 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Axe: A Simple Unified Layout Abstraction for Machine Learning Compilers
Jan 27, 2026Scaling modern deep learning workloads demands coordinated placement of data and compute across device meshes, memory hierarchies, and heterogeneous accelerators. We present Axe Layout, a hardware-aware abstraction that maps logical tensor coordinates to a multi-axis physical space via named axes. Axe unifies tiling, sharding, replication, and offsets across inter-device distribution and on-device layouts, enabling collective primitives to be expressed consistently from device meshes to threads. Building on Axe, we design a multi-granularity, distribution-aware DSL and compiler that composes thread-local control with collective operators in a single kernel. Experiments show that our unified approach can bring performance close to hand-tuned kernels on across latest GPU devices and multi-device environments and accelerator backends.
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
Nov 22, 2024



The applications of LLM Agents are becoming increasingly complex and diverse, leading to a high demand for structured outputs that can be parsed into code, structured function calls, and embodied agent commands. These developments bring significant demands for structured generation in LLM inference. Context-free grammar is a flexible approach to enable structured generation via constrained decoding. However, executing context-free grammar requires going through several stack states over all tokens in vocabulary during runtime, bringing non-negligible overhead for structured generation. In this paper, we propose XGrammar, a flexible and efficient structure generation engine for large language models. XGrammar accelerates context-free grammar execution by dividing the vocabulary into context-independent tokens that can be prechecked and context-dependent tokens that need to be interpreted during runtime. We further build transformations to expand the grammar context and reduce the number of context-independent tokens. Additionally, we build an efficient persistent stack to accelerate the context-dependent token checks. Finally, we co-design the grammar engine with LLM inference engine to overlap grammar computation with GPU executions. Evaluation results show that XGrammar can achieve up to 100x speedup over existing solutions. Combined with an LLM inference engine, it can generate near-zero overhead structure generation in end-to-end low-LLM serving.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
CVLight: Deep Reinforcement Learning for Adaptive Traffic Signal Control with Connected Vehicles
Apr 21, 2021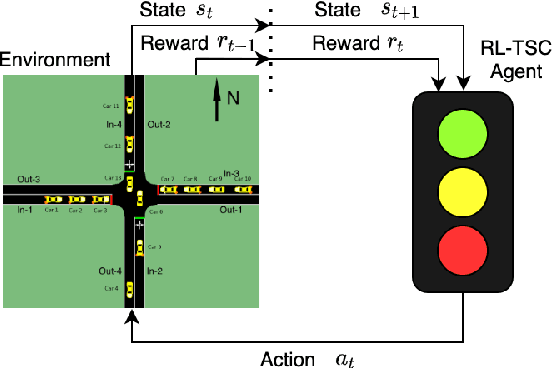
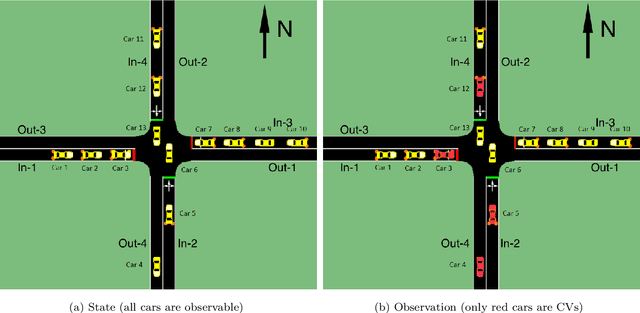

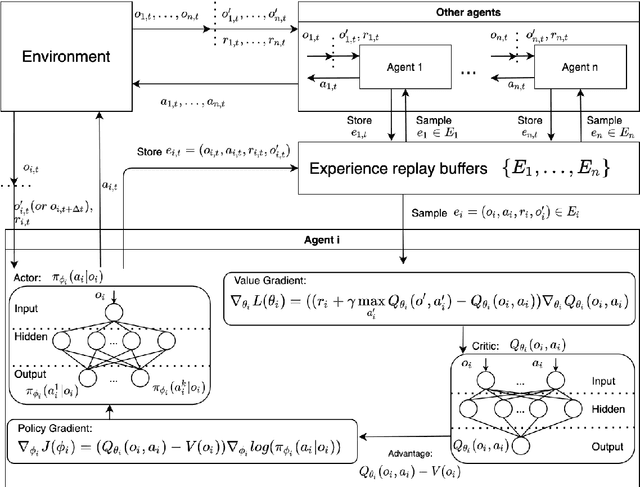
This paper develops a reinforcement learning (RL) scheme for adaptive traffic signal control (ATSC), called "CVLight", that leverages data collected only from connected vehicles (CV). Seven types of RL models are proposed within this scheme that contain various state and reward representations, including incorporation of CV delay and green light duration into state and the usage of CV delay as reward. To further incorporate information of both CV and non-CV into CVLight, an algorithm based on actor-critic, A2C-Full, is proposed where both CV and non-CV information is used to train the critic network, while only CV information is used to update the policy network and execute optimal signal timing. These models are compared at an isolated intersection under various CV market penetration rates. A full model with the best performance (i.e., minimum average travel delay per vehicle) is then selected and applied to compare with state-of-the-art benchmarks under different levels of traffic demands, turning proportions, and dynamic traffic demands, respectively. Two case studies are performed on an isolated intersection and a corridor with three consecutive intersections located in Manhattan, New York, to further demonstrate the effectiveness of the proposed algorithm under real-world scenarios. Compared to other baseline models that use all vehicle information, the trained CVLight agent can efficiently control multiple intersections solely based on CV data and can achieve a similar or even greater performance when the CV penetration rate is no less than 20%.