 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Online and Offline RL: Contextual Bandit Learning for Multi-Turn Code Generation
Feb 03, 2026Recently, there have been significant research interests in training large language models (LLMs) with reinforcement learning (RL) on real-world tasks, such as multi-turn code generation. While online RL tends to perform better than offline RL, its higher training cost and instability hinders wide adoption. In this paper, we build on the observation that multi-turn code generation can be formulated as a one-step recoverable Markov decision process and propose contextual bandit learning with offline trajectories (Cobalt), a new method that combines the benefits of online and offline RL. Cobalt first collects code generation trajectories using a reference LLM and divides them into partial trajectories as contextual prompts. Then, during online bandit learning, the LLM is trained to complete each partial trajectory prompt through single-step code generation. Cobalt outperforms two multi-turn online RL baselines based on GRPO and VeRPO, and substantially improves R1-Distill 8B and Qwen3 8B by up to 9.0 and 6.2 absolute Pass@1 scores on LiveCodeBench. Also, we analyze LLMs' in-context reward hacking behaviors and augment Cobalt training with perturbed trajectories to mitigate this issue. Overall, our results demonstrate Cobalt as a promising solution for iterative decision-making tasks like multi-turn code generation. Our code and data are available at https://github.com/OSU-NLP-Group/cobalt.
Large Language Models Achieve Gold Medal Performance at International Astronomy & Astrophysics Olympiad
Oct 06, 2025While task-specific demonstrations show early success in applying large language models (LLMs) to automate some astronomical research tasks, they only provide incomplete views of all necessary capabilities in solving astronomy problems, calling for more thorough understanding of LLMs' strengths and limitations. So far, existing benchmarks and evaluations focus on simple question-answering that primarily tests astronomical knowledge and fails to evaluate the complex reasoning required for real-world research in the discipline. Here, we address this gap by systematically benchmarking five state-of-the-art LLMs on the International Olympiad on Astronomy and Astrophysics (IOAA) exams, which are designed to examine deep conceptual understanding, multi-step derivations, and multimodal analysis. With average scores of 85.6% and 84.2%, Gemini 2.5 Pro and GPT-5 (the two top-performing models) not only achieve gold medal level performance but also rank in the top two among ~200-300 participants in all four IOAA theory exams evaluated (2022-2025). In comparison, results on the data analysis exams show more divergence. GPT-5 still excels in the exams with an 88.5% average score, ranking top 10 among the participants in the four most recent IOAAs, while other models' performances drop to 48-76%. Furthermore, our in-depth error analysis underscores conceptual reasoning, geometric reasoning, and spatial visualization (52-79% accuracy) as consistent weaknesses among all LLMs. Hence, although LLMs approach peak human performance in theory exams, critical gaps must be addressed before they can serve as autonomous research agents in astronomy.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024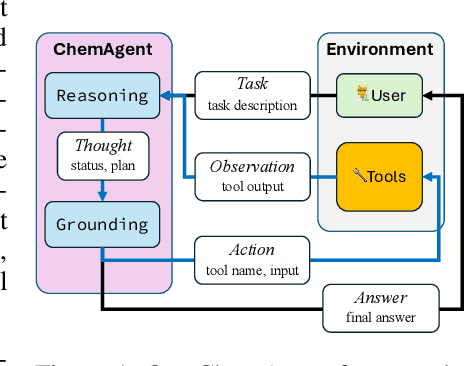
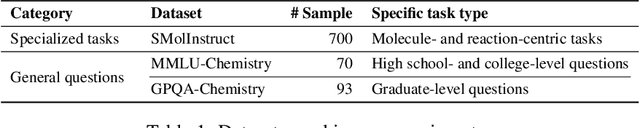

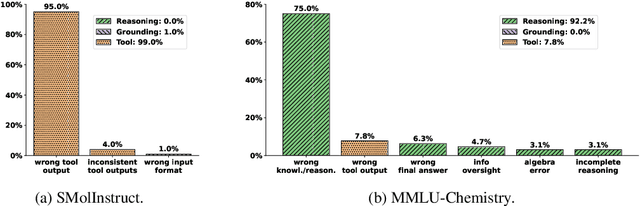
To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
Optimizing NOMA Transmissions to Advance Federated Learning in Vehicular Networks
Aug 06, 2024
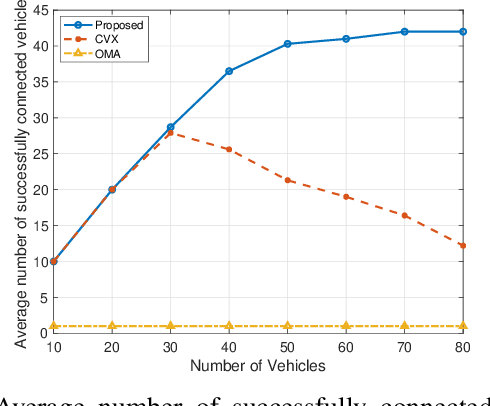
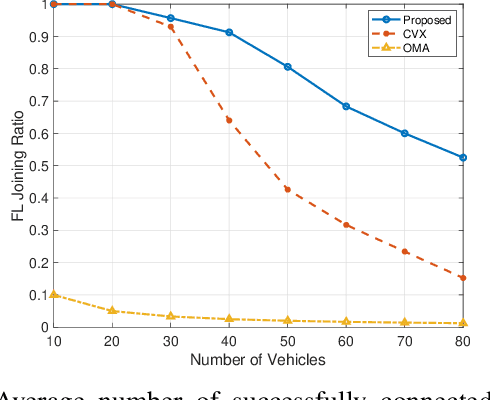
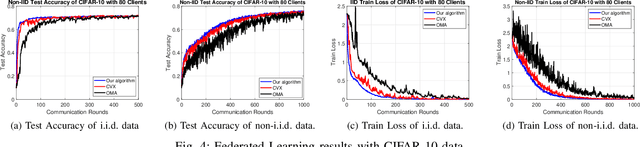
Diverse critical data, such as location information and driving patterns, can be collected by IoT devices in vehicular networks to improve driving experiences and road safety. However, drivers are often reluctant to share their data due to privacy concerns. The Federated Vehicular Network (FVN) is a promising technology that tackles these concerns by transmitting model parameters instead of raw data, thereby protecting the privacy of drivers. Nevertheless, the performance of Federated Learning (FL) in a vehicular network depends on the joining ratio, which is restricted by the limited available wireless resources. To address these challenges, this paper proposes to apply Non-Orthogonal Multiple Access (NOMA) to improve the joining ratio in a FVN. Specifically, a vehicle selection and transmission power control algorithm is developed to exploit the power domain differences in the received signal to ensure the maximum number of vehicles capable of joining the FVN. Our simulation results demonstrate that the proposed NOMA-based strategy increases the joining ratio and significantly enhances the performance of the FVN.
When is Tree Search Useful for LLM Planning? It Depends on the Discriminator
Feb 16, 2024



In this paper, we examine how large language models (LLMs) solve multi-step problems under a language agent framework with three components: a generator, a discriminator, and a planning method. We investigate the practical utility of two advanced planning methods, iterative correction and tree search. We present a comprehensive analysis of how discrimination accuracy affects the overall performance of agents when using these two methods or a simpler method, re-ranking. Experiments on two tasks, text-to-SQL parsing and mathematical reasoning, show that: (1) advanced planning methods demand discriminators with at least 90% accuracy to achieve significant improvements over re-ranking; (2) current LLMs' discrimination abilities have not met the needs of advanced planning methods to achieve such improvements; (3) with LLM-based discriminators, advanced planning methods may not adequately balance accuracy and efficiency. For example, compared to the other two methods, tree search is at least 10--20 times slower but leads to negligible performance gains, which hinders its real-world applications. Code and data will be released at https://github.com/OSU-NLP-Group/llm-planning-eval.
eCeLLM: Generalizing Large Language Models for E-commerce from Large-scale, High-quality Instruction Data
Feb 13, 2024
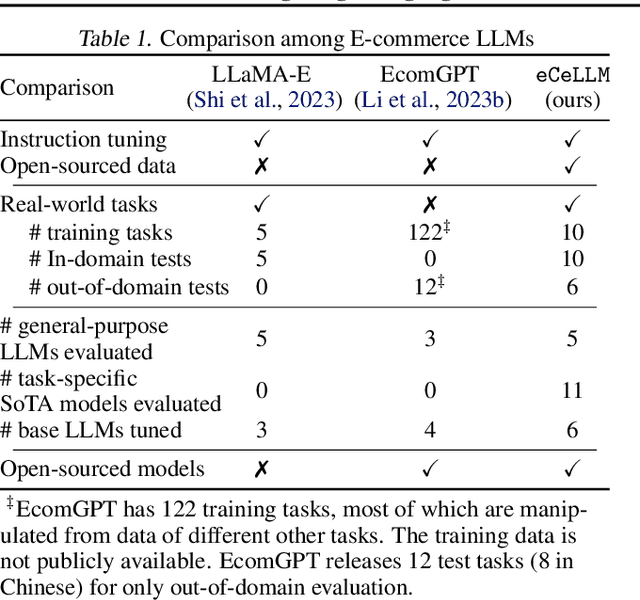
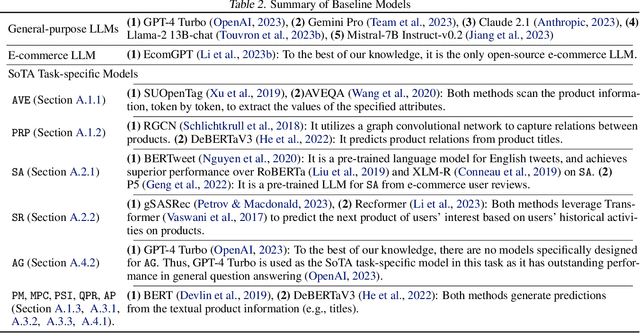
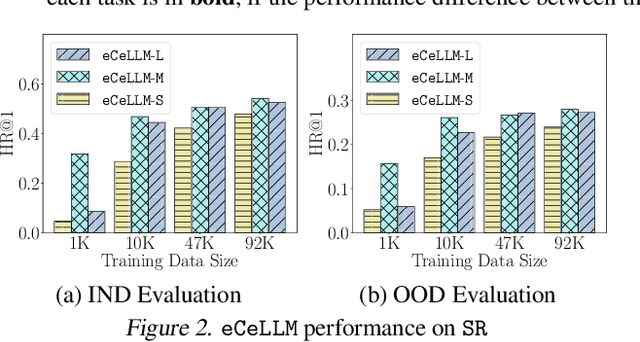
With tremendous efforts on developing effective e-commerce models, conventional e-commerce models show limited success in generalist e-commerce modeling, and suffer from unsatisfactory performance on new users and new products - a typical out-of-domain generalization challenge. Meanwhile, large language models (LLMs) demonstrate outstanding performance in generalist modeling and out-of-domain generalizability in many fields. Toward fully unleashing their power for e-commerce, in this paper, we construct ECInstruct, the first open-sourced, large-scale, and high-quality benchmark instruction dataset for e-commerce. Leveraging ECInstruct, we develop eCeLLM, a series of e-commerce LLMs, by instruction-tuning general-purpose LLMs. Our comprehensive experiments and evaluation demonstrate that eCeLLM models substantially outperform baseline models, including the most advanced GPT-4, and the state-of-the-art task-specific models in in-domain evaluation. Moreover, eCeLLM exhibits excellent generalizability to out-of-domain settings, including unseen products and unseen instructions, highlighting its superiority as a generalist e-commerce model. Both the ECInstruct dataset and the eCeLLM models show great potential in empowering versatile and effective LLMs for e-commerce. ECInstruct and eCeLLM models are publicly accessible through https://ninglab.github.io/eCeLLM.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
Jul 29, 2023

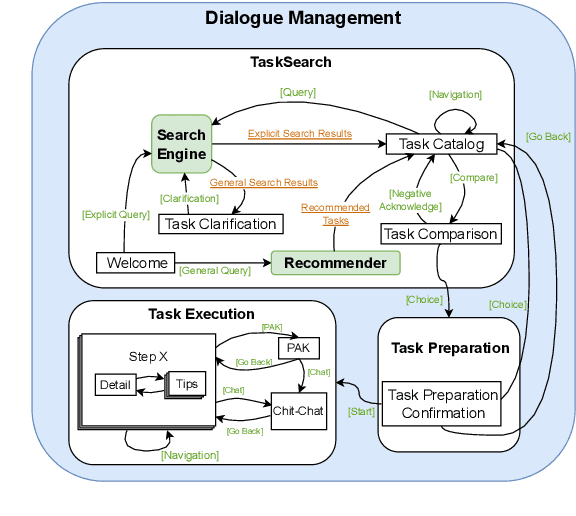
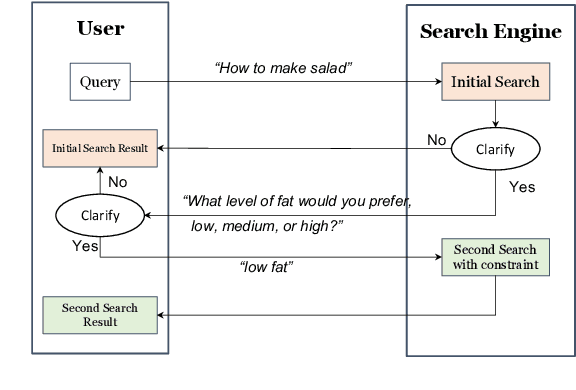
We introduce TacoBot, a user-centered task-oriented digital assistant designed to guide users through complex real-world tasks with multiple steps. Covering a wide range of cooking and how-to tasks, we aim to deliver a collaborative and engaging dialogue experience. Equipped with language understanding, dialogue management, and response generation components supported by a robust search engine, TacoBot ensures efficient task assistance. To enhance the dialogue experience, we explore a series of data augmentation strategies using LLMs to train advanced neural models continuously. TacoBot builds upon our successful participation in the inaugural Alexa Prize TaskBot Challenge, where our team secured third place among ten competing teams. We offer TacoBot as an open-source framework that serves as a practical example for deploying task-oriented dialogue systems.
Exploring Chain-of-Thought Style Prompting for Text-to-SQL
May 23, 2023Conventional supervised approaches for text-to-SQL parsing often require large amounts of annotated data, which is costly to obtain in practice. Recently, in-context learning with large language models (LLMs) has caught increasing attention due to its superior few-shot performance in a wide range of tasks. However, most attempts to use in-context learning for text-to-SQL parsing still lag behind supervised methods. We hypothesize that the under-performance is because text-to-SQL parsing requires complex, multi-step reasoning. In this paper, we systematically study how to enhance the reasoning ability of LLMs for text-to-SQL parsing through chain-of-thought (CoT) style promptings including CoT prompting and Least-to-Most prompting. Our experiments demonstrate that iterative prompting as in Least-to-Most prompting may be unnecessary for text-to-SQL parsing and directly applying existing CoT style prompting methods leads to error propagation issues. By improving multi-step reasoning while avoiding much detailed information in the reasoning steps which may lead to error propagation, our new method outperforms existing ones by 2.4 point absolute gains on the Spider development set.