 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws
May 22, 2026Existing scaling laws for Large Language Models (LLMs), predominantly monotonic power laws, fail to explain emerging non-monotonic phenomena such as catastrophic overtraining and quantization-induced degradation, where performance deteriorates despite increased compute. We propose the Shannon Scaling Law, a unified theoretical framework that models LLM training as information transmission over a noisy channel, grounded in the Shannon-Hartley theorem. By mapping model parameters to channel bandwidth and training tokens to signal power, our formulation explicitly captures the interaction between learning signal and intrinsic noise. This perspective reveals a fundamental Shannon capacity for LLMs: scaling model size or data without preserving a sufficient signal-to-noise ratio (SNR) inevitably amplifies noise, inducing a transition from monotonic improvement to U-shaped performance degradation. We validate our theory through experiments on Pythia and OLMo2 under perturbations, including Gaussian noise, quantization and supervised fine-tuning on math, QA and code tasks. The Shannon Scaling Law consistently outperforms classical scaling laws and recent perturbation-aware laws, achieving strong $R^2$ scores and accurately capturing loss basins missed by prior approaches. It also extrapolates: fitted on $\leq$6.9B Pythia models with $\leq$180B tokens, it predicts the unseen 12B model up to 307B tokens at pooled $R^2{=}0.847$, while monotonic baselines collapse.
The Shadow Self: Intrinsic Value Misalignment in Large Language Model Agents
Jan 24, 2026Large language model (LLM) agents with extended autonomy unlock new capabilities, but also introduce heightened challenges for LLM safety. In particular, an LLM agent may pursue objectives that deviate from human values and ethical norms, a risk known as value misalignment. Existing evaluations primarily focus on responses to explicit harmful input or robustness against system failure, while value misalignment in realistic, fully benign, and agentic settings remains largely underexplored. To fill this gap, we first formalize the Loss-of-Control risk and identify the previously underexamined Intrinsic Value Misalignment (Intrinsic VM). We then introduce IMPRESS (Intrinsic Value Misalignment Probes in REalistic Scenario Set), a scenario-driven framework for systematically assessing this risk. Following our framework, we construct benchmarks composed of realistic, fully benign, and contextualized scenarios, using a multi-stage LLM generation pipeline with rigorous quality control. We evaluate Intrinsic VM on 21 state-of-the-art LLM agents and find that it is a common and broadly observed safety risk across models. Moreover, the misalignment rates vary by motives, risk types, model scales, and architectures. While decoding strategies and hyperparameters exhibit only marginal influence, contextualization and framing mechanisms significantly shape misalignment behaviors. Finally, we conduct human verification to validate our automated judgments and assess existing mitigation strategies, such as safety prompting and guardrails, which show instability or limited effectiveness. We further demonstrate key use cases of IMPRESS across the AI Ecosystem. Our code and benchmark will be publicly released upon acceptance.
Two Is Better Than One: Rotations Scale LoRAs
May 29, 2025Scaling Low-Rank Adaptation (LoRA)-based Mixture-of-Experts (MoE) facilitates large language models (LLMs) to efficiently adapt to diverse tasks. However, traditional gating mechanisms that route inputs to the best experts may fundamentally hinder LLMs' scalability, leading to poor generalization and underfitting issues. We identify that the root cause lies in the restricted expressiveness of existing weighted-sum mechanisms, both within and outside the convex cone of LoRA representations. This motivates us to propose RadarGate, a novel geometrically inspired gating method that introduces rotational operations of LoRAs representations to boost the expressiveness and facilitate richer feature interactions among multiple LoRAs for scalable LLMs. Specifically, we first fuse each LoRA representation to other LoRAs using a learnable component and then feed the output to a rotation matrix. This matrix involves learnable parameters that define the relative angular relationship between LoRA representations. Such a simple yet effective mechanism provides an extra degree of freedom, facilitating the learning of cross-LoRA synergies and properly tracking the challenging poor generalization and underfitting issues as the number of LoRA grows. Extensive experiments on 6 public benchmarks across 21 tasks show the effectiveness of our RadarGate for scaling LoRAs. We also provide valuable insights, revealing that the rotations to each pair of representations are contrastive, encouraging closer alignment of semantically similar representations during geometrical transformation while pushing distance ones further apart. We will release our code to the community.
Advancing Expert Specialization for Better MoE
May 28, 2025

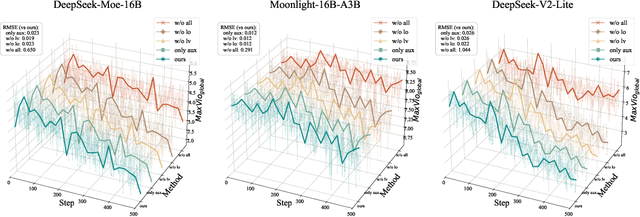

Mixture-of-Experts (MoE) models enable efficient scaling of large language models (LLMs) by activating only a subset of experts per input. However, we observe that the commonly used auxiliary load balancing loss often leads to expert overlap and overly uniform routing, which hinders expert specialization and degrades overall performance during post-training. To address this, we propose a simple yet effective solution that introduces two complementary objectives: (1) an orthogonality loss to encourage experts to process distinct types of tokens, and (2) a variance loss to encourage more discriminative routing decisions. Gradient-level analysis demonstrates that these objectives are compatible with the existing auxiliary loss and contribute to optimizing the training process. Experimental results over various model architectures and across multiple benchmarks show that our method significantly enhances expert specialization. Notably, our method improves classic MoE baselines with auxiliary loss by up to 23.79%, while also maintaining load balancing in downstream tasks, without any architectural modifications or additional components. We will release our code to contribute to the community.
Distinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning
Apr 14, 2025To track rapid changes within our water sector, Global Water Models (GWMs) need to realistically represent hydrologic systems' response patterns - such as baseflow fraction - but are hindered by their limited ability to learn from data. Here we introduce a high-resolution physics-embedded big-data-trained model as a breakthrough in reliably capturing characteristic hydrologic response patterns ('signatures') and their shifts. By realistically representing the long-term water balance, the model revealed widespread shifts - up to ~20% over 20 years - in fundamental green-blue-water partitioning and baseflow ratios worldwide. Shifts in these response patterns, previously considered static, contributed to increasing flood risks in northern mid-latitudes, heightening water supply stresses in southern subtropical regions, and declining freshwater inputs to many European estuaries, all with ecological implications. With more accurate simulations at monthly and daily scales than current operational systems, this next-generation model resolves large, nonlinear seasonal runoff responses to rainfall ('elasticity') and streamflow flashiness in semi-arid and arid regions. These metrics highlight regions with management challenges due to large water supply variability and high climate sensitivity, but also provide tools to forecast seasonal water availability. This capability newly enables global-scale models to deliver reliable and locally relevant insights for water management.
Image-Based Visual Servoing for Enhanced Cooperation of Dual-Arm Manipulation
Oct 28, 2024


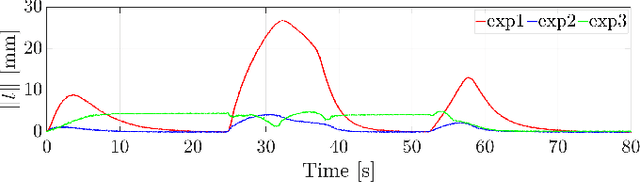
The cooperation of a pair of robot manipulators is required to manipulate a target object without any fixtures. The conventional control methods coordinate the end-effector pose of each manipulator with that of the other using their kinematics and joint coordinate measurements. Yet, the manipulators' inaccurate kinematics and joint coordinate measurements can cause significant pose synchronization errors in practice. This paper thus proposes an image-based visual servoing approach for enhancing the cooperation of a dual-arm manipulation system. On top of the classical control, the visual servoing controller lets each manipulator use its carried camera to measure the image features of the other's marker and adapt its end-effector pose with the counterpart on the move. Because visual measurements are robust to kinematic errors, the proposed control can reduce the end-effector pose synchronization errors and the fluctuations of the interaction forces of the pair of manipulators on the move. Theoretical analyses have rigorously proven the stability of the closed-loop system. Comparative experiments on real robots have substantiated the effectiveness of the proposed control.
Deliberate Reasoning for LLMs as Structure-aware Planning with Accurate World Model
Oct 04, 2024
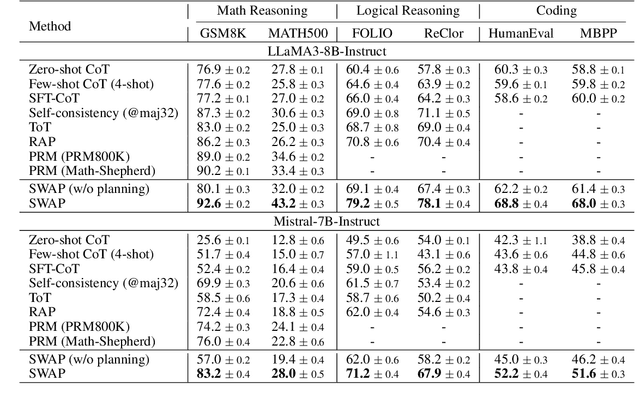


Enhancing the reasoning capabilities of large language models (LLMs) remains a key challenge, especially for tasks that require complex, multi-step decision-making. Humans excel at these tasks by leveraging deliberate planning with an internal world model to simulate the potential outcomes of various actions. Inspired by this, we propose a novel multi-step reasoning framework for LLMs, referred to as Structure-aware Planning with Accurate World Model (SWAP). Unlike previous approaches that rely solely on Chain-of-Thought (CoT) reasoning in natural language, SWAP incorporates structural information to guide the reasoning process via a world model and provides a soft verification mechanism over the steps. Moreover, SWAP overcomes the challenge of accurate world state predictions in complex reasoning tasks by introducing a Generator-Discriminator architecture, which enables more reliable world modeling. Specifically, the generator predicts the next state, and the discriminator ensures alignment with the logical consistency required by the problem context. SWAP also encourages the policy model to explore a broad range of potential actions to prevent premature convergence. By resolving the bottlenecks of generation diversity for both actions and states using diversity-based modeling (DBM) and improving discrimination accuracy through contrastive ranking (CR), SWAP significantly enhances the reasoning performance of LLMs. We evaluate SWAP across diverse reasoning-intensive benchmarks including math reasoning, logical reasoning, and coding tasks. Extensive experiments demonstrate that SWAP achieves substantial improvements over the baselines and consistently outperforms existing LLMs of similar sizes.
The Compressor-Retriever Architecture for Language Model OS
Sep 02, 2024Recent advancements in large language models (LLMs) have significantly enhanced their capacity to aggregate and process information across multiple modalities, enabling them to perform a wide range of tasks such as multimodal data querying, tool usage, web interactions, and handling long documents. These capabilities pave the way for transforming LLMs from mere chatbots into general-purpose agents capable of interacting with the real world. This paper explores the concept of using a language model as the core component of an operating system (OS), effectively acting as a CPU that processes data stored in a context window, which functions as RAM. A key challenge in realizing such an LM OS is managing the life-long context and ensuring statefulness across sessions, a feature limited by the current session-based interaction paradigm due to context window size limit. To address this, we introduce compressor-retriever, a model-agnostic architecture designed for life-long context management. Unlike other long-context solutions such as retrieval-augmented generation, our approach exclusively uses the base model's forward function to compress and retrieve context, ensuring end-to-end differentiability. Preliminary experiments demonstrate the effectiveness of this architecture in in-context learning tasks, marking a step towards the development of a fully stateful LLM OS. Project repo available at: https://github.com/gblackout/LM-OS
Can LLMs Reason in the Wild with Programs?
Jun 19, 2024Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50\%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild
TILP: Differentiable Learning of Temporal Logical Rules on Knowledge Graphs
Feb 19, 2024Compared with static knowledge graphs, temporal knowledge graphs (tKG), which can capture the evolution and change of information over time, are more realistic and general. However, due to the complexity that the notion of time introduces to the learning of the rules, an accurate graph reasoning, e.g., predicting new links between entities, is still a difficult problem. In this paper, we propose TILP, a differentiable framework for temporal logical rules learning. By designing a constrained random walk mechanism and the introduction of temporal operators, we ensure the efficiency of our model. We present temporal features modeling in tKG, e.g., recurrence, temporal order, interval between pair of relations, and duration, and incorporate it into our learning process. We compare TILP with state-of-the-art methods on two benchmark datasets. We show that our proposed framework can improve upon the performance of baseline methods while providing interpretable results. In particular, we consider various scenarios in which training samples are limited, data is biased, and the time range between training and inference are different. In all these cases, TILP works much better than the state-of-the-art methods.