 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Search-Augmented LLM Reasoning via Adaptive Information Control
Feb 02, 2026Search-augmented reasoning agents interleave multi-step reasoning with external information retrieval, but uncontrolled retrieval often leads to redundant evidence, context saturation, and unstable learning. Existing approaches rely on outcome-based reinforcement learning (RL), which provides limited guidance for regulating information acquisition. We propose DeepControl, a framework for adaptive information control based on a formal notion of information utility, which measures the marginal value of retrieved evidence under a given reasoning state. Building on this utility, we introduce retrieval continuation and granularity control mechanisms that selectively regulate when to continue and stop retrieval, and how much information to expand. An annealed control strategy enables the agent to internalize effective information acquisition behaviors during training. Extensive experiments across seven benchmarks demonstrate that our method consistently outperforms strong baselines. In particular, our approach achieves average performance improvements of 9.4% and 8.6% on Qwen2.5-7B and Qwen2.5-3B, respectively, over strong outcome-based RL baselines, and consistently outperforms both retrieval-free and retrieval-based reasoning methods without explicit information control. These results highlight the importance of adaptive information control for scaling search-augmented reasoning agents to complex, real-world information environments.
PathWise: Planning through World Model for Automated Heuristic Design via Self-Evolving LLMs
Jan 29, 2026Large Language Models (LLMs) have enabled automated heuristic design (AHD) for combinatorial optimization problems (COPs), but existing frameworks' reliance on fixed evolutionary rules and static prompt templates often leads to myopic heuristic generation, redundant evaluations, and limited reasoning about how new heuristics should be derived. We propose a novel multi-agent reasoning framework, referred to as Planning through World Model for Automated Heuristic Design via Self-Evolving LLMs (PathWise), which formulates heuristic generation as a sequential decision process over an entailment graph serving as a compact, stateful memory of the search trajectory. This approach allows the system to carry forward past decisions and reuse or avoid derivation information across generations. A policy agent plans evolutionary actions, a world model agent generates heuristic rollouts conditioned on those actions, and critic agents provide routed reflections summarizing lessons from prior steps, shifting LLM-based AHD from trial-and-error evolution toward state-aware planning through reasoning. Experiments across diverse COPs show that PathWise converges faster to better heuristics, generalizes across different LLM backbones, and scales to larger problem sizes.
Differentiable Cyclic Causal Discovery Under Unmeasured Confounders
Aug 11, 2025



Understanding causal relationships between variables is fundamental across scientific disciplines. Most causal discovery algorithms rely on two key assumptions: (i) all variables are observed, and (ii) the underlying causal graph is acyclic. While these assumptions simplify theoretical analysis, they are often violated in real-world systems, such as biological networks. Existing methods that account for confounders either assume linearity or struggle with scalability. To address these limitations, we propose DCCD-CONF, a novel framework for differentiable learning of nonlinear cyclic causal graphs in the presence of unmeasured confounders using interventional data. Our approach alternates between optimizing the graph structure and estimating the confounder distribution by maximizing the log-likelihood of the data. Through experiments on synthetic data and real-world gene perturbation datasets, we show that DCCD-CONF outperforms state-of-the-art methods in both causal graph recovery and confounder identification. Additionally, we also provide consistency guarantees for our framework, reinforcing its theoretical soundness.
Learning Hidden Subgoals under Temporal Ordering Constraints in Reinforcement Learning
Nov 03, 2024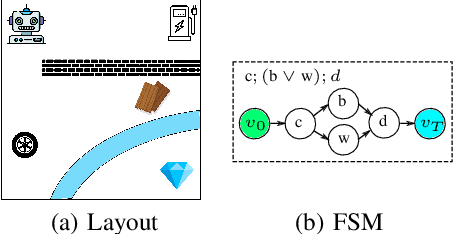

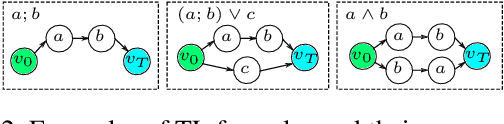
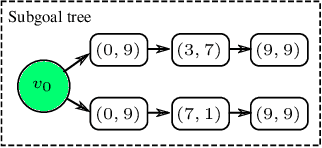
In real-world applications, the success of completing a task is often determined by multiple key steps which are distant in time steps and have to be achieved in a fixed time order. For example, the key steps listed on the cooking recipe should be achieved one-by-one in the right time order. These key steps can be regarded as subgoals of the task and their time orderings are described as temporal ordering constraints. However, in many real-world problems, subgoals or key states are often hidden in the state space and their temporal ordering constraints are also unknown, which make it challenging for previous RL algorithms to solve this kind of tasks. In order to address this issue, in this work we propose a novel RL algorithm for {\bf l}earning hidden {\bf s}ubgoals under {\bf t}emporal {\bf o}rdering {\bf c}onstraints (LSTOC). We propose a new contrastive learning objective which can effectively learn hidden subgoals (key states) and their temporal orderings at the same time, based on first-occupancy representation and temporal geometric sampling. In addition, we propose a sample-efficient learning strategy to discover subgoals one-by-one following their temporal order constraints by building a subgoal tree to represent discovered subgoals and their temporal ordering relationships. Specifically, this tree can be used to improve the sample efficiency of trajectory collection, fasten the task solving and generalize to unseen tasks. The LSTOC framework is evaluated on several environments with image-based observations, showing its significant improvement over baseline methods.
MissNODAG: Differentiable Cyclic Causal Graph Learning from Incomplete Data
Oct 24, 2024



Causal discovery in real-world systems, such as biological networks, is often complicated by feedback loops and incomplete data. Standard algorithms, which assume acyclic structures or fully observed data, struggle with these challenges. To address this gap, we propose MissNODAG, a differentiable framework for learning both the underlying cyclic causal graph and the missingness mechanism from partially observed data, including data missing not at random. Our framework integrates an additive noise model with an expectation-maximization procedure, alternating between imputing missing values and optimizing the observed data likelihood, to uncover both the cyclic structures and the missingness mechanism. We demonstrate the effectiveness of MissNODAG through synthetic experiments and an application to real-world gene perturbation data.
Generalization of Compositional Tasks with Logical Specification via Implicit Planning
Oct 13, 2024



In this work, we study the problem of learning generalizable policies for compositional tasks given by a logic specification. These tasks are composed by temporally extended subgoals. Due to dependencies of subgoals and long task horizon, previous reinforcement learning (RL) algorithms, e.g., task-conditioned and goal-conditioned policies, still suffer from slow convergence and sub-optimality when solving the generalization problem of compositional tasks. In order to tackle these issues, this paper proposes a new hierarchical RL framework for the efficient and optimal generalization of compositional tasks. In the high level, we propose a new implicit planner designed specifically for generalizing compositional tasks. Specifically, the planner produces the selection of next sub-task and estimates the multi-step return of completing the rest of task from current state. It learns a latent transition model and conducts planning in the latent space based on a graph neural network (GNN). Then, the next sub-task selected by the high level guides the low-level agent efficiently to solve long-horizon tasks and the multi-step return makes the low-level policy consider dependencies of future sub-tasks. We conduct comprehensive experiments to show the advantage of proposed framework over previous methods in terms of optimality and efficiency.
Deliberate Reasoning for LLMs as Structure-aware Planning with Accurate World Model
Oct 04, 2024
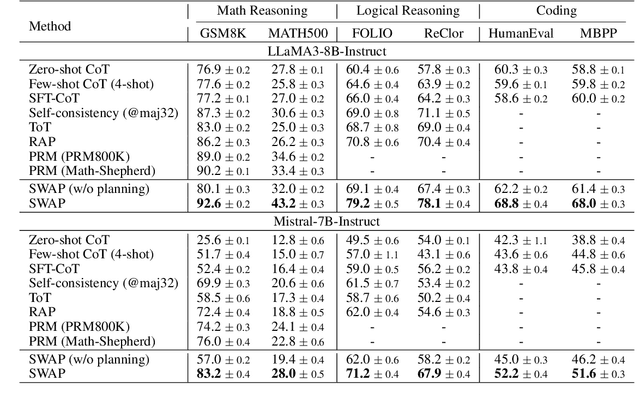


Enhancing the reasoning capabilities of large language models (LLMs) remains a key challenge, especially for tasks that require complex, multi-step decision-making. Humans excel at these tasks by leveraging deliberate planning with an internal world model to simulate the potential outcomes of various actions. Inspired by this, we propose a novel multi-step reasoning framework for LLMs, referred to as Structure-aware Planning with Accurate World Model (SWAP). Unlike previous approaches that rely solely on Chain-of-Thought (CoT) reasoning in natural language, SWAP incorporates structural information to guide the reasoning process via a world model and provides a soft verification mechanism over the steps. Moreover, SWAP overcomes the challenge of accurate world state predictions in complex reasoning tasks by introducing a Generator-Discriminator architecture, which enables more reliable world modeling. Specifically, the generator predicts the next state, and the discriminator ensures alignment with the logical consistency required by the problem context. SWAP also encourages the policy model to explore a broad range of potential actions to prevent premature convergence. By resolving the bottlenecks of generation diversity for both actions and states using diversity-based modeling (DBM) and improving discrimination accuracy through contrastive ranking (CR), SWAP significantly enhances the reasoning performance of LLMs. We evaluate SWAP across diverse reasoning-intensive benchmarks including math reasoning, logical reasoning, and coding tasks. Extensive experiments demonstrate that SWAP achieves substantial improvements over the baselines and consistently outperforms existing LLMs of similar sizes.
LLM-Augmented Symbolic Reinforcement Learning with Landmark-Based Task Decomposition
Oct 02, 2024

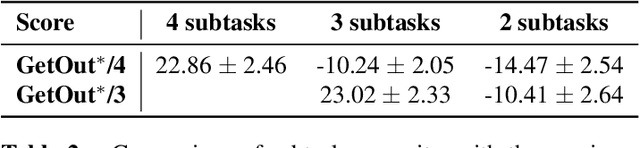

One of the fundamental challenges in reinforcement learning (RL) is to take a complex task and be able to decompose it to subtasks that are simpler for the RL agent to learn. In this paper, we report on our work that would identify subtasks by using some given positive and negative trajectories for solving the complex task. We assume that the states are represented by first-order predicate logic using which we devise a novel algorithm to identify the subtasks. Then we employ a Large Language Model (LLM) to generate first-order logic rule templates for achieving each subtask. Such rules were then further fined tuned to a rule-based policy via an Inductive Logic Programming (ILP)-based RL agent. Through experiments, we verify the accuracy of our algorithm in detecting subtasks which successfully detect all of the subtasks correctly. We also investigated the quality of the common-sense rules produced by the language model to achieve the subtasks. Our experiments show that our LLM-guided rule template generation can produce rules that are necessary for solving a subtask, which leads to solving complex tasks with fewer assumptions about predefined first-order logic predicates of the environment.
The Compressor-Retriever Architecture for Language Model OS
Sep 02, 2024Recent advancements in large language models (LLMs) have significantly enhanced their capacity to aggregate and process information across multiple modalities, enabling them to perform a wide range of tasks such as multimodal data querying, tool usage, web interactions, and handling long documents. These capabilities pave the way for transforming LLMs from mere chatbots into general-purpose agents capable of interacting with the real world. This paper explores the concept of using a language model as the core component of an operating system (OS), effectively acting as a CPU that processes data stored in a context window, which functions as RAM. A key challenge in realizing such an LM OS is managing the life-long context and ensuring statefulness across sessions, a feature limited by the current session-based interaction paradigm due to context window size limit. To address this, we introduce compressor-retriever, a model-agnostic architecture designed for life-long context management. Unlike other long-context solutions such as retrieval-augmented generation, our approach exclusively uses the base model's forward function to compress and retrieve context, ensuring end-to-end differentiability. Preliminary experiments demonstrate the effectiveness of this architecture in in-context learning tasks, marking a step towards the development of a fully stateful LLM OS. Project repo available at: https://github.com/gblackout/LM-OS
Can LLMs Reason in the Wild with Programs?
Jun 19, 2024Large Language Models (LLMs) have shown superior capability to solve reasoning problems with programs. While being a promising direction, most of such frameworks are trained and evaluated in settings with a prior knowledge of task requirements. However, as LLMs become more capable, it is necessary to assess their reasoning abilities in more realistic scenarios where many real-world problems are open-ended with ambiguous scope, and often require multiple formalisms to solve. To investigate this, we introduce the task of reasoning in the wild, where an LLM is tasked to solve a reasoning problem of unknown type by identifying the subproblems and their corresponding formalisms, and writing a program to solve each subproblem, guided by a tactic. We create a large tactic-guided trajectory dataset containing detailed solutions to a diverse set of reasoning problems, ranging from well-defined single-form reasoning (e.g., math, logic), to ambiguous and hybrid ones (e.g., commonsense, combined math and logic). This allows us to test various aspects of LLMs reasoning at the fine-grained level such as the selection and execution of tactics, and the tendency to take undesired shortcuts. In experiments, we highlight that existing LLMs fail significantly on problems with ambiguous and mixed scope, revealing critical limitations and overfitting issues (e.g. accuracy on GSM8K drops by at least 50\%). We further show the potential of finetuning a local LLM on the tactic-guided trajectories in achieving better performance. Project repo is available at github.com/gblackout/Reason-in-the-Wild