 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025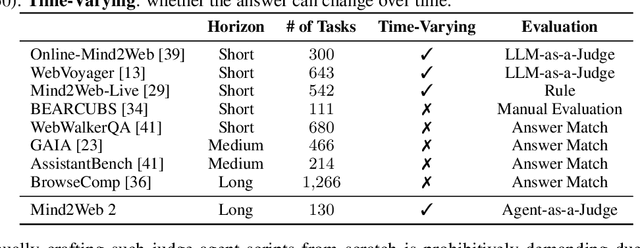
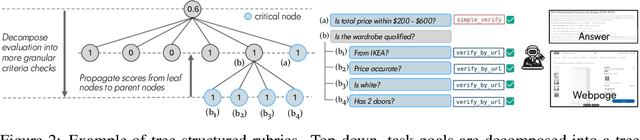

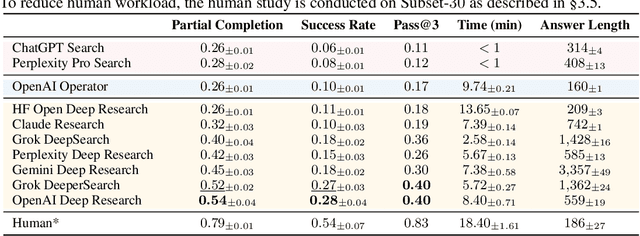
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
Pandora: Towards General World Model with Natural Language Actions and Video States
Jun 12, 2024



World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. Pandora achieves domain generality, video consistency, and controllability through large-scale pretraining and instruction tuning. Crucially, Pandora bypasses the cost of training-from-scratch by integrating a pretrained LLM (7B) and a pretrained video model, requiring only additional lightweight finetuning. We illustrate extensive outputs by Pandora across diverse domains (indoor/outdoor, natural/urban, human/robot, 2D/3D, etc.). The results indicate great potential of building stronger general world models with larger-scale training.
EduNLP: Towards a Unified and Modularized Library for Educational Resources
Jun 04, 2024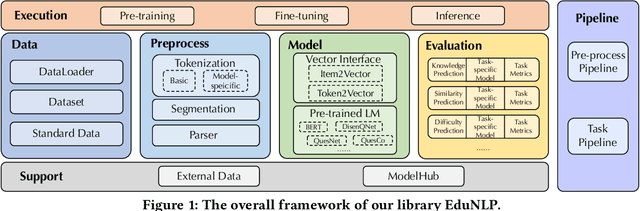
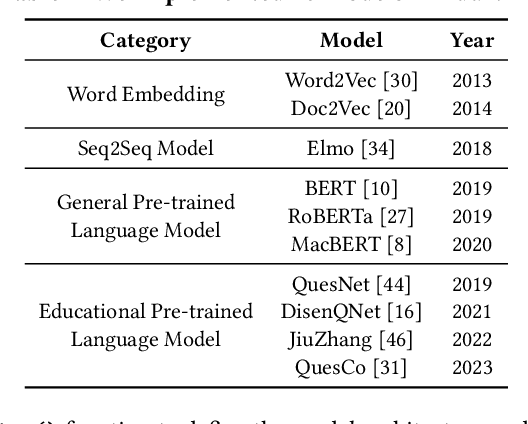
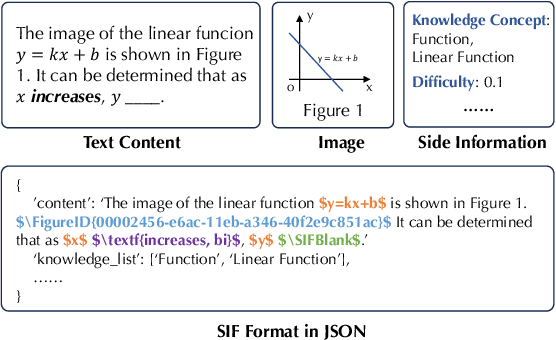
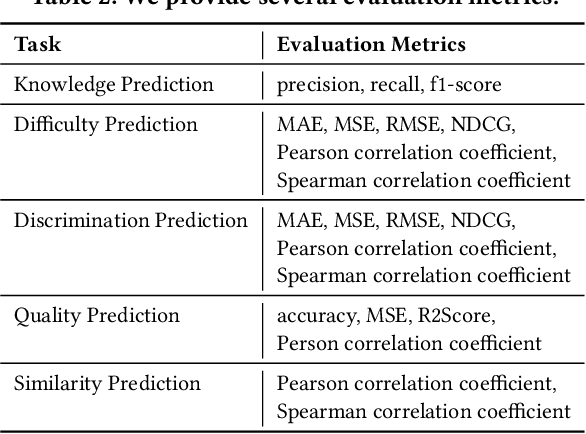
Educational resource understanding is vital to online learning platforms, which have demonstrated growing applications recently. However, researchers and developers always struggle with using existing general natural language toolkits or domain-specific models. The issue raises a need to develop an effective and easy-to-use one that benefits AI education-related research and applications. To bridge this gap, we present a unified, modularized, and extensive library, EduNLP, focusing on educational resource understanding. In the library, we decouple the whole workflow to four key modules with consistent interfaces including data configuration, processing, model implementation, and model evaluation. We also provide a configurable pipeline to unify the data usage and model usage in standard ways, where users can customize their own needs. For the current version, we primarily provide 10 typical models from four categories, and 5 common downstream-evaluation tasks in the education domain on 8 subjects for users' usage. The project is released at: https://github.com/bigdata-ustc/EduNLP.
In Search of the Long-Tail: Systematic Generation of Long-Tail Knowledge via Logical Rule Guided Search
Nov 13, 2023



Since large language models have approached human-level performance on many tasks, it has become increasingly harder for researchers to find tasks that are still challenging to the models. Failure cases usually come from the long-tail distribution - data that an oracle language model could assign a probability on the lower end of its distribution. Current methodology such as prompt engineering or crowdsourcing are insufficient for creating long-tail examples because humans are constrained by cognitive bias. We propose a Logic-Induced-Knowledge-Search (LINK) framework for systematically generating long-tail knowledge statements. Grounded by a symbolic rule, we search for long-tail values for each variable of the rule by first prompting a LLM, then verifying the correctness of the values with a critic, and lastly pushing for the long-tail distribution with a reranker. With this framework we construct a dataset, Logic-Induced-Long-Tail (LINT), consisting of 200 symbolic rules and 50K knowledge statements spanning across four domains. Human annotations find that 84% of the statements in LINT are factually correct. In contrast, ChatGPT and GPT4 struggle with directly generating long-tail statements under the guidance of logic rules, each only getting 56% and 78% of their statements correct. Moreover, their "long-tail" generations in fact fall into the higher likelihood range, and thus are not really long-tail. Our findings suggest that LINK is effective for generating data in the long-tail distribution while enforcing quality. LINT can be useful for systematically evaluating LLMs' capabilities in the long-tail distribution. We challenge the models with a simple entailment classification task using samples from LINT. We find that ChatGPT and GPT4's capability in identifying incorrect knowledge drop by ~3% in the long-tail distribution compared to head distribution.
Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective
Jun 18, 2023Large language models (LLMs), like ChatGPT, have shown some human-like cognitive abilities. For comparing these abilities of different models, several benchmarks (i.e. sets of standard test questions) from different fields (e.g., Literature, Biology and Psychology) are often adopted and the test results under traditional metrics such as accuracy, recall and F1, are reported. However, such way for evaluating LLMs can be inefficient and inaccurate from the cognitive science perspective. Inspired by Computerized Adaptive Testing (CAT) used in psychometrics, we propose an adaptive testing framework for LLM evaluation. Rather than using a standard test set and simply reporting accuracy, this approach dynamically adjusts the characteristics of the test questions, such as difficulty, based on the model's performance. This allows for a more accurate estimation of the model's abilities, using fewer questions. More importantly, it allows LLMs to be compared with humans easily, which is essential for NLP models that aim for human-level ability. Our diagnostic reports have found that ChatGPT often behaves like a ``careless student'', prone to slip and occasionally guessing the questions. We conduct a fine-grained diagnosis and rank the latest 6 instruction-tuned LLMs from three aspects of Subject Knowledge, Mathematical Reasoning, and Programming, where GPT4 can outperform other models significantly and reach the cognitive ability of middle-level students. Different tests for different models using efficient adaptive testing -- we believe this has the potential to become a new norm in evaluating large language models.
A Novel Approach for Auto-Formulation of Optimization Problems
Feb 09, 2023



In the Natural Language for Optimization (NL4Opt) NeurIPS 2022 competition, competitors focus on improving the accessibility and usability of optimization solvers, with the aim of subtask 1: recognizing the semantic entities that correspond to the components of the optimization problem; subtask 2: generating formulations for the optimization problem. In this paper, we present the solution of our team. First, we treat subtask 1 as a named entity recognition (NER) problem with the solution pipeline including pre-processing methods, adversarial training, post-processing methods and ensemble learning. Besides, we treat subtask 2 as a generation problem with the solution pipeline including specially designed prompts, adversarial training, post-processing methods and ensemble learning. Our proposed methods have achieved the F1-score of 0.931 in subtask 1 and the accuracy of 0.867 in subtask 2, which won the fourth and third places respectively in this competition. Our code is available at https://github.com/bigdata-ustc/nl4opt.
Towards a Holistic Understanding of Mathematical Questions with Contrastive Pre-training
Jan 18, 2023Understanding mathematical questions effectively is a crucial task, which can benefit many applications, such as difficulty estimation. Researchers have drawn much attention to designing pre-training models for question representations due to the scarcity of human annotations (e.g., labeling difficulty). However, unlike general free-format texts (e.g., user comments), mathematical questions are generally designed with explicit purposes and mathematical logic, and usually consist of more complex content, such as formulas, and related mathematical knowledge (e.g., Function). Therefore, the problem of holistically representing mathematical questions remains underexplored. To this end, in this paper, we propose a novel contrastive pre-training approach for mathematical question representations, namely QuesCo, which attempts to bring questions with more similar purposes closer. Specifically, we first design two-level question augmentations, including content-level and structure-level, which generate literally diverse question pairs with similar purposes. Then, to fully exploit hierarchical information of knowledge concepts, we propose a knowledge hierarchy-aware rank strategy (KHAR), which ranks the similarities between questions in a fine-grained manner. Next, we adopt a ranking contrastive learning task to optimize our model based on the augmented and ranked questions. We conduct extensive experiments on two real-world mathematical datasets. The experimental results demonstrate the effectiveness of our model.