 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePITA: Preference-Guided Inference-Time Alignment for LLM Post-Training
Jul 26, 2025Inference-time alignment enables large language models (LLMs) to generate outputs aligned with end-user preferences without further training. Recent post-training methods achieve this by using small guidance models to modify token generation during inference. These methods typically optimize a reward function KL-regularized by the original LLM taken as the reference policy. A critical limitation, however, is their dependence on a pre-trained reward model, which requires fitting to human preference feedback--a potentially unstable process. In contrast, we introduce PITA, a novel framework that integrates preference feedback directly into the LLM's token generation, eliminating the need for a reward model. PITA learns a small preference-based guidance policy to modify token probabilities at inference time without LLM fine-tuning, reducing computational cost and bypassing the pre-trained reward model dependency. The problem is framed as identifying an underlying preference distribution, solved through stochastic search and iterative refinement of the preference-based guidance model. We evaluate PITA across diverse tasks, including mathematical reasoning and sentiment classification, demonstrating its effectiveness in aligning LLM outputs with user preferences.
Risk-Averse Finetuning of Large Language Models
Jan 12, 2025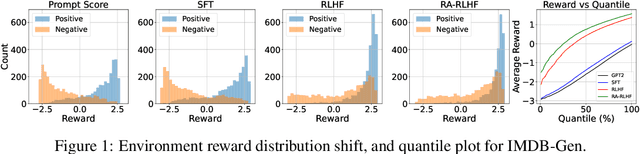
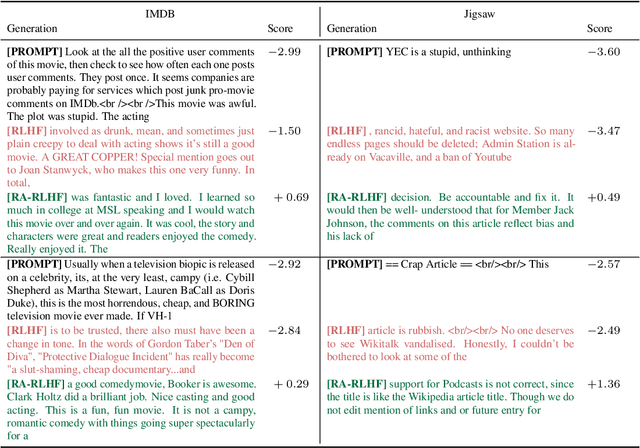
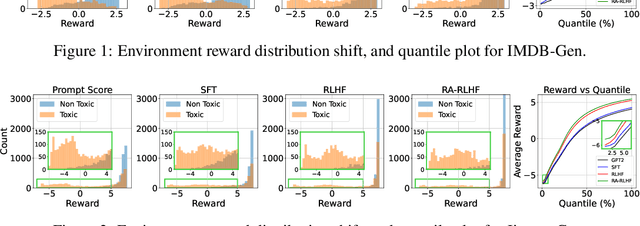
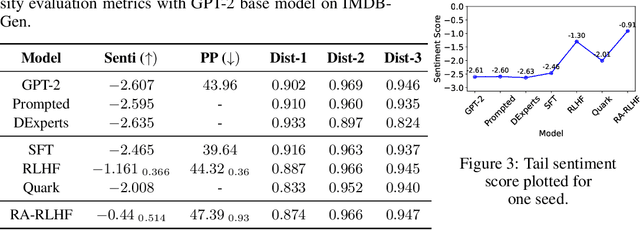
We consider the challenge of mitigating the generation of negative or toxic content by the Large Language Models (LLMs) in response to certain prompts. We propose integrating risk-averse principles into LLM fine-tuning to minimize the occurrence of harmful outputs, particularly rare but significant events. By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks. Empirical evaluations on sentiment modification and toxicity mitigation tasks demonstrate the efficacy of risk-averse reinforcement learning with human feedback (RLHF) in promoting a safer and more constructive online discourse environment.
DOPL: Direct Online Preference Learning for Restless Bandits with Preference Feedback
Oct 07, 2024



Restless multi-armed bandits (RMAB) has been widely used to model constrained sequential decision making problems, where the state of each restless arm evolves according to a Markov chain and each state transition generates a scalar reward. However, the success of RMAB crucially relies on the availability and quality of reward signals. Unfortunately, specifying an exact reward function in practice can be challenging and even infeasible. In this paper, we introduce Pref-RMAB, a new RMAB model in the presence of preference signals, where the decision maker only observes pairwise preference feedback rather than scalar reward from the activated arms at each decision epoch. Preference feedback, however, arguably contains less information than the scalar reward, which makes Pref-RMAB seemingly more difficult. To address this challenge, we present a direct online preference learning (DOPL) algorithm for Pref-RMAB to efficiently explore the unknown environments, adaptively collect preference data in an online manner, and directly leverage the preference feedback for decision-makings. We prove that DOPL yields a sublinear regret. To our best knowledge, this is the first algorithm to ensure $\tilde{\mathcal{O}}(\sqrt{T\ln T})$ regret for RMAB with preference feedback. Experimental results further demonstrate the effectiveness of DOPL.
CVLight: Deep Reinforcement Learning for Adaptive Traffic Signal Control with Connected Vehicles
Apr 21, 2021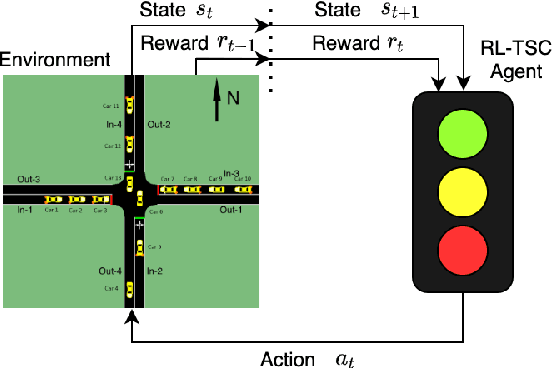
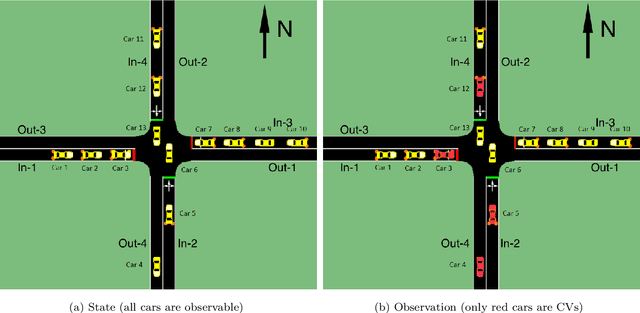

This paper develops a reinforcement learning (RL) scheme for adaptive traffic signal control (ATSC), called "CVLight", that leverages data collected only from connected vehicles (CV). Seven types of RL models are proposed within this scheme that contain various state and reward representations, including incorporation of CV delay and green light duration into state and the usage of CV delay as reward. To further incorporate information of both CV and non-CV into CVLight, an algorithm based on actor-critic, A2C-Full, is proposed where both CV and non-CV information is used to train the critic network, while only CV information is used to update the policy network and execute optimal signal timing. These models are compared at an isolated intersection under various CV market penetration rates. A full model with the best performance (i.e., minimum average travel delay per vehicle) is then selected and applied to compare with state-of-the-art benchmarks under different levels of traffic demands, turning proportions, and dynamic traffic demands, respectively. Two case studies are performed on an isolated intersection and a corridor with three consecutive intersections located in Manhattan, New York, to further demonstrate the effectiveness of the proposed algorithm under real-world scenarios. Compared to other baseline models that use all vehicle information, the trained CVLight agent can efficiently control multiple intersections solely based on CV data and can achieve a similar or even greater performance when the CV penetration rate is no less than 20%.