 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025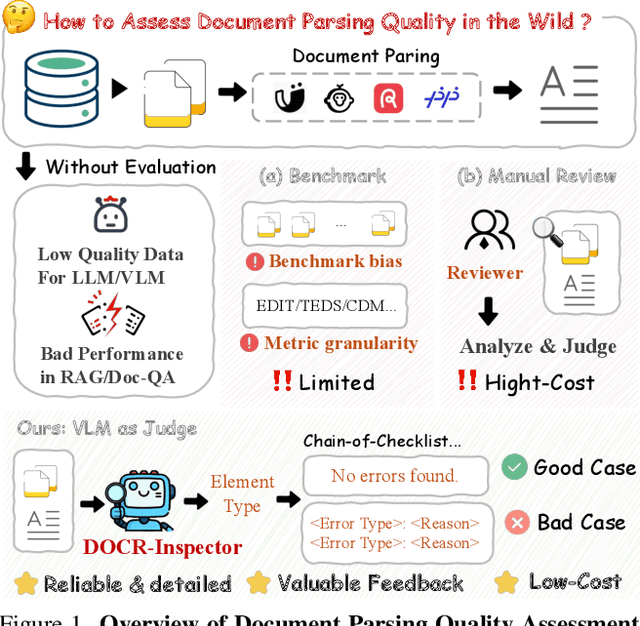
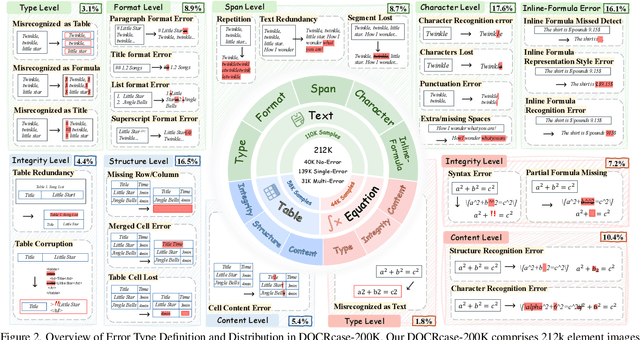

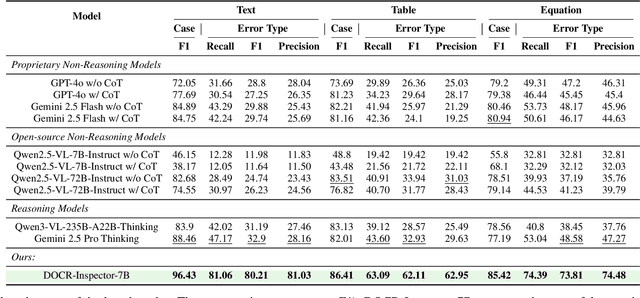
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
Building Gradient Bridges: Label Leakage from Restricted Gradient Sharing in Federated Learning
Dec 17, 2024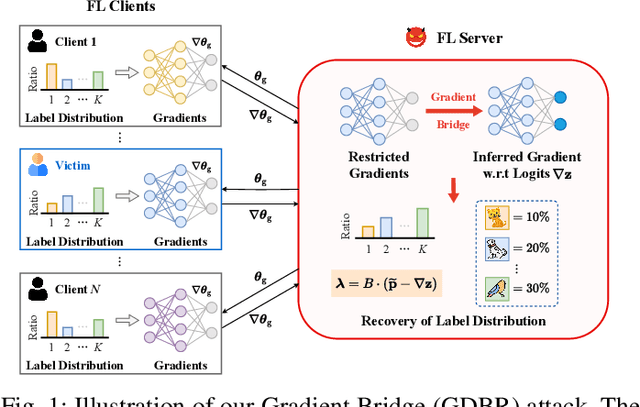

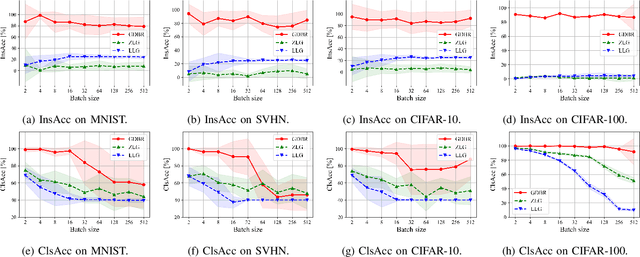

The growing concern over data privacy, the benefits of utilizing data from diverse sources for model training, and the proliferation of networked devices with enhanced computational capabilities have all contributed to the rise of federated learning (FL). The clients in FL collaborate to train a global model by uploading gradients computed on their private datasets without collecting raw data. However, a new attack surface has emerged from gradient sharing, where adversaries can restore the label distribution of a victim's private data by analyzing the obtained gradients. To mitigate this privacy leakage, existing lightweight defenses restrict the sharing of gradients, such as encrypting the final-layer gradients or locally updating the parameters within. In this paper, we introduce a novel attack called Gradient Bridge (GDBR) that recovers the label distribution of training data from the limited gradient information shared in FL. GDBR explores the relationship between the layer-wise gradients, tracks the flow of gradients, and analytically derives the batch training labels. Extensive experiments show that GDBR can accurately recover more than 80% of labels in various FL settings. GDBR highlights the inadequacy of restricted gradient sharing-based defenses and calls for the design of effective defense schemes in FL.
Understanding the Impact of Graph Reduction on Adversarial Robustness in Graph Neural Networks
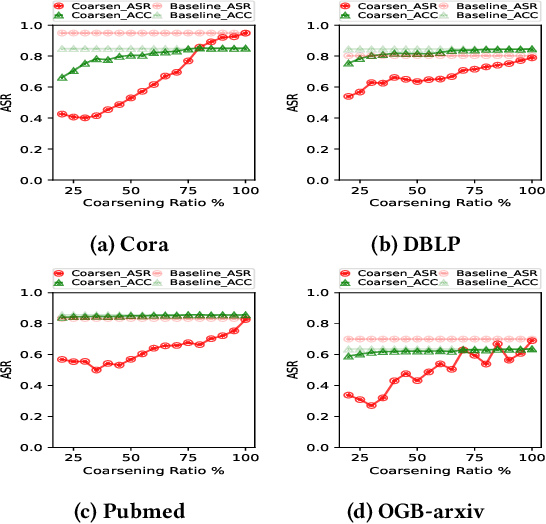
Dec 08, 2024As Graph Neural Networks (GNNs) become increasingly popular for learning from large-scale graph data across various domains, their susceptibility to adversarial attacks when using graph reduction techniques for scalability remains underexplored. In this paper, we present an extensive empirical study to investigate the impact of graph reduction techniques, specifically graph coarsening and sparsification, on the robustness of GNNs against adversarial attacks. Through extensive experiments involving multiple datasets and GNN architectures, we examine the effects of four sparsification and six coarsening methods on the poisoning attacks. Our results indicate that, while graph sparsification can mitigate the effectiveness of certain poisoning attacks, such as Mettack, it has limited impact on others, like PGD. Conversely, graph coarsening tends to amplify the adversarial impact, significantly reducing classification accuracy as the reduction ratio decreases. Additionally, we provide a novel analysis of the causes driving these effects and examine how defensive GNN models perform under graph reduction, offering practical insights for designing robust GNNs within graph acceleration systems.
OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation
Dec 03, 2024Retrieval-augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external knowledge to reduce hallucinations and incorporate up-to-date information without retraining. As an essential part of RAG, external knowledge bases are commonly built by extracting structured data from unstructured PDF documents using Optical Character Recognition (OCR). However, given the imperfect prediction of OCR and the inherent non-uniform representation of structured data, knowledge bases inevitably contain various OCR noises. In this paper, we introduce OHRBench, the first benchmark for understanding the cascading impact of OCR on RAG systems. OHRBench includes 350 carefully selected unstructured PDF documents from six real-world RAG application domains, along with Q&As derived from multimodal elements in documents, challenging existing OCR solutions used for RAG To better understand OCR's impact on RAG systems, we identify two primary types of OCR noise: Semantic Noise and Formatting Noise and apply perturbation to generate a set of structured data with varying degrees of each OCR noise. Using OHRBench, we first conduct a comprehensive evaluation of current OCR solutions and reveal that none is competent for constructing high-quality knowledge bases for RAG systems. We then systematically evaluate the impact of these two noise types and demonstrate the vulnerability of RAG systems. Furthermore, we discuss the potential of employing Vision-Language Models (VLMs) without OCR in RAG systems. Code: https://github.com/opendatalab/OHR-Bench
Geminio: Language-Guided Gradient Inversion Attacks in Federated Learning
Nov 22, 2024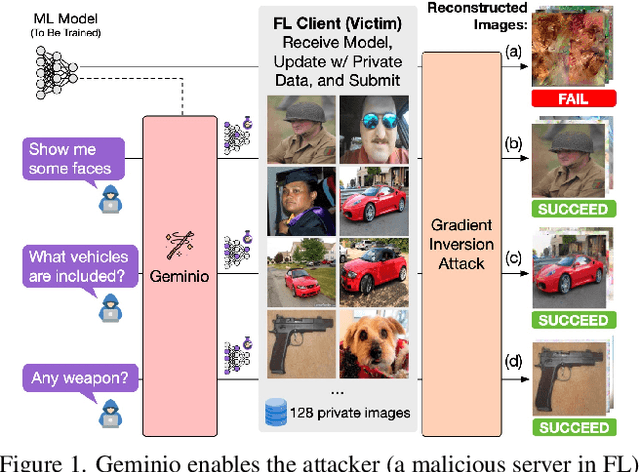

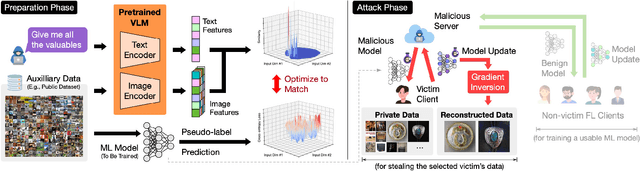
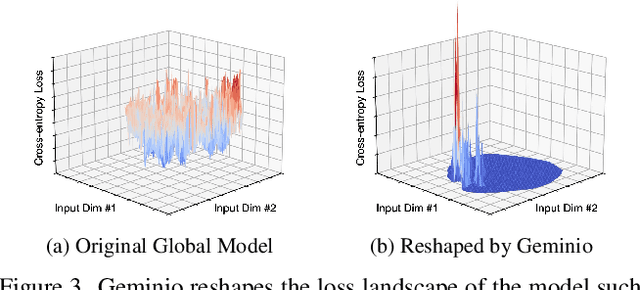
Foundation models that bridge vision and language have made significant progress, inspiring numerous life-enriching applications. However, their potential for misuse to introduce new threats remains largely unexplored. This paper reveals that vision-language models (VLMs) can be exploited to overcome longstanding limitations in gradient inversion attacks (GIAs) within federated learning (FL), where an FL server reconstructs private data samples from gradients shared by victim clients. Current GIAs face challenges in reconstructing high-resolution images, especially when the victim has a large local data batch. While focusing reconstruction on valuable samples rather than the entire batch is promising, existing methods lack the flexibility to allow attackers to specify their target data. In this paper, we introduce Geminio, the first approach to transform GIAs into semantically meaningful, targeted attacks. Geminio enables a brand new privacy attack experience: attackers can describe, in natural language, the types of data they consider valuable, and Geminio will prioritize reconstruction to focus on those high-value samples. This is achieved by leveraging a pretrained VLM to guide the optimization of a malicious global model that, when shared with and optimized by a victim, retains only gradients of samples that match the attacker-specified query. Extensive experiments demonstrate Geminio's effectiveness in pinpointing and reconstructing targeted samples, with high success rates across complex datasets under FL and large batch sizes and showing resilience against existing defenses.
AnywhereDoor: Multi-Target Backdoor Attacks on Object Detection
Nov 21, 2024



As object detection becomes integral to many safety-critical applications, understanding its vulnerabilities is essential. Backdoor attacks, in particular, pose a significant threat by implanting hidden backdoor in a victim model, which adversaries can later exploit to trigger malicious behaviors during inference. However, current backdoor techniques are limited to static scenarios where attackers must define a malicious objective before training, locking the attack into a predetermined action without inference-time adaptability. Given the expressive output space in object detection, including object existence detection, bounding box estimation, and object classification, the feasibility of implanting a backdoor that provides inference-time control with a high degree of freedom remains unexplored. This paper introduces AnywhereDoor, a flexible backdoor attack tailored for object detection. Once implanted, AnywhereDoor enables adversaries to specify different attack types (object vanishing, fabrication, or misclassification) and configurations (untargeted or targeted with specific classes) to dynamically control detection behavior. This flexibility is achieved through three key innovations: (i) objective disentanglement to support a broader range of attack combinations well beyond what existing methods allow; (ii) trigger mosaicking to ensure backdoor activations are robust, even against those object detectors that extract localized regions from the input image for recognition; and (iii) strategic batching to address object-level data imbalances that otherwise hinders a balanced manipulation. Extensive experiments demonstrate that AnywhereDoor provides attackers with a high degree of control, achieving an attack success rate improvement of nearly 80% compared to adaptations of existing methods for such flexible control.
Personalized Privacy Protection Mask Against Unauthorized Facial Recognition
Jul 19, 2024



Face recognition (FR) can be abused for privacy intrusion. Governments, private companies, or even individual attackers can collect facial images by web scraping to build an FR system identifying human faces without their consent. This paper introduces Chameleon, which learns to generate a user-centric personalized privacy protection mask, coined as P3-Mask, to protect facial images against unauthorized FR with three salient features. First, we use a cross-image optimization to generate one P3-Mask for each user instead of tailoring facial perturbation for each facial image of a user. It enables efficient and instant protection even for users with limited computing resources. Second, we incorporate a perceptibility optimization to preserve the visual quality of the protected facial images. Third, we strengthen the robustness of P3-Mask against unknown FR models by integrating focal diversity-optimized ensemble learning into the mask generation process. Extensive experiments on two benchmark datasets show that Chameleon outperforms three state-of-the-art methods with instant protection and minimal degradation of image quality. Furthermore, Chameleon enables cost-effective FR authorization using the P3-Mask as a personalized de-obfuscation key, and it demonstrates high resilience against adaptive adversaries.
On the Robustness of Graph Reduction Against GNN Backdoor
Jul 02, 2024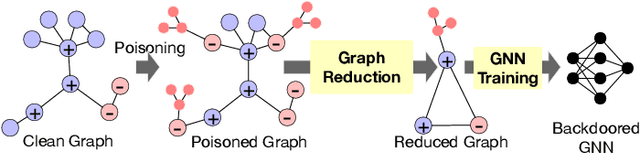


Graph Neural Networks (GNNs) are gaining popularity across various domains due to their effectiveness in learning graph-structured data. Nevertheless, they have been shown to be susceptible to backdoor poisoning attacks, which pose serious threats to real-world applications. Meanwhile, graph reduction techniques, including coarsening and sparsification, which have long been employed to improve the scalability of large graph computational tasks, have recently emerged as effective methods for accelerating GNN training on large-scale graphs. However, the current development and deployment of graph reduction techniques for large graphs overlook the potential risks of data poisoning attacks against GNNs. It is not yet clear how graph reduction interacts with existing backdoor attacks. This paper conducts a thorough examination of the robustness of graph reduction methods in scalable GNN training in the presence of state-of-the-art backdoor attacks. We performed a comprehensive robustness analysis across six coarsening methods and six sparsification methods for graph reduction, under three GNN backdoor attacks against three GNN architectures. Our findings indicate that the effectiveness of graph reduction methods in mitigating attack success rates varies significantly, with some methods even exacerbating the attacks. Through detailed analyses of triggers and poisoned nodes, we interpret our findings and enhance our understanding of how graph reduction interacts with backdoor attacks. These results highlight the critical need for incorporating robustness considerations in graph reduction for GNN training, ensuring that enhancements in computational efficiency do not compromise the security of GNN systems.
On the Efficiency of Privacy Attacks in Federated Learning
Apr 15, 2024
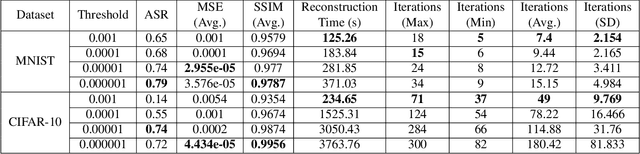
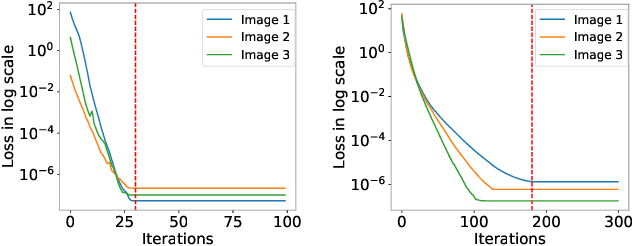

Recent studies have revealed severe privacy risks in federated learning, represented by Gradient Leakage Attacks. However, existing studies mainly aim at increasing the privacy attack success rate and overlook the high computation costs for recovering private data, making the privacy attack impractical in real applications. In this study, we examine privacy attacks from the perspective of efficiency and propose a framework for improving the Efficiency of Privacy Attacks in Federated Learning (EPAFL). We make three novel contributions. First, we systematically evaluate the computational costs for representative privacy attacks in federated learning, which exhibits a high potential to optimize efficiency. Second, we propose three early-stopping techniques to effectively reduce the computational costs of these privacy attacks. Third, we perform experiments on benchmark datasets and show that our proposed method can significantly reduce computational costs and maintain comparable attack success rates for state-of-the-art privacy attacks in federated learning. We provide the codes on GitHub at https://github.com/mlsysx/EPAFL.
Robust Few-Shot Ensemble Learning with Focal Diversity-Based Pruning
Apr 05, 2024
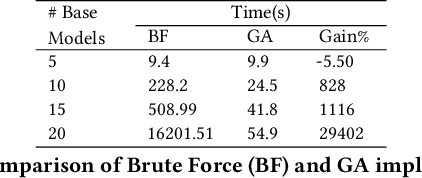
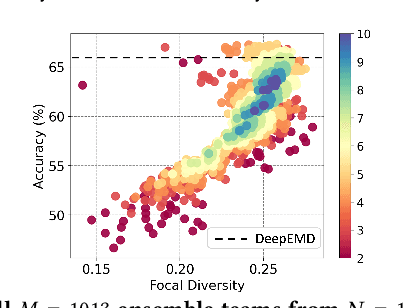
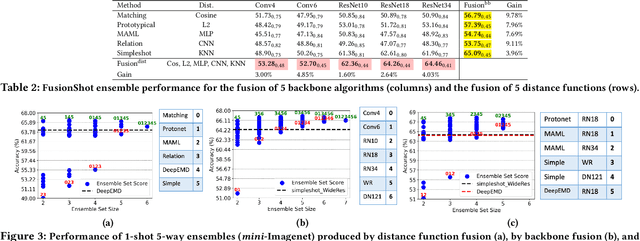
This paper presents FusionShot, a focal diversity optimized few-shot ensemble learning approach for boosting the robustness and generalization performance of pre-trained few-shot models. The paper makes three original contributions. First, we explore the unique characteristics of few-shot learning to ensemble multiple few-shot (FS) models by creating three alternative fusion channels. Second, we introduce the concept of focal error diversity to learn the most efficient ensemble teaming strategy, rather than assuming that an ensemble of a larger number of base models will outperform those sub-ensembles of smaller size. We develop a focal-diversity ensemble pruning method to effectively prune out the candidate ensembles with low ensemble error diversity and recommend top-$K$ FS ensembles with the highest focal error diversity. Finally, we capture the complex non-linear patterns of ensemble few-shot predictions by designing the learn-to-combine algorithm, which can learn the diverse weight assignments for robust ensemble fusion over different member models. Extensive experiments on representative few-shot benchmarks show that the top-K ensembles recommended by FusionShot can outperform the representative SOTA few-shot models on novel tasks (different distributions and unknown at training), and can prevail over existing few-shot learners in both cross-domain settings and adversarial settings. For reproducibility purposes, FusionShot trained models, results, and code are made available at https://github.com/sftekin/fusionshot