 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Recovering Multi-Person Meshes and Multi-View Cameras with Human Semantics
Dec 25, 2024Dynamic multi-person mesh recovery has broad applications in sports broadcasting, virtual reality, and video games. However, current multi-view frameworks rely on a time-consuming camera calibration procedure. In this work, we focus on multi-person motion capture with uncalibrated cameras, which mainly faces two challenges: one is that inter-person interactions and occlusions introduce inherent ambiguities for both camera calibration and motion capture; the other is that a lack of dense correspondences can be used to constrain sparse camera geometries in a dynamic multi-person scene. Our key idea is to incorporate motion prior knowledge to simultaneously estimate camera parameters and human meshes from noisy human semantics. We first utilize human information from 2D images to initialize intrinsic and extrinsic parameters. Thus, the approach does not rely on any other calibration tools or background features. Then, a pose-geometry consistency is introduced to associate the detected humans from different views. Finally, a latent motion prior is proposed to refine the camera parameters and human motions. Experimental results show that accurate camera parameters and human motions can be obtained through a one-step reconstruction. The code are publicly available at~\url{https://github.com/boycehbz/DMMR}.
CrowdRec: 3D Crowd Reconstruction from Single Color Images
Oct 10, 2023This is a technical report for the GigaCrowd challenge. Reconstructing 3D crowds from monocular images is a challenging problem due to mutual occlusions, server depth ambiguity, and complex spatial distribution. Since no large-scale 3D crowd dataset can be used to train a robust model, the current multi-person mesh recovery methods can hardly achieve satisfactory performance in crowded scenes. In this paper, we exploit the crowd features and propose a crowd-constrained optimization to improve the common single-person method on crowd images. To avoid scale variations, we first detect human bounding-boxes and 2D poses from the original images with off-the-shelf detectors. Then, we train a single-person mesh recovery network using existing in-the-wild image datasets. To promote a more reasonable spatial distribution, we further propose a crowd constraint to refine the single-person network parameters. With the optimization, we can obtain accurate body poses and shapes with reasonable absolute positions from a large-scale crowd image using a single-person backbone. The code will be publicly available at~\url{https://github.com/boycehbz/CrowdRec}.
Reconstructing Groups of People with Hypergraph Relational Reasoning
Aug 30, 2023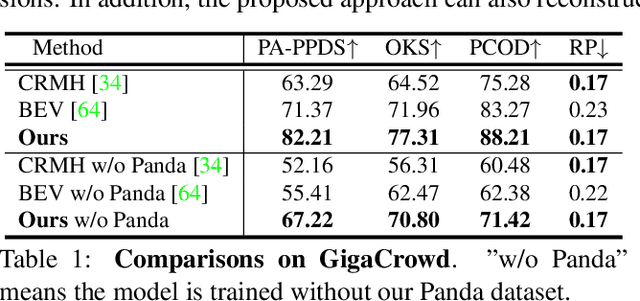

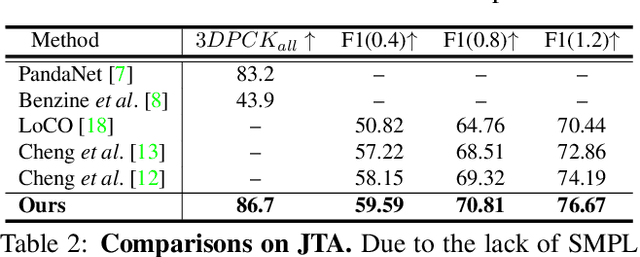
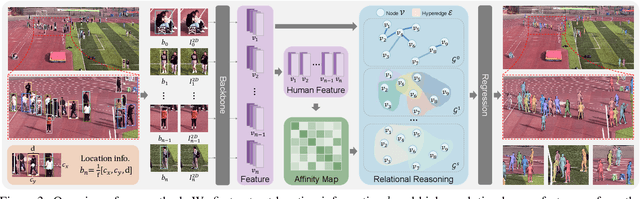
Due to the mutual occlusion, severe scale variation, and complex spatial distribution, the current multi-person mesh recovery methods cannot produce accurate absolute body poses and shapes in large-scale crowded scenes. To address the obstacles, we fully exploit crowd features for reconstructing groups of people from a monocular image. A novel hypergraph relational reasoning network is proposed to formulate the complex and high-order relation correlations among individuals and groups in the crowd. We first extract compact human features and location information from the original high-resolution image. By conducting the relational reasoning on the extracted individual features, the underlying crowd collectiveness and interaction relationship can provide additional group information for the reconstruction. Finally, the updated individual features and the localization information are used to regress human meshes in camera coordinates. To facilitate the network training, we further build pseudo ground-truth on two crowd datasets, which may also promote future research on pose estimation and human behavior understanding in crowded scenes. The experimental results show that our approach outperforms other baseline methods both in crowded and common scenarios. The code and datasets are publicly available at https://github.com/boycehbz/GroupRec.
Physics-Guided Human Motion Capture with Pose Probability Modeling
Aug 19, 2023Incorporating physics in human motion capture to avoid artifacts like floating, foot sliding, and ground penetration is a promising direction. Existing solutions always adopt kinematic results as reference motions, and the physics is treated as a post-processing module. However, due to the depth ambiguity, monocular motion capture inevitably suffers from noises, and the noisy reference often leads to failure for physics-based tracking. To address the obstacles, our key-idea is to employ physics as denoising guidance in the reverse diffusion process to reconstruct physically plausible human motion from a modeled pose probability distribution. Specifically, we first train a latent gaussian model that encodes the uncertainty of 2D-to-3D lifting to facilitate reverse diffusion. Then, a physics module is constructed to track the motion sampled from the distribution. The discrepancies between the tracked motion and image observation are used to provide explicit guidance for the reverse diffusion model to refine the motion. With several iterations, the physics-based tracking and kinematic denoising promote each other to generate a physically plausible human motion. Experimental results show that our method outperforms previous physics-based methods in both joint accuracy and success rate. More information can be found at \url{https://github.com/Me-Ditto/Physics-Guided-Mocap}.
Occluded Human Body Capture with Self-Supervised Spatial-Temporal Motion Prior
Jul 12, 2022

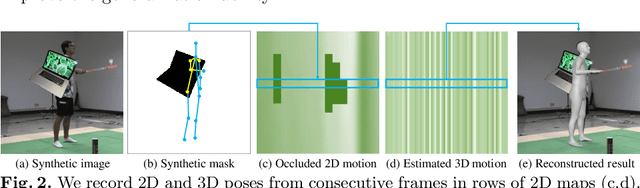
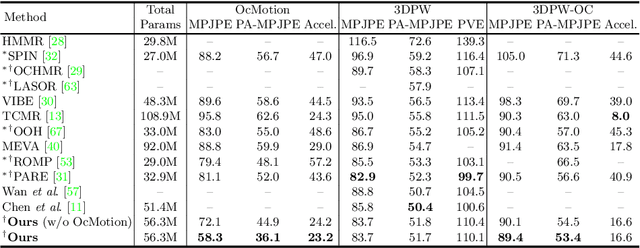
Although significant progress has been achieved on monocular maker-less human motion capture in recent years, it is still hard for state-of-the-art methods to obtain satisfactory results in occlusion scenarios. There are two main reasons: the one is that the occluded motion capture is inherently ambiguous as various 3D poses can map to the same 2D observations, which always results in an unreliable estimation. The other is that no sufficient occluded human data can be used for training a robust model. To address the obstacles, our key-idea is to employ non-occluded human data to learn a joint-level spatial-temporal motion prior for occluded human with a self-supervised strategy. To further reduce the gap between synthetic and real occlusion data, we build the first 3D occluded motion dataset~(OcMotion), which can be used for both training and testing. We encode the motions in 2D maps and synthesize occlusions on non-occluded data for the self-supervised training. A spatial-temporal layer is then designed to learn joint-level correlations. The learned prior reduces the ambiguities of occlusions and is robust to diverse occlusion types, which is then adopted to assist the occluded human motion capture. Experimental results show that our method can generate accurate and coherent human motions from occluded videos with good generalization ability and runtime efficiency. The dataset and code are publicly available at \url{https://github.com/boycehbz/CHOMP}.
Neural MoCon: Neural Motion Control for Physically Plausible Human Motion Capture
Mar 26, 2022



Due to the visual ambiguity, purely kinematic formulations on monocular human motion capture are often physically incorrect, biomechanically implausible, and can not reconstruct accurate interactions. In this work, we focus on exploiting the high-precision and non-differentiable physics simulator to incorporate dynamical constraints in motion capture. Our key-idea is to use real physical supervisions to train a target pose distribution prior for sampling-based motion control to capture physically plausible human motion. To obtain accurate reference motion with terrain interactions for the sampling, we first introduce an interaction constraint based on SDF (Signed Distance Field) to enforce appropriate ground contact modeling. We then design a novel two-branch decoder to avoid stochastic error from pseudo ground-truth and train a distribution prior with the non-differentiable physics simulator. Finally, we regress the sampling distribution from the current state of the physical character with the trained prior and sample satisfied target poses to track the estimated reference motion. Qualitative and quantitative results show that we can obtain physically plausible human motion with complex terrain interactions, human shape variations, and diverse behaviors. More information can be found at~\url{https://www.yangangwang.com/papers/HBZ-NM-2022-03.html}