 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVIP: Towards Verifiable Inference of Open-source Large Language Models
Oct 29, 2024Open-source Large Language Models (LLMs) have recently demonstrated remarkable capabilities in natural language understanding and generation, leading to widespread adoption across various domains. However, their increasing model sizes render local deployment impractical for individual users, pushing many to rely on computing service providers for inference through a blackbox API. This reliance introduces a new risk: a computing provider may stealthily substitute the requested LLM with a smaller, less capable model without consent from users, thereby delivering inferior outputs while benefiting from cost savings. In this paper, we formalize the problem of verifiable inference for LLMs. Existing verifiable computing solutions based on cryptographic or game-theoretic techniques are either computationally uneconomical or rest on strong assumptions. We introduce SVIP, a secret-based verifiable LLM inference protocol that leverages intermediate outputs from LLM as unique model identifiers. By training a proxy task on these outputs and requiring the computing provider to return both the generated text and the processed intermediate outputs, users can reliably verify whether the computing provider is acting honestly. In addition, the integration of a secret mechanism further enhances the security of our protocol. We thoroughly analyze our protocol under multiple strong and adaptive adversarial scenarios. Our extensive experiments demonstrate that SVIP is accurate, generalizable, computationally efficient, and resistant to various attacks. Notably, SVIP achieves false negative rates below 5% and false positive rates below 3%, while requiring less than 0.01 seconds per query for verification.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
AutoLRS: Automatic Learning-Rate Schedule by Bayesian Optimization on the Fly
May 22, 2021
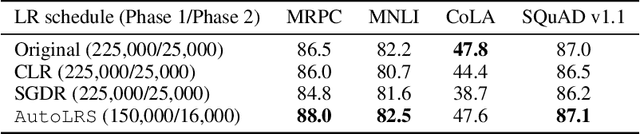
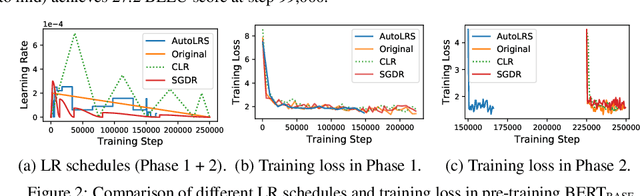

The learning rate (LR) schedule is one of the most important hyper-parameters needing careful tuning in training DNNs. However, it is also one of the least automated parts of machine learning systems and usually costs significant manual effort and computing. Though there are pre-defined LR schedules and optimizers with adaptive LR, they introduce new hyperparameters that need to be tuned separately for different tasks/datasets. In this paper, we consider the question: Can we automatically tune the LR over the course of training without human involvement? We propose an efficient method, AutoLRS, which automatically optimizes the LR for each training stage by modeling training dynamics. AutoLRS aims to find an LR applied to every $\tau$ steps that minimizes the resulted validation loss. We solve this black-box optimization on the fly by Bayesian optimization (BO). However, collecting training instances for BO requires a system to evaluate each LR queried by BO's acquisition function for $\tau$ steps, which is prohibitively expensive in practice. Instead, we apply each candidate LR for only $\tau'\ll\tau$ steps and train an exponential model to predict the validation loss after $\tau$ steps. This mutual-training process between BO and the loss-prediction model allows us to limit the training steps invested in the BO search. We demonstrate the advantages and the generality of AutoLRS through extensive experiments of training DNNs for tasks from diverse domains using different optimizers. The LR schedules auto-generated by AutoLRS lead to a speedup of $1.22\times$, $1.43\times$, and $1.5\times$ when training ResNet-50, Transformer, and BERT, respectively, compared to the LR schedules in their original papers, and an average speedup of $1.31\times$ over state-of-the-art heavily-tuned LR schedules.
Progressive transfer learning for low frequency data prediction in full waveform inversion
Dec 20, 2019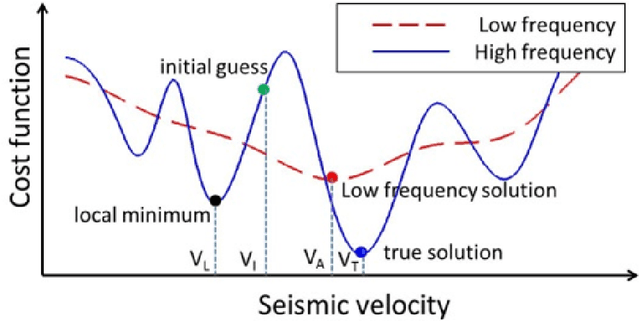
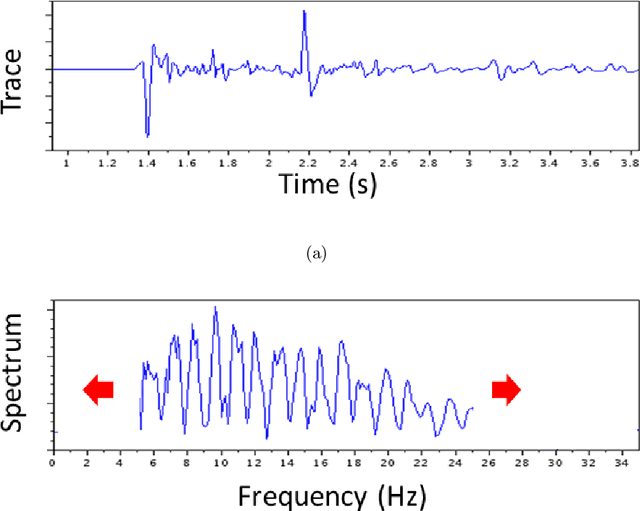
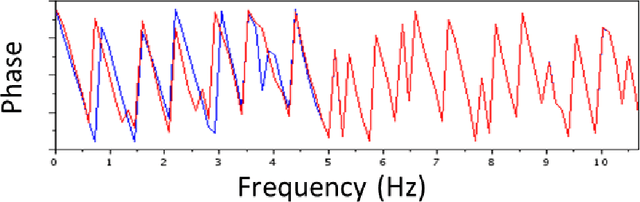
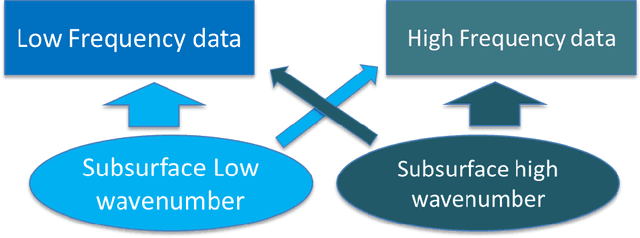
For the purpose of effective suppression of the cycle-skipping phenomenon in full waveform inversion (FWI), we developed a Deep Neural Network (DNN) approach to predict the absent low-frequency components by exploiting the implicit relation connecting the low-frequency and high-frequency data through the subsurface geological and geophysical properties. In order to solve this challenging nonlinear regression problem, two novel strategies were proposed to design the DNN architecture and the learning workflow: 1) Dual Data Feed; 2) Progressive Transfer Learning. With the Dual Data Feed structure, both the high-frequency data and the corresponding Beat Tone data are fed into the DNN to relieve the burden of feature extraction, thus reducing the network complexity and the training cost. The second strategy, Progressive Transfer Learning, enables us to unbiasedly train the DNN using a single training dataset. Unlike most established deep learning approaches where the training datasets are fixed, within the framework of the Progressive Transfer Learning, the training dataset evolves in an iterative manner while gradually absorbing the subsurface information retrieved by the physics-based inversion module, progressively enhancing the prediction accuracy of the DNN and propelling the FWI process out of the local minima. The Progressive Transfer Learning, alternatingly updating the training velocity model and the DNN parameters in a complementary fashion toward convergence, saves us from being overwhelmed by the otherwise tremendous amount of training data, and avoids the underfitting and biased sampling issues. The numerical experiments validated that, without any a priori geological information, the low-frequency data predicted by the Progressive Transfer Learning are sufficiently accurate for an FWI engine to produce reliable subsurface velocity models free of cycle-skipping-induced artifacts.