 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHFT: Efficient Federated Finetuning with Heterogeneous Edge Clients
Oct 15, 2025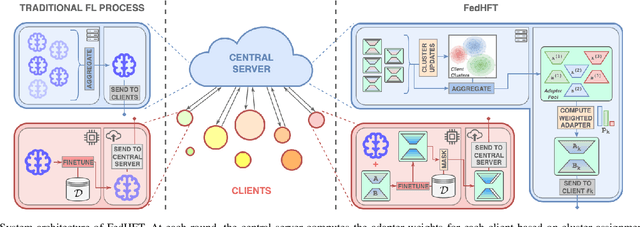
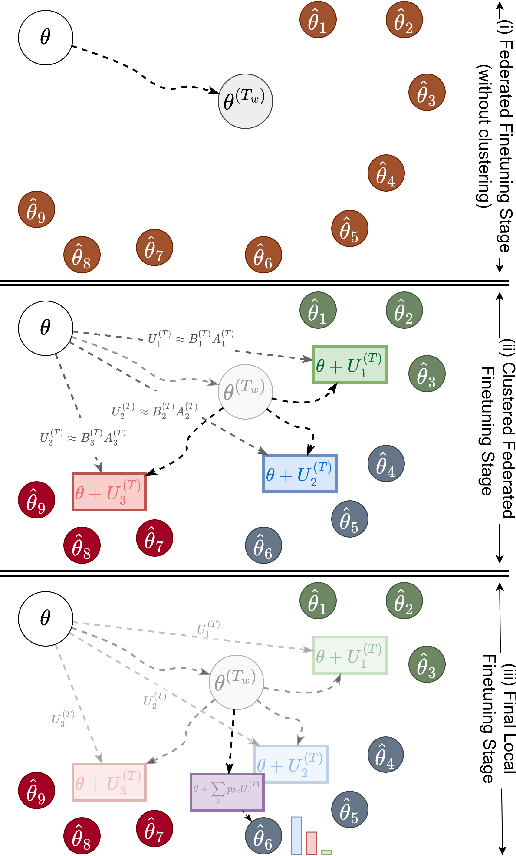
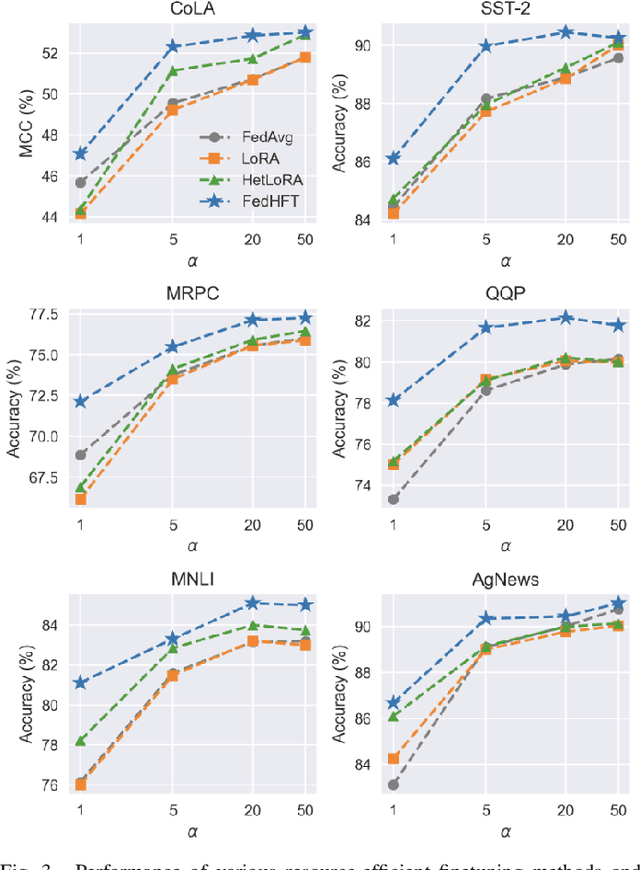
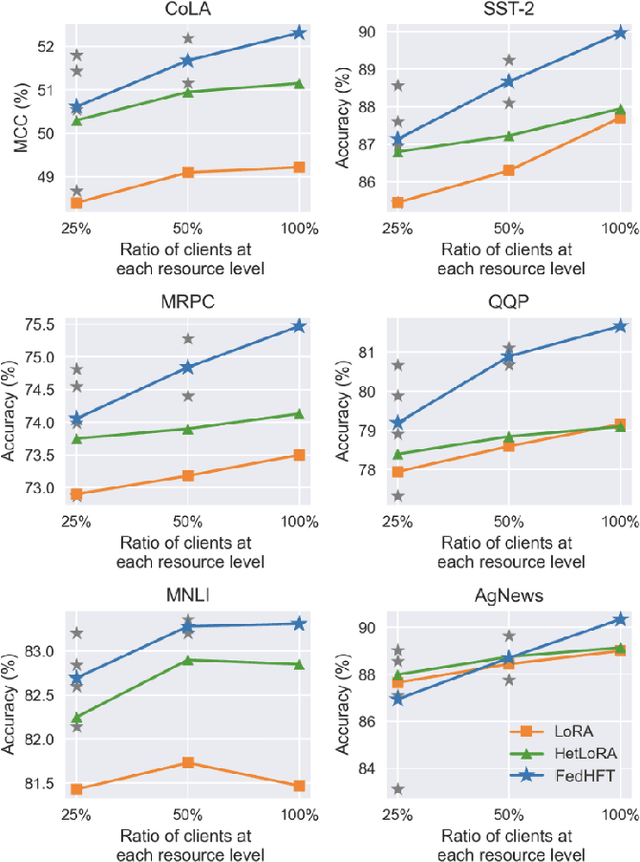
Fine-tuning pre-trained large language models (LLMs) has become a common practice for personalized natural language understanding (NLU) applications on downstream tasks and domain-specific datasets. However, there are two main challenges: (i) limited and/or heterogeneous data for fine-tuning due to proprietary data confidentiality or privacy requirements, and (ii) varying computation resources available across participating clients such as edge devices. This paper presents FedHFT - an efficient and personalized federated fine-tuning framework to address both challenges. First, we introduce a mixture of masked adapters to handle resource heterogeneity across participating clients, enabling high-performance collaborative fine-tuning of pre-trained language model(s) across multiple clients in a distributed setting, while keeping proprietary data local. Second, we introduce a bi-level optimization approach to handle non-iid data distribution based on masked personalization and client clustering. Extensive experiments demonstrate significant performance and efficiency improvements over various natural language understanding tasks under data and resource heterogeneity compared to representative heterogeneous federated learning methods.
A First-order Generative Bilevel Optimization Framework for Diffusion Models
Feb 12, 2025Diffusion models, which iteratively denoise data samples to synthesize high-quality outputs, have achieved empirical success across domains. However, optimizing these models for downstream tasks often involves nested bilevel structures, such as tuning hyperparameters for fine-tuning tasks or noise schedules in training dynamics, where traditional bilevel methods fail due to the infinite-dimensional probability space and prohibitive sampling costs. We formalize this challenge as a generative bilevel optimization problem and address two key scenarios: (1) fine-tuning pre-trained models via an inference-only lower-level solver paired with a sample-efficient gradient estimator for the upper level, and (2) training diffusion models from scratch with noise schedule optimization by reparameterizing the lower-level problem and designing a computationally tractable gradient estimator. Our first-order bilevel framework overcomes the incompatibility of conventional bilevel methods with diffusion processes, offering theoretical grounding and computational practicality. Experiments demonstrate that our method outperforms existing fine-tuning and hyperparameter search baselines.
Prompt Diffusion Robustifies Any-Modality Prompt Learning
Oct 26, 2024



Foundation models enable prompt-based classifiers for zero-shot and few-shot learning. Nonetheless, the conventional method of employing fixed prompts suffers from distributional shifts that negatively impact generalizability to unseen samples. This paper introduces prompt diffusion, which uses a diffusion model to gradually refine the prompts to obtain a customized prompt for each sample. Specifically, we first optimize a collection of prompts to obtain over-fitted prompts per sample. Then, we propose a prompt diffusion model within the prompt space, enabling the training of a generative transition process from a random prompt to its overfitted prompt. As we cannot access the label of a test image during inference, our model gradually generates customized prompts solely from random prompts using our trained, prompt diffusion. Our prompt diffusion is generic, flexible, and modality-agnostic, making it a simple plug-and-play module seamlessly embedded into existing prompt learning methods for textual, visual, or multi-modal prompt learning. Our diffusion model uses a fast ODE-based sampling strategy to optimize test sample prompts in just five steps, offering a good trade-off between performance improvement and computational efficiency. For all prompt learning methods tested, adding prompt diffusion yields more robust results for base-to-new generalization, cross-dataset generalization, and domain generalization in classification tasks tested over 15 diverse datasets.
A Survey on Large Language Model-Based Game Agents
Apr 02, 2024
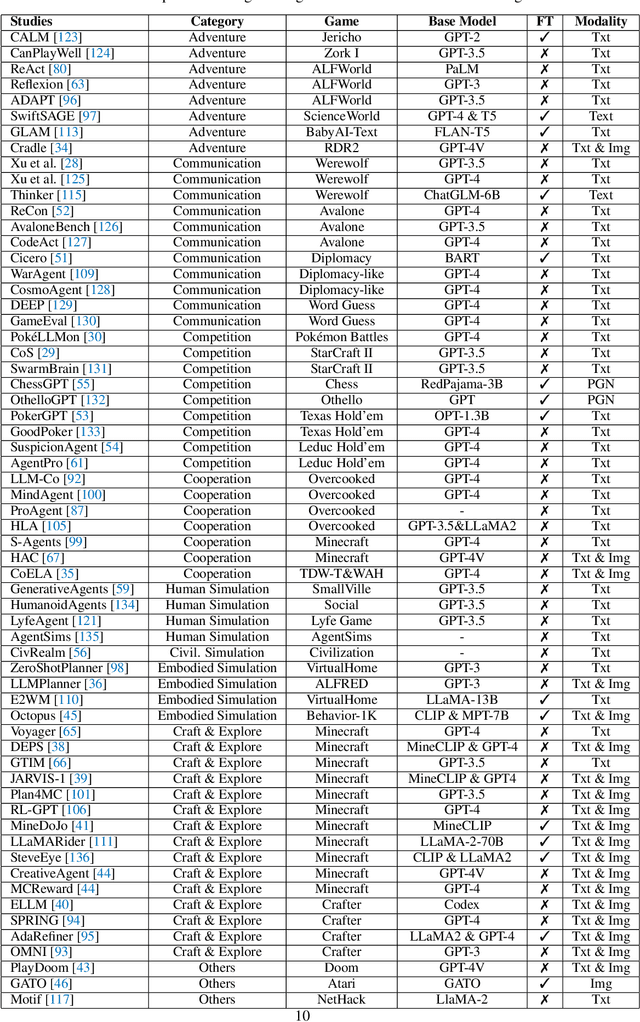


The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
Training-Free Semantic Segmentation via LLM-Supervision
Mar 31, 2024



Recent advancements in open vocabulary models, like CLIP, have notably advanced zero-shot classification and segmentation by utilizing natural language for class-specific embeddings. However, most research has focused on improving model accuracy through prompt engineering, prompt learning, or fine-tuning with limited labeled data, thereby overlooking the importance of refining the class descriptors. This paper introduces a new approach to text-supervised semantic segmentation using supervision by a large language model (LLM) that does not require extra training. Our method starts from an LLM, like GPT-3, to generate a detailed set of subclasses for more accurate class representation. We then employ an advanced text-supervised semantic segmentation model to apply the generated subclasses as target labels, resulting in diverse segmentation results tailored to each subclass's unique characteristics. Additionally, we propose an assembly that merges the segmentation maps from the various subclass descriptors to ensure a more comprehensive representation of the different aspects in the test images. Through comprehensive experiments on three standard benchmarks, our method outperforms traditional text-supervised semantic segmentation methods by a marked margin.
Large Language Models Can Learn Temporal Reasoning
Jan 12, 2024


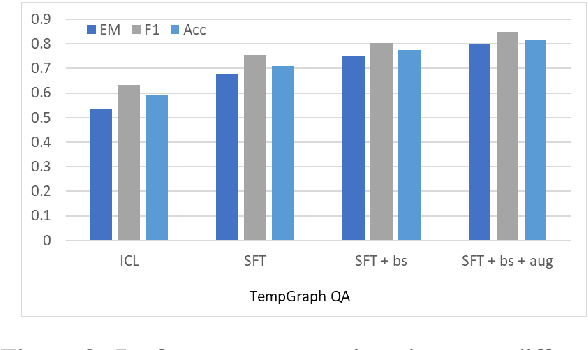
Large language models (LLMs) learn temporal concepts from the co-occurrence of related tokens in a sequence. Compared with conventional text generation, temporal reasoning, which reaches a conclusion based on mathematical, logical and commonsense knowledge, is more challenging. In this paper, we propose TempGraph-LLM, a new paradigm towards text-based temporal reasoning. To be specific, we first teach LLMs to translate the context into a temporal graph. A synthetic dataset, which is fully controllable and requires minimal supervision, is constructed for pre-training on this task. We prove in experiments that LLMs benefit from the pre-training on other tasks. On top of that, we guide LLMs to perform symbolic reasoning with the strategies of Chain of Thoughts (CoTs) bootstrapping and special data augmentation. We observe that CoTs with symbolic reasoning bring more consistent and reliable results than those using free text.
Causal-DFQ: Causality Guided Data-free Network Quantization
Sep 24, 2023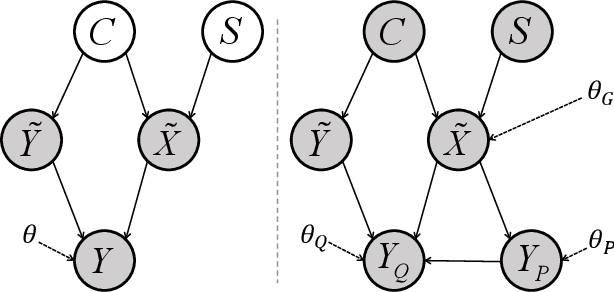
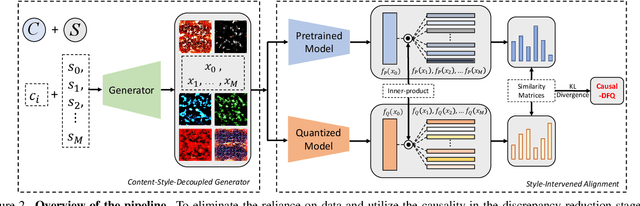
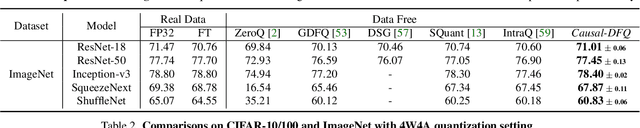
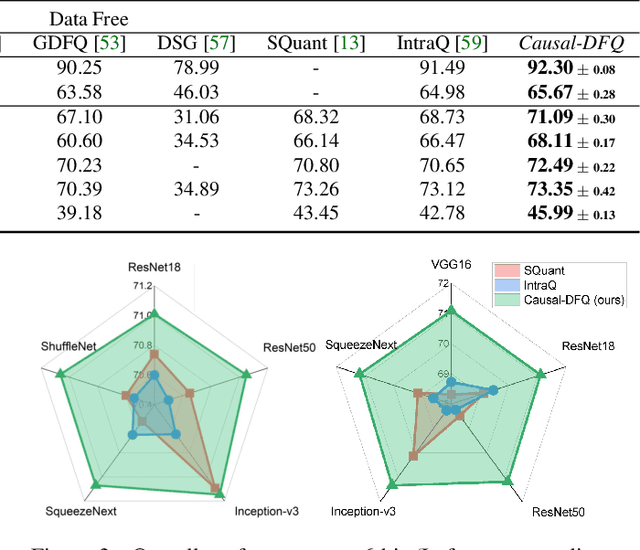
Model quantization, which aims to compress deep neural networks and accelerate inference speed, has greatly facilitated the development of cumbersome models on mobile and edge devices. There is a common assumption in quantization methods from prior works that training data is available. In practice, however, this assumption cannot always be fulfilled due to reasons of privacy and security, rendering these methods inapplicable in real-life situations. Thus, data-free network quantization has recently received significant attention in neural network compression. Causal reasoning provides an intuitive way to model causal relationships to eliminate data-driven correlations, making causality an essential component of analyzing data-free problems. However, causal formulations of data-free quantization are inadequate in the literature. To bridge this gap, we construct a causal graph to model the data generation and discrepancy reduction between the pre-trained and quantized models. Inspired by the causal understanding, we propose the Causality-guided Data-free Network Quantization method, Causal-DFQ, to eliminate the reliance on data via approaching an equilibrium of causality-driven intervened distributions. Specifically, we design a content-style-decoupled generator, synthesizing images conditioned on the relevant and irrelevant factors; then we propose a discrepancy reduction loss to align the intervened distributions of the pre-trained and quantized models. It is worth noting that our work is the first attempt towards introducing causality to data-free quantization problem. Extensive experiments demonstrate the efficacy of Causal-DFQ. The code is available at https://github.com/42Shawn/Causal-DFQ.
Fast and Resource-Efficient Object Tracking on Edge Devices: A Measurement Study
Sep 06, 2023

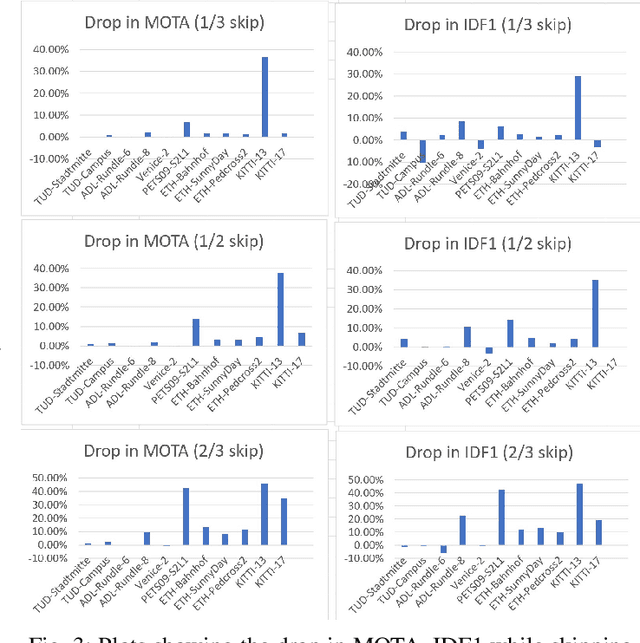
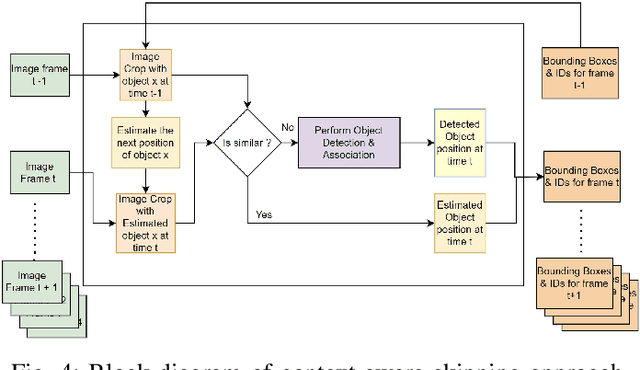
Object tracking is an important functionality of edge video analytic systems and services. Multi-object tracking (MOT) detects the moving objects and tracks their locations frame by frame as real scenes are being captured into a video. However, it is well known that real time object tracking on the edge poses critical technical challenges, especially with edge devices of heterogeneous computing resources. This paper examines the performance issues and edge-specific optimization opportunities for object tracking. We will show that even the well trained and optimized MOT model may still suffer from random frame dropping problems when edge devices have insufficient computation resources. We present several edge specific performance optimization strategies, collectively coined as EMO, to speed up the real time object tracking, ranging from window-based optimization to similarity based optimization. Extensive experiments on popular MOT benchmarks demonstrate that our EMO approach is competitive with respect to the representative methods for on-device object tracking techniques in terms of run-time performance and tracking accuracy. EMO is released on Github at https://github.com/git-disl/EMO.
Mitigating Group Bias in Federated Learning: Beyond Local Fairness
May 17, 2023



The issue of group fairness in machine learning models, where certain sub-populations or groups are favored over others, has been recognized for some time. While many mitigation strategies have been proposed in centralized learning, many of these methods are not directly applicable in federated learning, where data is privately stored on multiple clients. To address this, many proposals try to mitigate bias at the level of clients before aggregation, which we call locally fair training. However, the effectiveness of these approaches is not well understood. In this work, we investigate the theoretical foundation of locally fair training by studying the relationship between global model fairness and local model fairness. Additionally, we prove that for a broad class of fairness metrics, the global model's fairness can be obtained using only summary statistics from local clients. Based on that, we propose a globally fair training algorithm that directly minimizes the penalized empirical loss. Real-data experiments demonstrate the promising performance of our proposed approach for enhancing fairness while retaining high accuracy compared to locally fair training methods.
EENet: Learning to Early Exit for Adaptive Inference
Jan 15, 2023Budgeted adaptive inference with early exits is an emerging technique to improve the computational efficiency of deep neural networks (DNNs) for edge AI applications with limited resources at test time. This method leverages the fact that different test data samples may not require the same amount of computation for a correct prediction. By allowing early exiting from full layers of DNN inference for some test examples, we can reduce latency and improve throughput of edge inference while preserving performance. Although there have been numerous studies on designing specialized DNN architectures for training early-exit enabled DNN models, most of the existing work employ hand-tuned or manual rule-based early exit policies. In this study, we introduce a novel multi-exit DNN inference framework, coined as EENet, which leverages multi-objective learning to optimize the early exit policy for a trained multi-exit DNN under a given inference budget. This paper makes two novel contributions. First, we introduce the concept of early exit utility scores by combining diverse confidence measures with class-wise prediction scores to better estimate the correctness of test-time predictions at a given exit. Second, we train a lightweight, budget-driven, multi-objective neural network over validation predictions to learn the exit assignment scheduling for query examples at test time. The EENet early exit scheduler optimizes both the distribution of test samples to different exits and the selection of the exit utility thresholds such that the given inference budget is satisfied while the performance metric is maximized. Extensive experiments are conducted on five benchmarks, including three image datasets (CIFAR-10, CIFAR-100, ImageNet) and two NLP datasets (SST-2, AgNews). The results demonstrate the performance improvements of EENet compared to existing representative early exit techniques.