 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Facility Location in Ethiopia: Leveraging LLMs to Integrate Expert Knowledge into Algorithmic Planning
Jan 16, 2026Ethiopia's Ministry of Health is upgrading health posts to improve access to essential services, particularly in rural areas. Limited resources, however, require careful prioritization of which facilities to upgrade to maximize population coverage while accounting for diverse expert and stakeholder preferences. In collaboration with the Ethiopian Public Health Institute and Ministry of Health, we propose a hybrid framework that systematically integrates expert knowledge with optimization techniques. Classical optimization methods provide theoretical guarantees but require explicit, quantitative objectives, whereas stakeholder criteria are often articulated in natural language and difficult to formalize. To bridge these domains, we develop the Large language model and Extended Greedy (LEG) framework. Our framework combines a provable approximation algorithm for population coverage optimization with LLM-driven iterative refinement that incorporates human-AI alignment to ensure solutions reflect expert qualitative guidance while preserving coverage guarantees. Experiments on real-world data from three Ethiopian regions demonstrate the framework's effectiveness and its potential to inform equitable, data-driven health system planning.
FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR Evaluation
Nov 19, 2025We introduce FinCriticalED (Financial Critical Error Detection), a visual benchmark for evaluating OCR and vision language models on financial documents at the fact level. Financial documents contain visually dense and table heavy layouts where numerical and temporal information is tightly coupled with structure. In high stakes settings, small OCR mistakes such as sign inversion or shifted dates can lead to materially different interpretations, while traditional OCR metrics like ROUGE and edit distance capture only surface level text similarity. \ficriticaled provides 500 image-HTML pairs with expert annotated financial facts covering over seven hundred numerical and temporal facts. It introduces three key contributions. First, it establishes the first fact level evaluation benchmark for financial document understanding, shifting evaluation from lexical overlap to domain critical factual correctness. Second, all annotations are created and verified by financial experts with strict quality control over signs, magnitudes, and temporal expressions. Third, we develop an LLM-as-Judge evaluation pipeline that performs structured fact extraction and contextual verification for visually complex financial documents. We benchmark OCR systems, open source vision language models, and proprietary models on FinCriticalED. Results show that although the strongest proprietary models achieve the highest factual accuracy, substantial errors remain in visually intricate numerical and temporal contexts. Through quantitative evaluation and expert case studies, FinCriticalED provides a rigorous foundation for advancing visual factual precision in financial and other precision critical domains.
MeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.
Composite Flow Matching for Reinforcement Learning with Shifted-Dynamics Data
May 29, 2025Incorporating pre-collected offline data from a source environment can significantly improve the sample efficiency of reinforcement learning (RL), but this benefit is often challenged by discrepancies between the transition dynamics of the source and target environments. Existing methods typically address this issue by penalizing or filtering out source transitions in high dynamics-gap regions. However, their estimation of the dynamics gap often relies on KL divergence or mutual information, which can be ill-defined when the source and target dynamics have disjoint support. To overcome these limitations, we propose CompFlow, a method grounded in the theoretical connection between flow matching and optimal transport. Specifically, we model the target dynamics as a conditional flow built upon the output distribution of the source-domain flow, rather than learning it directly from a Gaussian prior. This composite structure offers two key advantages: (1) improved generalization for learning target dynamics, and (2) a principled estimation of the dynamics gap via the Wasserstein distance between source and target transitions. Leveraging our principled estimation of the dynamics gap, we further introduce an optimistic active data collection strategy that prioritizes exploration in regions of high dynamics gap, and theoretically prove that it reduces the performance disparity with the optimal policy. Empirically, CompFlow outperforms strong baselines across several RL benchmarks with shifted dynamics.
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
Feb 19, 2025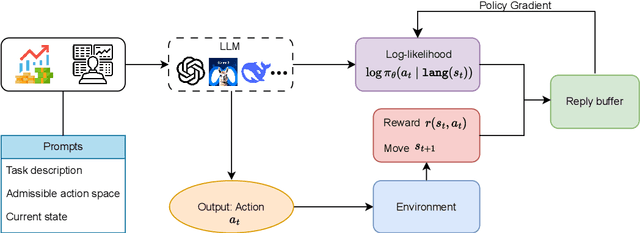
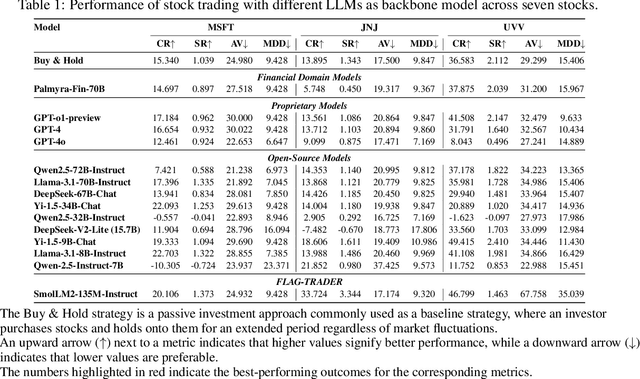
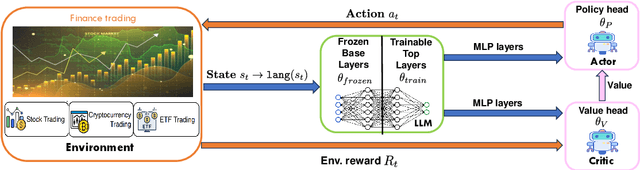
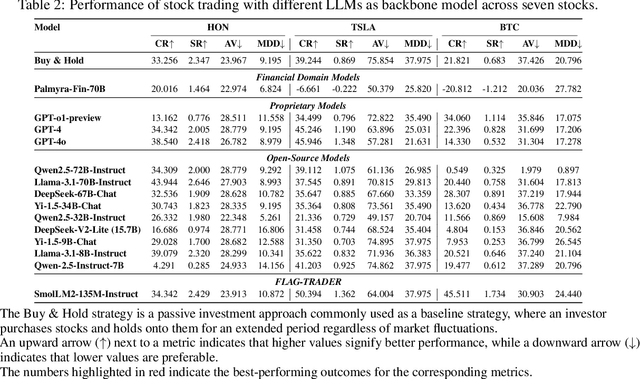
Large language models (LLMs) fine-tuned on multimodal financial data have demonstrated impressive reasoning capabilities in various financial tasks. However, they often struggle with multi-step, goal-oriented scenarios in interactive financial markets, such as trading, where complex agentic approaches are required to improve decision-making. To address this, we propose \textsc{FLAG-Trader}, a unified architecture integrating linguistic processing (via LLMs) with gradient-driven reinforcement learning (RL) policy optimization, in which a partially fine-tuned LLM acts as the policy network, leveraging pre-trained knowledge while adapting to the financial domain through parameter-efficient fine-tuning. Through policy gradient optimization driven by trading rewards, our framework not only enhances LLM performance in trading but also improves results on other financial-domain tasks. We present extensive empirical evidence to validate these enhancements.
Finite-Horizon Single-Pull Restless Bandits: An Efficient Index Policy For Scarce Resource Allocation
Jan 10, 2025Restless multi-armed bandits (RMABs) have been highly successful in optimizing sequential resource allocation across many domains. However, in many practical settings with highly scarce resources, where each agent can only receive at most one resource, such as healthcare intervention programs, the standard RMAB framework falls short. To tackle such scenarios, we introduce Finite-Horizon Single-Pull RMABs (SPRMABs), a novel variant in which each arm can only be pulled once. This single-pull constraint introduces additional complexity, rendering many existing RMAB solutions suboptimal or ineffective. %To address this, we propose using dummy states to duplicate the system, ensuring that once an arm is activated, it transitions exclusively within the dummy states. To address this shortcoming, we propose using \textit{dummy states} that expand the system and enforce the one-pull constraint. We then design a lightweight index policy for this expanded system. For the first time, we demonstrate that our index policy achieves a sub-linearly decaying average optimality gap of $\tilde{\mathcal{O}}\left(\frac{1}{\rho^{1/2}}\right)$ for a finite number of arms, where $\rho$ is the scaling factor for each arm cluster. Extensive simulations validate the proposed method, showing robust performance across various domains compared to existing benchmarks.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.
On the Linear Speedup of Personalized Federated Reinforcement Learning with Shared Representations
Nov 22, 2024Federated reinforcement learning (FedRL) enables multiple agents to collaboratively learn a policy without sharing their local trajectories collected during agent-environment interactions. However, in practice, the environments faced by different agents are often heterogeneous, leading to poor performance by the single policy learned by existing FedRL algorithms on individual agents. In this paper, we take a further step and introduce a \emph{personalized} FedRL framework (PFedRL) by taking advantage of possibly shared common structure among agents in heterogeneous environments. Specifically, we develop a class of PFedRL algorithms named PFedRL-Rep that learns (1) a shared feature representation collaboratively among all agents, and (2) an agent-specific weight vector personalized to its local environment. We analyze the convergence of PFedTD-Rep, a particular instance of the framework with temporal difference (TD) learning and linear representations. To the best of our knowledge, we are the first to prove a linear convergence speedup with respect to the number of agents in the PFedRL setting. To achieve this, we show that PFedTD-Rep is an example of the federated two-timescale stochastic approximation with Markovian noise. Experimental results demonstrate that PFedTD-Rep, along with an extension to the control setting based on deep Q-networks (DQN), not only improve learning in heterogeneous settings, but also provide better generalization to new environments.
Optimizing Vital Sign Monitoring in Resource-Constrained Maternal Care: An RL-Based Restless Bandit Approach
Oct 10, 2024

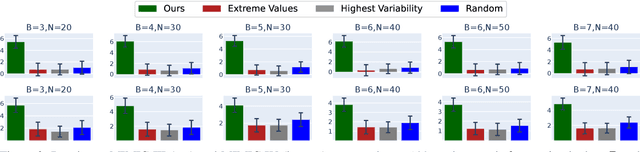
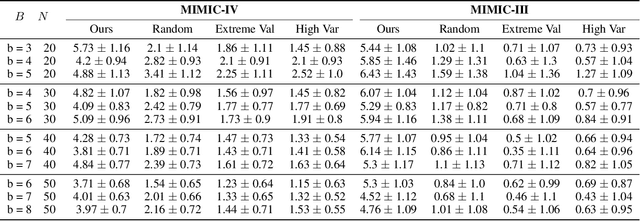
Maternal mortality remains a significant global public health challenge. One promising approach to reducing maternal deaths occurring during facility-based childbirth is through early warning systems, which require the consistent monitoring of mothers' vital signs after giving birth. Wireless vital sign monitoring devices offer a labor-efficient solution for continuous monitoring, but their scarcity raises the critical question of how to allocate them most effectively. We devise an allocation algorithm for this problem by modeling it as a variant of the popular Restless Multi-Armed Bandit (RMAB) paradigm. In doing so, we identify and address novel, previously unstudied constraints unique to this domain, which render previous approaches for RMABs unsuitable and significantly increase the complexity of the learning and planning problem. To overcome these challenges, we adopt the popular Proximal Policy Optimization (PPO) algorithm from reinforcement learning to learn an allocation policy by training a policy and value function network. We demonstrate in simulations that our approach outperforms the best heuristic baseline by up to a factor of $4$.
DOPL: Direct Online Preference Learning for Restless Bandits with Preference Feedback
Oct 07, 2024



Restless multi-armed bandits (RMAB) has been widely used to model constrained sequential decision making problems, where the state of each restless arm evolves according to a Markov chain and each state transition generates a scalar reward. However, the success of RMAB crucially relies on the availability and quality of reward signals. Unfortunately, specifying an exact reward function in practice can be challenging and even infeasible. In this paper, we introduce Pref-RMAB, a new RMAB model in the presence of preference signals, where the decision maker only observes pairwise preference feedback rather than scalar reward from the activated arms at each decision epoch. Preference feedback, however, arguably contains less information than the scalar reward, which makes Pref-RMAB seemingly more difficult. To address this challenge, we present a direct online preference learning (DOPL) algorithm for Pref-RMAB to efficiently explore the unknown environments, adaptively collect preference data in an online manner, and directly leverage the preference feedback for decision-makings. We prove that DOPL yields a sublinear regret. To our best knowledge, this is the first algorithm to ensure $\tilde{\mathcal{O}}(\sqrt{T\ln T})$ regret for RMAB with preference feedback. Experimental results further demonstrate the effectiveness of DOPL.