 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics
Jan 20, 2026Agentic systems have recently become the dominant paradigm for formal theorem proving, achieving strong performance by coordinating multiple models and tools. However, existing approaches often rely on task-specific pipelines and trained formal provers, limiting their flexibility and reproducibility. In this paper, we propose the paradigm that directly uses a general coding agent as a formal math reasoner. This paradigm is motivated by (1) A general coding agent provides a natural interface for diverse reasoning tasks beyond proving, (2) Performance can be improved by simply replacing the underlying base model, without training, and (3) MCP enables flexible extension and autonomous calling of specialized tools, avoiding complex design. Based on this paradigm, we introduce Numina-Lean-Agent, which combines Claude Code with Numina-Lean-MCP to enable autonomous interaction with Lean, retrieval of relevant theorems, informal proving and auxiliary reasoning tools. Using Claude Opus 4.5 as the base model, Numina-Lean-Agent solves all problems in Putnam 2025 (12 / 12), matching the best closed-source system. Beyond benchmark evaluation, we further demonstrate its generality by interacting with mathematicians to successfully formalize the Brascamp-Lieb theorem. We release Numina-Lean-Agent and all solutions at https://github.com/project-numina/numina-lean-agent.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
RobustMask: Certified Robustness against Adversarial Neural Ranking Attack via Randomized Masking
Dec 29, 2025Neural ranking models have achieved remarkable progress and are now widely deployed in real-world applications such as Retrieval-Augmented Generation (RAG). However, like other neural architectures, they remain vulnerable to adversarial manipulations: subtle character-, word-, or phrase-level perturbations can poison retrieval results and artificially promote targeted candidates, undermining the integrity of search engines and downstream systems. Existing defenses either rely on heuristics with poor generalization or on certified methods that assume overly strong adversarial knowledge, limiting their practical use. To address these challenges, we propose RobustMask, a novel defense that combines the context-prediction capability of pretrained language models with a randomized masking-based smoothing mechanism. Our approach strengthens neural ranking models against adversarial perturbations at the character, word, and phrase levels. Leveraging both the pairwise comparison ability of ranking models and probabilistic statistical analysis, we provide a theoretical proof of RobustMask's certified top-K robustness. Extensive experiments further demonstrate that RobustMask successfully certifies over 20% of candidate documents within the top-10 ranking positions against adversarial perturbations affecting up to 30% of their content. These results highlight the effectiveness of RobustMask in enhancing the adversarial robustness of neural ranking models, marking a significant step toward providing stronger security guarantees for real-world retrieval systems.
DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
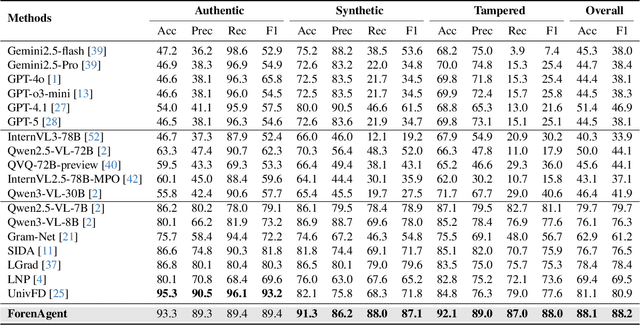
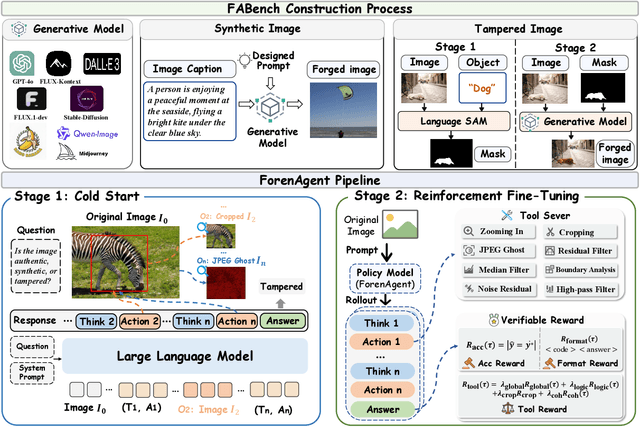
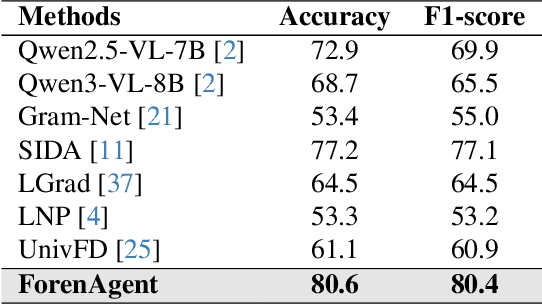
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
TMUAD: Enhancing Logical Capabilities in Unified Anomaly Detection Models with a Text Memory Bank
Aug 29, 2025Anomaly detection, which aims to identify anomalies deviating from normal patterns, is challenging due to the limited amount of normal data available. Unlike most existing unified methods that rely on carefully designed image feature extractors and memory banks to capture logical relationships between objects, we introduce a text memory bank to enhance the detection of logical anomalies. Specifically, we propose a Three-Memory framework for Unified structural and logical Anomaly Detection (TMUAD). First, we build a class-level text memory bank for logical anomaly detection by the proposed logic-aware text extractor, which can capture rich logical descriptions of objects from input images. Second, we construct an object-level image memory bank that preserves complete object contours by extracting features from segmented objects. Third, we employ visual encoders to extract patch-level image features for constructing a patch-level memory bank for structural anomaly detection. These three complementary memory banks are used to retrieve and compare normal images that are most similar to the query image, compute anomaly scores at multiple levels, and fuse them into a final anomaly score. By unifying structural and logical anomaly detection through collaborative memory banks, TMUAD achieves state-of-the-art performance across seven publicly available datasets involving industrial and medical domains. The model and code are available at https://github.com/SIA-IDE/TMUAD.
Agentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
Jul 24, 2025Large Language Models (LLMs) exhibit considerable promise in financial applications; however, prevailing models frequently demonstrate limitations when confronted with scenarios that necessitate sophisticated reasoning capabilities, stringent trustworthiness criteria, and efficient adaptation to domain-specific requirements. We introduce the Agentar-Fin-R1 series of financial large language models (8B and 32B parameters), specifically engineered based on the Qwen3 foundation model to enhance reasoning capabilities, reliability, and domain specialization for financial applications. Our optimization approach integrates a high-quality, systematic financial task label system with a comprehensive multi-layered trustworthiness assurance framework. This framework encompasses high-quality trustworthy knowledge engineering, multi-agent trustworthy data synthesis, and rigorous data validation governance. Through label-guided automated difficulty-aware optimization, tow-stage training pipeline, and dynamic attribution systems, we achieve substantial improvements in training efficiency. Our models undergo comprehensive evaluation on mainstream financial benchmarks including Fineva, FinEval, and FinanceIQ, as well as general reasoning datasets such as MATH-500 and GPQA-diamond. To thoroughly assess real-world deployment capabilities, we innovatively propose the Finova evaluation benchmark, which focuses on agent-level financial reasoning and compliance verification. Experimental results demonstrate that Agentar-Fin-R1 not only achieves state-of-the-art performance on financial tasks but also exhibits exceptional general reasoning capabilities, validating its effectiveness as a trustworthy solution for high-stakes financial applications. The Finova bench is available at https://github.com/antgroup/Finova.
Transferable Parasitic Estimation via Graph Contrastive Learning and Label Rebalancing in AMS Circuits
Jul 09, 2025Graph representation learning on Analog-Mixed Signal (AMS) circuits is crucial for various downstream tasks, e.g., parasitic estimation. However, the scarcity of design data, the unbalanced distribution of labels, and the inherent diversity of circuit implementations pose significant challenges to learning robust and transferable circuit representations. To address these limitations, we propose CircuitGCL, a novel graph contrastive learning framework that integrates representation scattering and label rebalancing to enhance transferability across heterogeneous circuit graphs. CircuitGCL employs a self-supervised strategy to learn topology-invariant node embeddings through hyperspherical representation scattering, eliminating dependency on large-scale data. Simultaneously, balanced mean squared error (MSE) and softmax cross-entropy (bsmCE) losses are introduced to mitigate label distribution disparities between circuits, enabling robust and transferable parasitic estimation. Evaluated on parasitic capacitance estimation (edge-level task) and ground capacitance classification (node-level task) across TSMC 28nm AMS designs, CircuitGCL outperforms all state-of-the-art (SOTA) methods, with the $R^2$ improvement of $33.64\% \sim 44.20\%$ for edge regression and F1-score gain of $0.9\times \sim 2.1\times$ for node classification. Our code is available at \href{https://anonymous.4open.science/r/CircuitGCL-099B/README.md}{here}.