 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025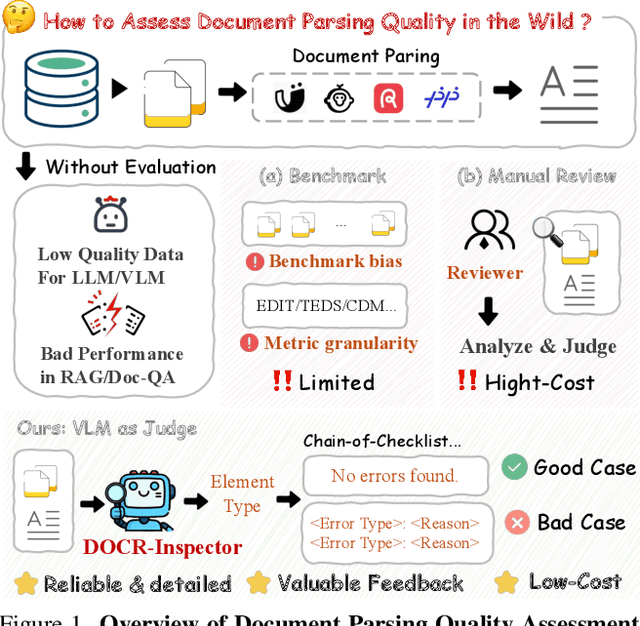
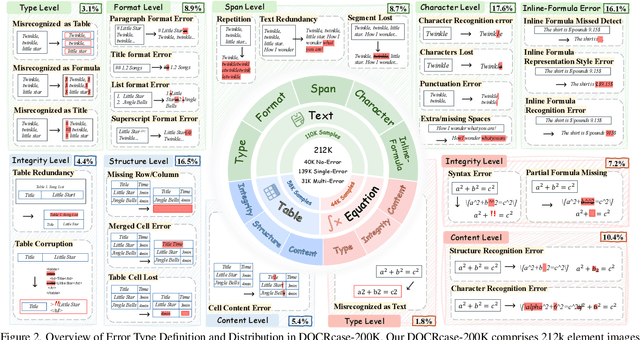

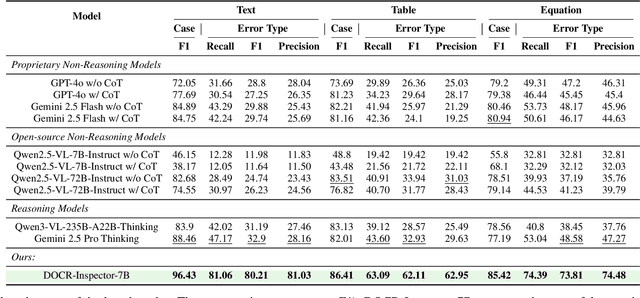
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
A Survey on the Safety and Security Threats of Computer-Using Agents: JARVIS or Ultron?
May 16, 2025Recently, AI-driven interactions with computing devices have advanced from basic prototype tools to sophisticated, LLM-based systems that emulate human-like operations in graphical user interfaces. We are now witnessing the emergence of \emph{Computer-Using Agents} (CUAs), capable of autonomously performing tasks such as navigating desktop applications, web pages, and mobile apps. However, as these agents grow in capability, they also introduce novel safety and security risks. Vulnerabilities in LLM-driven reasoning, with the added complexity of integrating multiple software components and multimodal inputs, further complicate the security landscape. In this paper, we present a systematization of knowledge on the safety and security threats of CUAs. We conduct a comprehensive literature review and distill our findings along four research objectives: \textit{\textbf{(i)}} define the CUA that suits safety analysis; \textit{\textbf{(ii)} } categorize current safety threats among CUAs; \textit{\textbf{(iii)}} propose a comprehensive taxonomy of existing defensive strategies; \textit{\textbf{(iv)}} summarize prevailing benchmarks, datasets, and evaluation metrics used to assess the safety and performance of CUAs. Building on these insights, our work provides future researchers with a structured foundation for exploring unexplored vulnerabilities and offers practitioners actionable guidance in designing and deploying secure Computer-Using Agents.
Stop Looking for Important Tokens in Multimodal Language Models: Duplication Matters More
Feb 17, 2025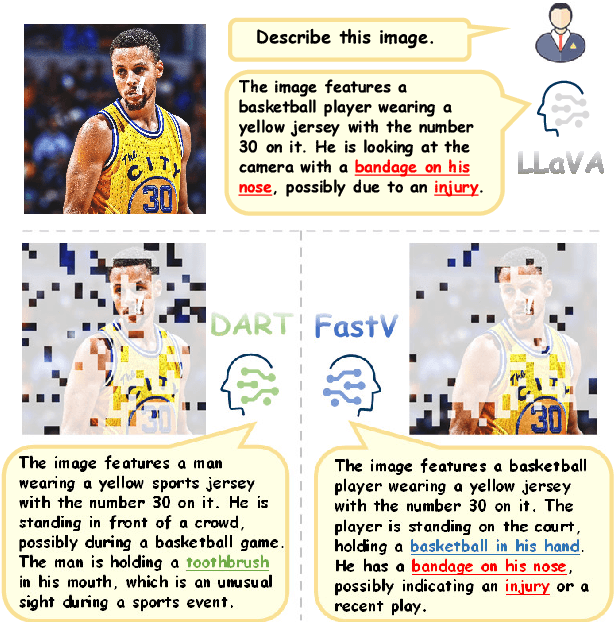
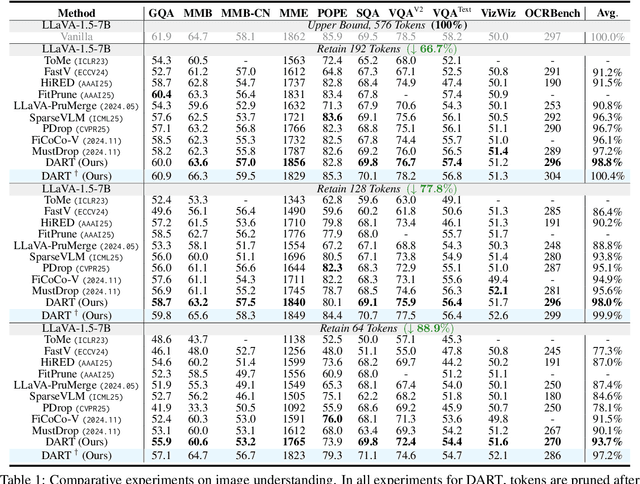
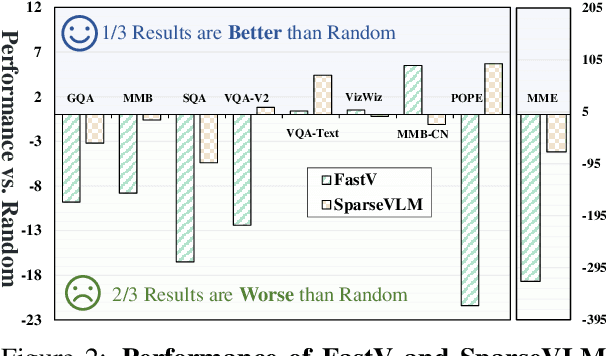
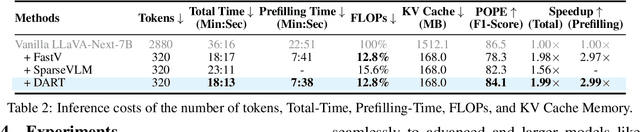
Vision tokens in multimodal large language models often dominate huge computational overhead due to their excessive length compared to linguistic modality. Abundant recent methods aim to solve this problem with token pruning, which first defines an importance criterion for tokens and then prunes the unimportant vision tokens during inference. However, in this paper, we show that the importance is not an ideal indicator to decide whether a token should be pruned. Surprisingly, it usually results in inferior performance than random token pruning and leading to incompatibility to efficient attention computation operators.Instead, we propose DART (Duplication-Aware Reduction of Tokens), which prunes tokens based on its duplication with other tokens, leading to significant and training-free acceleration. Concretely, DART selects a small subset of pivot tokens and then retains the tokens with low duplication to the pivots, ensuring minimal information loss during token pruning. Experiments demonstrate that DART can prune 88.9% vision tokens while maintaining comparable performance, leading to a 1.99$\times$ and 2.99$\times$ speed-up in total time and prefilling stage, respectively, with good compatibility to efficient attention operators. Our codes are available at https://github.com/ZichenWen1/DART.
One-shot Federated Learning via Synthetic Distiller-Distillate Communication
Dec 06, 2024

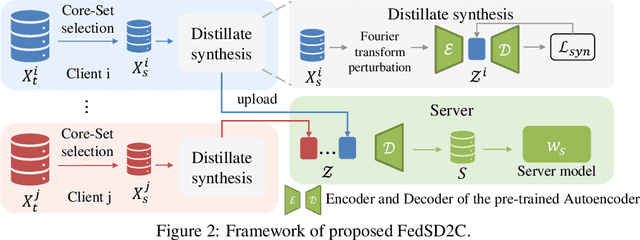

One-shot Federated learning (FL) is a powerful technology facilitating collaborative training of machine learning models in a single round of communication. While its superiority lies in communication efficiency and privacy preservation compared to iterative FL, one-shot FL often compromises model performance. Prior research has primarily focused on employing data-free knowledge distillation to optimize data generators and ensemble models for better aggregating local knowledge into the server model. However, these methods typically struggle with data heterogeneity, where inconsistent local data distributions can cause teachers to provide misleading knowledge. Additionally, they may encounter scalability issues with complex datasets due to inherent two-step information loss: first, during local training (from data to model), and second, when transferring knowledge to the server model (from model to inversed data). In this paper, we propose FedSD2C, a novel and practical one-shot FL framework designed to address these challenges. FedSD2C introduces a distiller to synthesize informative distillates directly from local data to reduce information loss and proposes sharing synthetic distillates instead of inconsistent local models to tackle data heterogeneity. Our empirical results demonstrate that FedSD2C consistently outperforms other one-shot FL methods with more complex and real datasets, achieving up to 2.6 the performance of the best baseline. Code: https://github.com/Carkham/FedSD2C
OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation
Dec 03, 2024Retrieval-augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external knowledge to reduce hallucinations and incorporate up-to-date information without retraining. As an essential part of RAG, external knowledge bases are commonly built by extracting structured data from unstructured PDF documents using Optical Character Recognition (OCR). However, given the imperfect prediction of OCR and the inherent non-uniform representation of structured data, knowledge bases inevitably contain various OCR noises. In this paper, we introduce OHRBench, the first benchmark for understanding the cascading impact of OCR on RAG systems. OHRBench includes 350 carefully selected unstructured PDF documents from six real-world RAG application domains, along with Q&As derived from multimodal elements in documents, challenging existing OCR solutions used for RAG To better understand OCR's impact on RAG systems, we identify two primary types of OCR noise: Semantic Noise and Formatting Noise and apply perturbation to generate a set of structured data with varying degrees of each OCR noise. Using OHRBench, we first conduct a comprehensive evaluation of current OCR solutions and reveal that none is competent for constructing high-quality knowledge bases for RAG systems. We then systematically evaluate the impact of these two noise types and demonstrate the vulnerability of RAG systems. Furthermore, we discuss the potential of employing Vision-Language Models (VLMs) without OCR in RAG systems. Code: https://github.com/opendatalab/OHR-Bench
Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction
Oct 29, 2024



Document parsing is essential for converting unstructured and semi-structured documents-such as contracts, academic papers, and invoices-into structured, machine-readable data. Document parsing extract reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation. This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models. Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail. Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It emphasizes the importance of developing larger and more diverse datasets and outlines future research directions.