 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025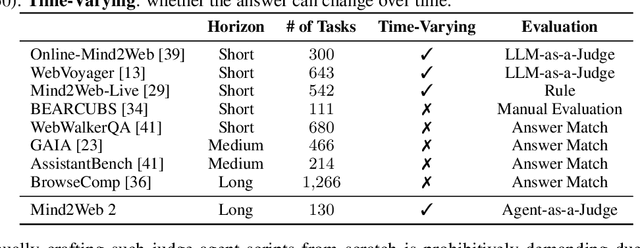
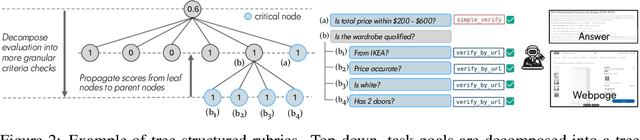

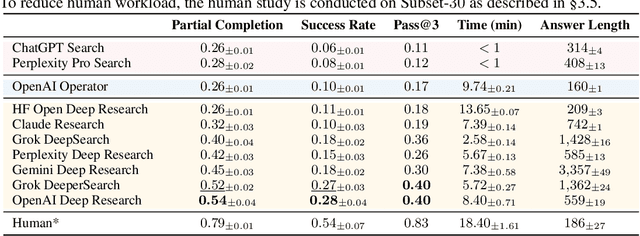
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
Ambient Backscatter Communication in LTE Uplink Sounding Reference Signal
Jan 19, 2025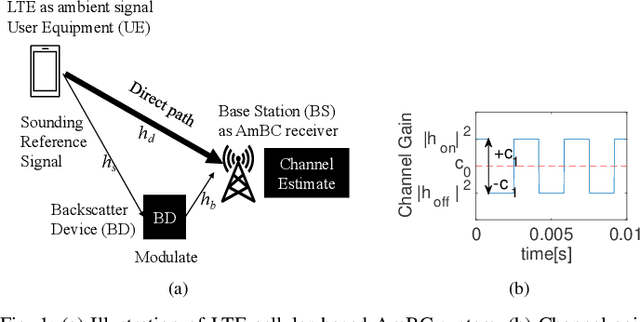
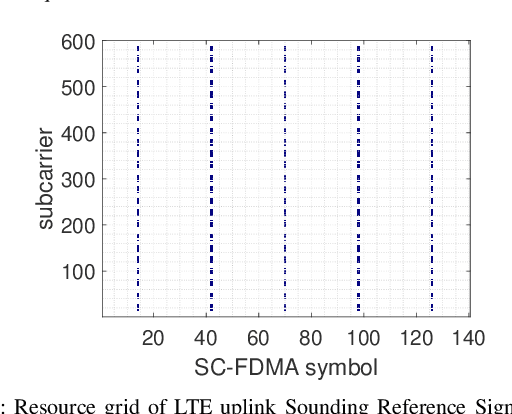
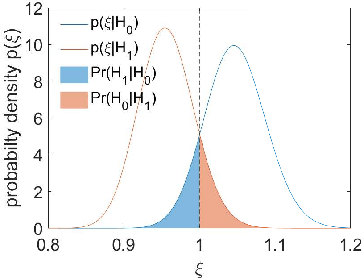
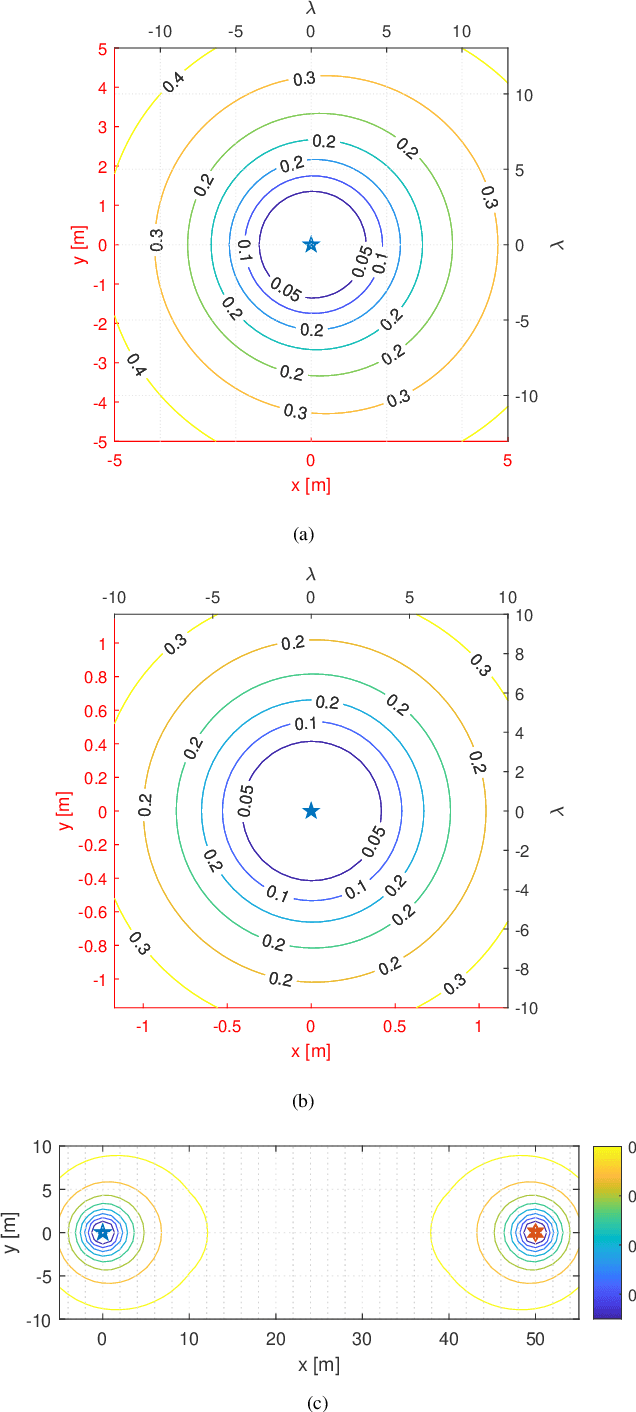
Ambient Internet of Things (AIoT), recently standardized by the 3rd Generation Partnership Project (3GPP), demands a low-power wide-area communication solution that operates several orders of magnitude below the power requirements of existing 3GPP specifications. Ambient backscatter communication (AmBC) is considered as a competitive potential technique by harvesting energy from the ambient RF signal. This paper considers a symbiotic AmBC into Long Term Evolution (LTE) cellular system uplink. Leveraging by LTE uplink channel estimation ability, AIoT conveys its own message to Base Station (BS) by modulating backscatter path. We explore the detector design, analyze the error performance of the proposed scheme, provide exact expression and its Guassian approximation for the error probability. We corroborate the receiver error performance by Monte Carlo simulation. Analysis of communication range reveals AmBC achieves a reasonable BER of order of magnitude $10^{-2}$ within four times wavelength reading distance. In addition, a AmBC prototype in LTE uplink confirms the its feasibility. The over-the-air experiment results validate theoretical analysis. Hence, the proposed AmBC approach enables AIoT deployment with minimal changes to the LTE system.
ICT: Image-Object Cross-Level Trusted Intervention for Mitigating Object Hallucination in Large Vision-Language Models
Nov 22, 2024Despite the recent breakthroughs achieved by Large Vision Language Models (LVLMs) in understanding and responding to complex visual-textual contexts, their inherent hallucination tendencies limit their practical application in real-world scenarios that demand high levels of precision. Existing methods typically either fine-tune the LVLMs using additional data, which incurs extra costs in manual annotation and computational resources or perform comparisons at the decoding stage, which may eliminate useful language priors for reasoning while introducing inference time overhead. Therefore, we propose ICT, a lightweight, training-free method that calculates an intervention direction to shift the model's focus towards different levels of visual information, enhancing its attention to high-level and fine-grained visual details. During the forward pass stage, the intervention is applied to the attention heads that encode the overall image information and the fine-grained object details, effectively mitigating the phenomenon of overly language priors, and thereby alleviating hallucinations. Extensive experiments demonstrate that ICT achieves strong performance with a small amount of data and generalizes well across different datasets and models. Our code will be public.
Few-shot Adaptation of Multi-modal Foundation Models: A Survey
Jan 04, 2024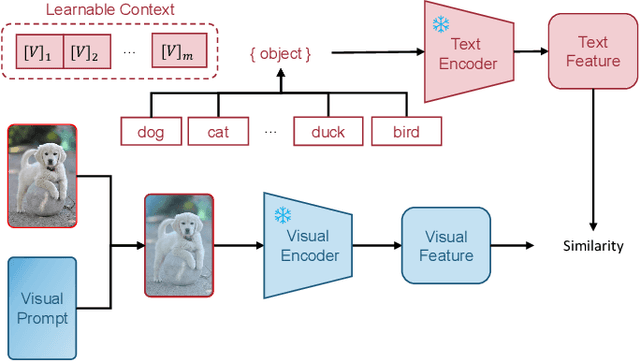
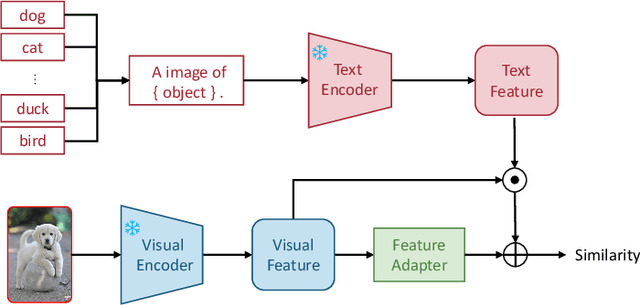
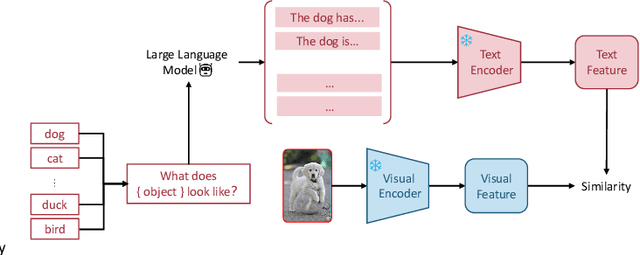
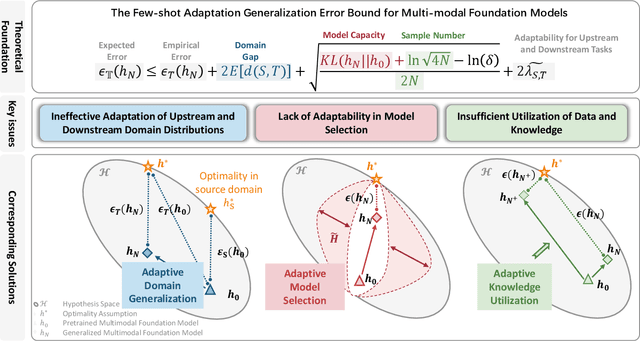
Multi-modal (vision-language) models, such as CLIP, are replacing traditional supervised pre-training models (e.g., ImageNet-based pre-training) as the new generation of visual foundation models. These models with robust and aligned semantic representations learned from billions of internet image-text pairs and can be applied to various downstream tasks in a zero-shot manner. However, in some fine-grained domains like medical imaging and remote sensing, the performance of multi-modal foundation models often leaves much to be desired. Consequently, many researchers have begun to explore few-shot adaptation methods for these models, gradually deriving three main technical approaches: 1) prompt-based methods, 2) adapter-based methods, and 3) external knowledge-based methods. Nevertheless, this rapidly developing field has produced numerous results without a comprehensive survey to systematically organize the research progress. Therefore, in this survey, we introduce and analyze the research advancements in few-shot adaptation methods for multi-modal models, summarizing commonly used datasets and experimental setups, and comparing the results of different methods. In addition, due to the lack of reliable theoretical support for existing methods, we derive the few-shot adaptation generalization error bound for multi-modal models. The theorem reveals that the generalization error of multi-modal foundation models is constrained by three factors: domain gap, model capacity, and sample size. Based on this, we propose three possible solutions from the following aspects: 1) adaptive domain generalization, 2) adaptive model selection, and 3) adaptive knowledge utilization.
TableLlama: Towards Open Large Generalist Models for Tables
Nov 15, 2023Semi-structured tables are ubiquitous. There has been a variety of tasks that aim to automatically interpret, augment, and query tables. Current methods often require pretraining on tables or special model architecture design, are restricted to specific table types, or have simplifying assumptions about tables and tasks. This paper makes the first step towards developing open-source large language models (LLMs) as generalists for a diversity of table-based tasks. Towards that end, we construct TableInstruct, a new dataset with a variety of realistic tables and tasks, for instruction tuning and evaluating LLMs. We further develop the first open-source generalist model for tables, TableLlama, by fine-tuning Llama 2 (7B) with LongLoRA to address the long context challenge. We experiment under both in-domain setting and out-of-domain setting. On 7 out of 8 in-domain tasks, TableLlama achieves comparable or better performance than the SOTA for each task, despite the latter often has task-specific design. On 6 out-of-domain datasets, it achieves 6-48 absolute point gains compared with the base model, showing that training on TableInstruct enhances the model's generalizability. We will open-source our dataset and trained model to boost future work on developing open generalist models for tables.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
Jul 29, 2023We introduce TacoBot, a user-centered task-oriented digital assistant designed to guide users through complex real-world tasks with multiple steps. Covering a wide range of cooking and how-to tasks, we aim to deliver a collaborative and engaging dialogue experience. Equipped with language understanding, dialogue management, and response generation components supported by a robust search engine, TacoBot ensures efficient task assistance. To enhance the dialogue experience, we explore a series of data augmentation strategies using LLMs to train advanced neural models continuously. TacoBot builds upon our successful participation in the inaugural Alexa Prize TaskBot Challenge, where our team secured third place among ten competing teams. We offer TacoBot as an open-source framework that serves as a practical example for deploying task-oriented dialogue systems.
Federated Learning for Semantic Parsing: Task Formulation, Evaluation Setup, New Algorithms
May 26, 2023This paper studies a new task of federated learning (FL) for semantic parsing, where multiple clients collaboratively train one global model without sharing their semantic parsing data. By leveraging data from multiple clients, the FL paradigm can be especially beneficial for clients that have little training data to develop a data-hungry neural semantic parser on their own. We propose an evaluation setup to study this task, where we re-purpose widely-used single-domain text-to-SQL datasets as clients to form a realistic heterogeneous FL setting and collaboratively train a global model. As standard FL algorithms suffer from the high client heterogeneity in our realistic setup, we further propose a novel LOss Reduction Adjusted Re-weighting (Lorar) mechanism to mitigate the performance degradation, which adjusts each client's contribution to the global model update based on its training loss reduction during each round. Our intuition is that the larger the loss reduction, the further away the current global model is from the client's local optimum, and the larger weight the client should get. By applying Lorar to three widely adopted FL algorithms (FedAvg, FedOPT and FedProx), we observe that their performance can be improved substantially on average (4%-20% absolute gain under MacroAvg) and that clients with smaller datasets enjoy larger performance gains. In addition, the global model converges faster for almost all the clients.
Exploring Chain-of-Thought Style Prompting for Text-to-SQL
May 23, 2023Conventional supervised approaches for text-to-SQL parsing often require large amounts of annotated data, which is costly to obtain in practice. Recently, in-context learning with large language models (LLMs) has caught increasing attention due to its superior few-shot performance in a wide range of tasks. However, most attempts to use in-context learning for text-to-SQL parsing still lag behind supervised methods. We hypothesize that the under-performance is because text-to-SQL parsing requires complex, multi-step reasoning. In this paper, we systematically study how to enhance the reasoning ability of LLMs for text-to-SQL parsing through chain-of-thought (CoT) style promptings including CoT prompting and Least-to-Most prompting. Our experiments demonstrate that iterative prompting as in Least-to-Most prompting may be unnecessary for text-to-SQL parsing and directly applying existing CoT style prompting methods leads to error propagation issues. By improving multi-step reasoning while avoiding much detailed information in the reasoning steps which may lead to error propagation, our new method outperforms existing ones by 2.4 point absolute gains on the Spider development set.
Bootstrapping a User-Centered Task-Oriented Dialogue System
Jul 11, 2022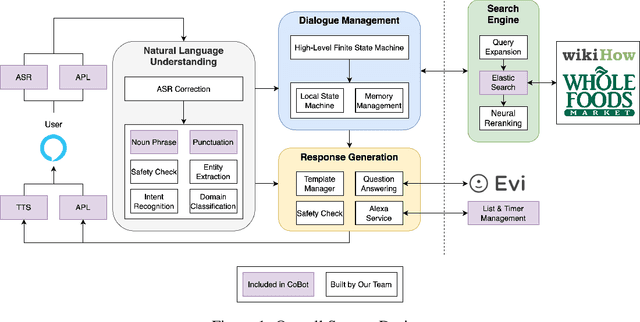



We present TacoBot, a task-oriented dialogue system built for the inaugural Alexa Prize TaskBot Challenge, which assists users in completing multi-step cooking and home improvement tasks. TacoBot is designed with a user-centered principle and aspires to deliver a collaborative and accessible dialogue experience. Towards that end, it is equipped with accurate language understanding, flexible dialogue management, and engaging response generation. Furthermore, TacoBot is backed by a strong search engine and an automated end-to-end test suite. In bootstrapping the development of TacoBot, we explore a series of data augmentation strategies to train advanced neural language processing models and continuously improve the dialogue experience with collected real conversations. At the end of the semifinals, TacoBot achieved an average rating of 3.55/5.0.