 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Transmit Waveform and Receive Filter Design for ISAC System with Jamming
Apr 11, 2025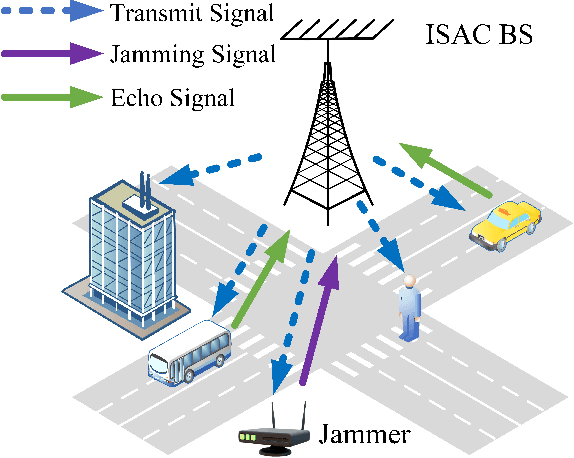
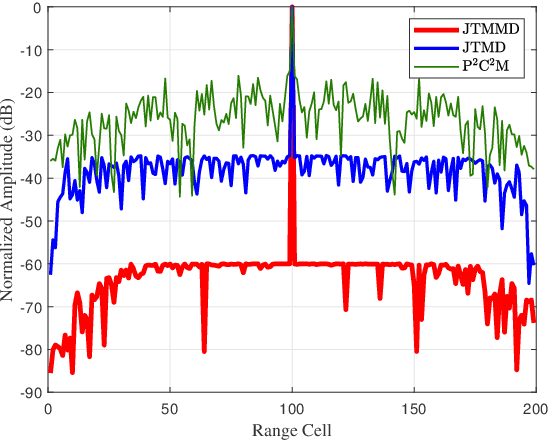
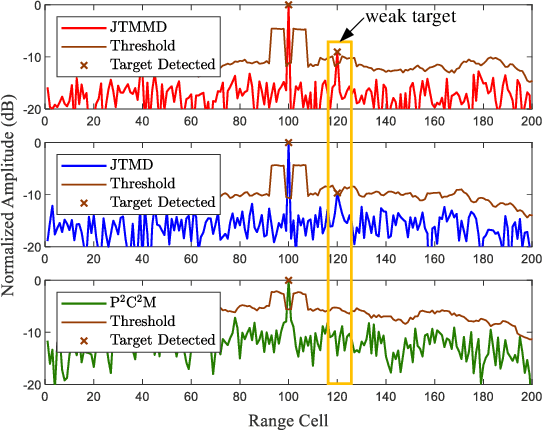
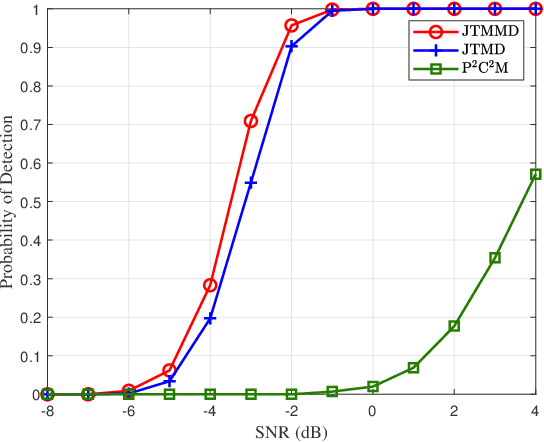
In this paper, to suppress jamming in the complex electromagnetic environment, we propose a joint transmit waveform and receive filter design framework for integrated sensing and communications (ISAC). By jointly optimizing the transmit waveform and receive filters, we aim at minimizing the multiuser interference (MUI), subject to the constraints of the target mainlobe, jamming mainlobe and peak sidelobe level of the receive filter output as well as the transmit power of the ISAC base station. We propose two schemes to solve the problem, including joint transmit waveform and matched filter design (JTMD) and joint transmit waveform and mismatched filter design (JTMMD) schemes. For both schemes, we adopt the alternating direction method of multipliers to iteratively optimize the transmit waveform and receive filters, where the number of targets as well as the range and angles of each target can also be estimated. Simulation results show that both the JTMD and JTMMD schemes achieve superior performance in terms of communication MUI and radar detection performance.
Simultaneously Recovering Multi-Person Meshes and Multi-View Cameras with Human Semantics
Dec 25, 2024Dynamic multi-person mesh recovery has broad applications in sports broadcasting, virtual reality, and video games. However, current multi-view frameworks rely on a time-consuming camera calibration procedure. In this work, we focus on multi-person motion capture with uncalibrated cameras, which mainly faces two challenges: one is that inter-person interactions and occlusions introduce inherent ambiguities for both camera calibration and motion capture; the other is that a lack of dense correspondences can be used to constrain sparse camera geometries in a dynamic multi-person scene. Our key idea is to incorporate motion prior knowledge to simultaneously estimate camera parameters and human meshes from noisy human semantics. We first utilize human information from 2D images to initialize intrinsic and extrinsic parameters. Thus, the approach does not rely on any other calibration tools or background features. Then, a pose-geometry consistency is introduced to associate the detected humans from different views. Finally, a latent motion prior is proposed to refine the camera parameters and human motions. Experimental results show that accurate camera parameters and human motions can be obtained through a one-step reconstruction. The code are publicly available at~\url{https://github.com/boycehbz/DMMR}.
Occluded Human Body Capture with Self-Supervised Spatial-Temporal Motion Prior
Jul 12, 2022

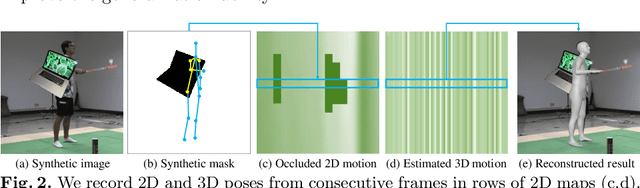
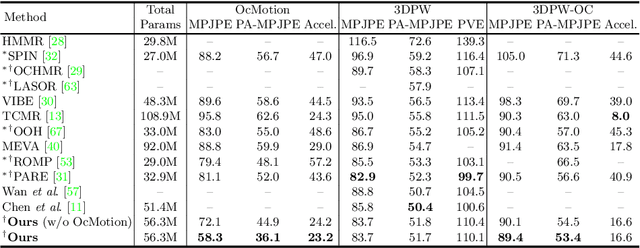
Although significant progress has been achieved on monocular maker-less human motion capture in recent years, it is still hard for state-of-the-art methods to obtain satisfactory results in occlusion scenarios. There are two main reasons: the one is that the occluded motion capture is inherently ambiguous as various 3D poses can map to the same 2D observations, which always results in an unreliable estimation. The other is that no sufficient occluded human data can be used for training a robust model. To address the obstacles, our key-idea is to employ non-occluded human data to learn a joint-level spatial-temporal motion prior for occluded human with a self-supervised strategy. To further reduce the gap between synthetic and real occlusion data, we build the first 3D occluded motion dataset~(OcMotion), which can be used for both training and testing. We encode the motions in 2D maps and synthesize occlusions on non-occluded data for the self-supervised training. A spatial-temporal layer is then designed to learn joint-level correlations. The learned prior reduces the ambiguities of occlusions and is robust to diverse occlusion types, which is then adopted to assist the occluded human motion capture. Experimental results show that our method can generate accurate and coherent human motions from occluded videos with good generalization ability and runtime efficiency. The dataset and code are publicly available at \url{https://github.com/boycehbz/CHOMP}.
Dynamic Multi-Person Mesh Recovery From Uncalibrated Multi-View Cameras
Oct 20, 2021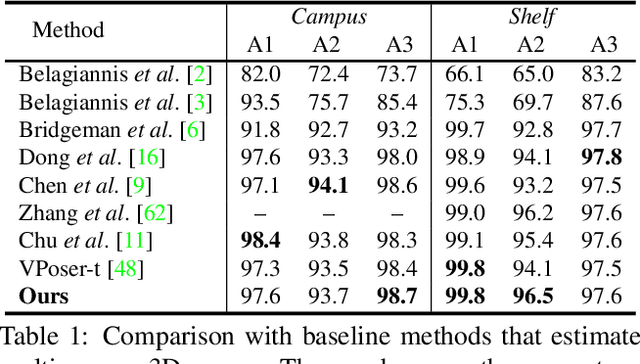
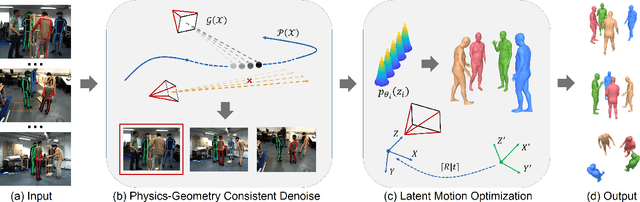
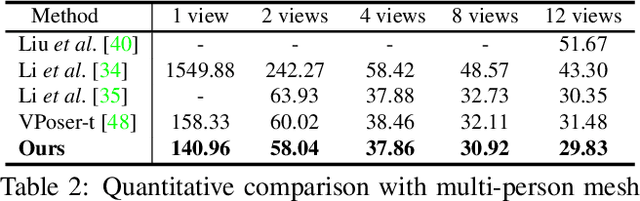
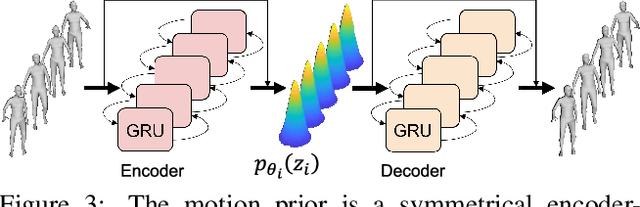
Dynamic multi-person mesh recovery has been a hot topic in 3D vision recently. However, few works focus on the multi-person motion capture from uncalibrated cameras, which mainly faces two challenges: the one is that inter-person interactions and occlusions introduce inherent ambiguities for both camera calibration and motion capture; The other is that a lack of dense correspondences can be used to constrain sparse camera geometries in a dynamic multi-person scene. Our key idea is incorporating motion prior knowledge into simultaneous optimization of extrinsic camera parameters and human meshes from noisy human semantics. First, we introduce a physics-geometry consistency to reduce the low and high frequency noises of the detected human semantics. Then a novel latent motion prior is proposed to simultaneously optimize extrinsic camera parameters and coherent human motions from slightly noisy inputs. Experimental results show that accurate camera parameters and human motions can be obtained through one-stage optimization. The codes will be publicly available at~\url{https://www.yangangwang.com}.