 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
GraphPrompter: Multi-stage Adaptive Prompt Optimization for Graph In-Context Learning
May 04, 2025Graph In-Context Learning, with the ability to adapt pre-trained graph models to novel and diverse downstream graphs without updating any parameters, has gained much attention in the community. The key to graph in-context learning is to perform downstream graphs conditioned on chosen prompt examples. Existing methods randomly select subgraphs or edges as prompts, leading to noisy graph prompts and inferior model performance. Additionally, due to the gap between pre-training and testing graphs, when the number of classes in the testing graphs is much greater than that in the training, the in-context learning ability will also significantly deteriorate. To tackle the aforementioned challenges, we develop a multi-stage adaptive prompt optimization method GraphPrompter, which optimizes the entire process of generating, selecting, and using graph prompts for better in-context learning capabilities. Firstly, Prompt Generator introduces a reconstruction layer to highlight the most informative edges and reduce irrelevant noise for graph prompt construction. Furthermore, in the selection stage, Prompt Selector employs the $k$-nearest neighbors algorithm and pre-trained selection layers to dynamically choose appropriate samples and minimize the influence of irrelevant prompts. Finally, we leverage a Prompt Augmenter with a cache replacement strategy to enhance the generalization capability of the pre-trained model on new datasets. Extensive experiments show that GraphPrompter effectively enhances the in-context learning ability of graph models. On average across all the settings, our approach surpasses the state-of-the-art baselines by over 8%. Our code is released at https://github.com/karin0018/GraphPrompter.
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Jan 17, 2025



Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners' practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.
Memory efficient location recommendation through proximity-aware representation
Oct 24, 2023



Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective
Jun 18, 2023



Large language models (LLMs), like ChatGPT, have shown some human-like cognitive abilities. For comparing these abilities of different models, several benchmarks (i.e. sets of standard test questions) from different fields (e.g., Literature, Biology and Psychology) are often adopted and the test results under traditional metrics such as accuracy, recall and F1, are reported. However, such way for evaluating LLMs can be inefficient and inaccurate from the cognitive science perspective. Inspired by Computerized Adaptive Testing (CAT) used in psychometrics, we propose an adaptive testing framework for LLM evaluation. Rather than using a standard test set and simply reporting accuracy, this approach dynamically adjusts the characteristics of the test questions, such as difficulty, based on the model's performance. This allows for a more accurate estimation of the model's abilities, using fewer questions. More importantly, it allows LLMs to be compared with humans easily, which is essential for NLP models that aim for human-level ability. Our diagnostic reports have found that ChatGPT often behaves like a ``careless student'', prone to slip and occasionally guessing the questions. We conduct a fine-grained diagnosis and rank the latest 6 instruction-tuned LLMs from three aspects of Subject Knowledge, Mathematical Reasoning, and Programming, where GPT4 can outperform other models significantly and reach the cognitive ability of middle-level students. Different tests for different models using efficient adaptive testing -- we believe this has the potential to become a new norm in evaluating large language models.
N-Gram Nearest Neighbor Machine Translation
Feb 07, 2023Nearest neighbor machine translation augments the Autoregressive Translation~(AT) with $k$-nearest-neighbor retrieval, by comparing the similarity between the token-level context representations of the target tokens in the query and the datastore. However, the token-level representation may introduce noise when translating ambiguous words, or fail to provide accurate retrieval results when the representation generated by the model contains indistinguishable context information, e.g., Non-Autoregressive Translation~(NAT) models. In this paper, we propose a novel $n$-gram nearest neighbor retrieval method that is model agnostic and applicable to both AT and NAT models. Specifically, we concatenate the adjacent $n$-gram hidden representations as the key, while the tuple of corresponding target tokens is the value. In inference, we propose tailored decoding algorithms for AT and NAT models respectively. We demonstrate that the proposed method consistently outperforms the token-level method on both AT and NAT models as well on general as on domain adaptation translation tasks. On domain adaptation, the proposed method brings $1.03$ and $2.76$ improvements regarding the average BLEU score on AT and NAT models respectively.
Discovering New Intents with Deep Aligned Clustering
Dec 22, 2020
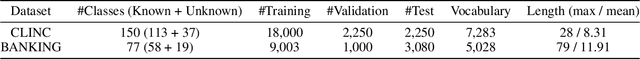

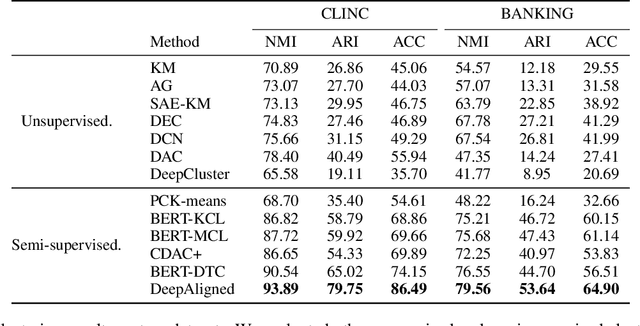
Discovering new intents is a crucial task in a dialogue system. Most existing methods are limited in transferring the prior knowledge from known intents to new intents. These methods also have difficulties in providing high-quality supervised signals to learn clustering-friendly features for grouping unlabeled intents. In this work, we propose an effective method (Deep Aligned Clustering) to discover new intents with the aid of limited known intent data. Firstly, we leverage a few labeled known intent samples as prior knowledge to pre-train the model. Then, we perform k-means to produce cluster assignments as pseudo-labels. Moreover, we propose an alignment strategy to tackle the label inconsistency during clustering assignments. Finally, we learn the intent representations under the supervision of the aligned pseudo-labels. With an unknown number of new intents, we predict the number of intent categories by eliminating low-confidence intent-wise clusters. Extensive experiments on two benchmark datasets show that our method is more robust and achieves substantial improvements over the state-of-the-art methods.(Code available at https://github.com/hanleizhang/DeepAligned-Clustering)