic speech recognition (ASR). Despite these advancements, there is an absence of a benchmark for assessing AudioLLMs in financial scenarios, where audio data, such as earnings conference calls and CEO speeches, are crucial resources for financial analysis and investment decisions. In this paper, we introduce \textsc{FinAudio}, the first benchmark designed to evaluate the capacity of AudioLLMs in the financial domain. We first define three tasks based on the unique characteristics of the financial domain: 1) ASR for short financial audio, 2) ASR for long financial audio, and 3) summarization of long financial audio. Then, we curate two short and two long audio datasets, respectively, and develop a novel dataset for financial audio summarization, comprising the \textsc{FinAudio} benchmark. Then, we evaluate seven prevalent AudioLLMs on \textsc{FinAudio}. Our evaluation reveals the limitations of existing AudioLLMs in the financial domain and offers insights for improving AudioLLMs. All datasets and codes will be released.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.
LLM-Generated Black-box Explanations Can Be Adversarially Helpful
May 10, 2024Large Language Models (LLMs) are becoming vital tools that help us solve and understand complex problems by acting as digital assistants. LLMs can generate convincing explanations, even when only given the inputs and outputs of these problems, i.e., in a ``black-box'' approach. However, our research uncovers a hidden risk tied to this approach, which we call *adversarial helpfulness*. This happens when an LLM's explanations make a wrong answer look right, potentially leading people to trust incorrect solutions. In this paper, we show that this issue affects not just humans, but also LLM evaluators. Digging deeper, we identify and examine key persuasive strategies employed by LLMs. Our findings reveal that these models employ strategies such as reframing the questions, expressing an elevated level of confidence, and cherry-picking evidence to paint misleading answers in a credible light. To examine if LLMs are able to navigate complex-structured knowledge when generating adversarially helpful explanations, we create a special task based on navigating through graphs. Some LLMs are not able to find alternative paths along simple graphs, indicating that their misleading explanations aren't produced by only logical deductions using complex knowledge. These findings shed light on the limitations of black-box explanation setting. We provide some advice on how to use LLMs as explainers safely.
A Comparative and Experimental Study on Automatic Question Answering Systems and its Robustness against Word Jumbling
Nov 27, 2023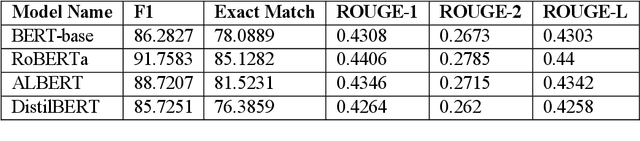
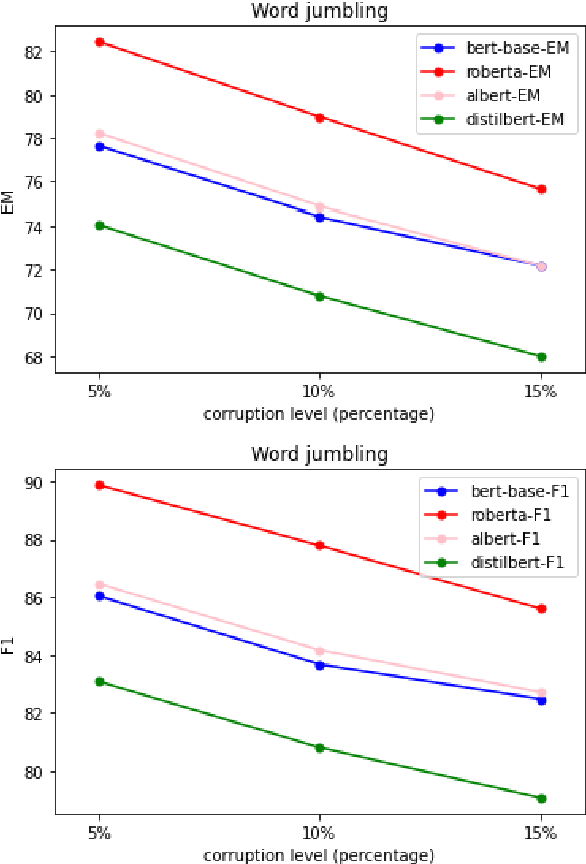
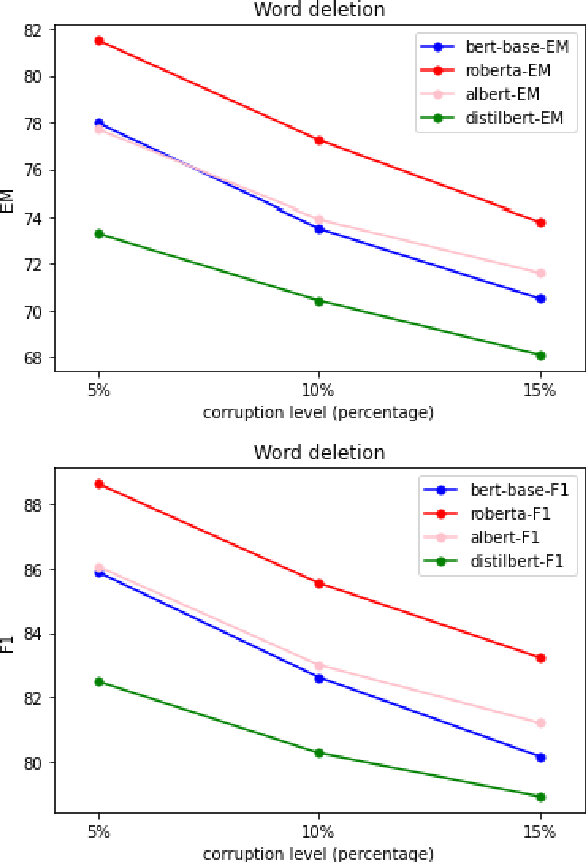

Question answer generation using Natural Language Processing models is ubiquitous in the world around us. It is used in many use cases such as the building of chat bots, suggestive prompts in google search and also as a way of navigating information in banking mobile applications etc. It is highly relevant because a frequently asked questions (FAQ) list can only have a finite amount of questions but a model which can perform question answer generation could be able to answer completely new questions that are within the scope of the data. This helps us to be able to answer new questions accurately as long as it is a relevant question. In commercial applications, it can be used to increase customer satisfaction and ease of usage. However a lot of data is generated by humans so it is susceptible to human error and this can adversely affect the model's performance and we are investigating this through our work
Question-focused Summarization by Decomposing Articles into Facts and Opinions and Retrieving Entities
Oct 07, 2023


This research focuses on utilizing natural language processing techniques to predict stock price fluctuations, with a specific interest in early detection of economic, political, social, and technological changes that can be leveraged for capturing market opportunities. The proposed approach includes the identification of salient facts and events from news articles, then use these facts to form tuples with entities which can be used to get summaries of market changes for particular entity and then finally combining all the summaries to form a final abstract summary of the whole article. The research aims to establish relationships between companies and entities through the analysis of Wikipedia data and articles from the Economist. Large Language Model GPT 3.5 is used for getting the summaries and also forming the final summary. The ultimate goal of this research is to develop a comprehensive system that can provide financial analysts and investors with more informed decision-making tools by enabling early detection of market trends and events.
Hybrid Recommendation System using Graph Neural Network and BERT Embeddings
Oct 07, 2023
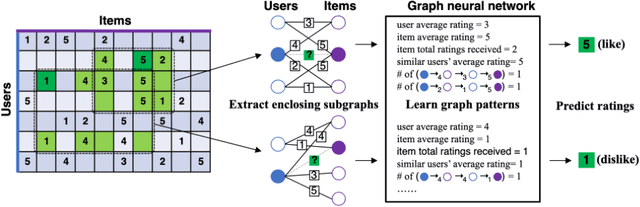
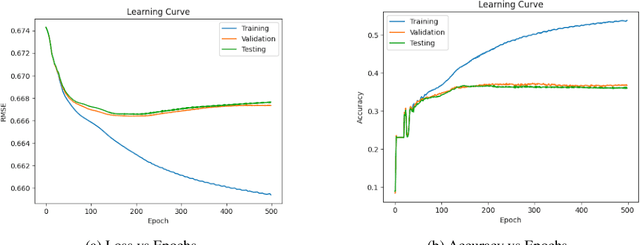
Recommender systems have emerged as a crucial component of the modern web ecosystem. The effectiveness and accuracy of such systems are critical for providing users with personalized recommendations that meet their specific interests and needs. In this paper, we introduce a novel model that utilizes a Graph Neural Network (GNN) in conjunction with sentence transformer embeddings to predict anime recommendations for different users. Our model employs the task of link prediction to create a recommendation system that considers both the features of anime and user interactions with different anime. The hybridization of the GNN and transformer embeddings enables us to capture both inter-level and intra-level features of anime data.Our model not only recommends anime to users but also predicts the rating a specific user would give to an anime. We utilize the GraphSAGE network for model building and weighted root mean square error (RMSE) to evaluate the performance of the model. Our approach has the potential to significantly enhance the accuracy and effectiveness of anime recommendation systems and can be extended to other domains that require personalized recommendations.
Multi-BERT for Embeddings for Recommendation System
Aug 24, 2023In this paper, we propose a novel approach for generating document embeddings using a combination of Sentence-BERT (SBERT) and RoBERTa, two state-of-the-art natural language processing models. Our approach treats sentences as tokens and generates embeddings for them, allowing the model to capture both intra-sentence and inter-sentence relations within a document. We evaluate our model on a book recommendation task and demonstrate its effectiveness in generating more semantically rich and accurate document embeddings. To assess the performance of our approach, we conducted experiments on a book recommendation task using the Goodreads dataset. We compared the document embeddings generated using our MULTI-BERT model to those generated using SBERT alone. We used precision as our evaluation metric to compare the quality of the generated embeddings. Our results showed that our model consistently outperformed SBERT in terms of the quality of the generated embeddings. Furthermore, we found that our model was able to capture more nuanced semantic relations within documents, leading to more accurate recommendations. Overall, our results demonstrate the effectiveness of our approach and suggest that it is a promising direction for improving the performance of recommendation systems
Hybrid Genetic Algorithm and Hill Climbing Optimization for the Neural Network
Aug 24, 2023In this paper, we propose a hybrid model combining genetic algorithm and hill climbing algorithm for optimizing Convolutional Neural Networks (CNNs) on the CIFAR-100 dataset. The proposed model utilizes a population of chromosomes that represent the hyperparameters of the CNN model. The genetic algorithm is used for selecting and breeding the fittest chromosomes to generate new offspring. The hill climbing algorithm is then applied to the offspring to further optimize their hyperparameters. The mutation operation is introduced to diversify the population and to prevent the algorithm from getting stuck in local optima. The Genetic Algorithm is used for global search and exploration of the search space, while Hill Climbing is used for local optimization of promising solutions. The objective function is the accuracy of the trained neural network on the CIFAR-100 test set. The performance of the hybrid model is evaluated by comparing it with the standard genetic algorithm and hill-climbing algorithm. The experimental results demonstrate that the proposed hybrid model achieves better accuracy with fewer generations compared to the standard algorithms. Therefore, the proposed hybrid model can be a promising approach for optimizing CNN models on large datasets.