 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespecting Self-Uncertainty in On-Policy Self-Distillation for Efficient LLM Reasoning
May 13, 2026On-policy self-distillation trains a reasoning model on its own rollouts while a teacher, often the same model conditioned on privileged context, provides dense token-level supervision. Existing objectives typically weight the teacher's token-level signal uniformly across a chain-of-thought sequence, despite substantial variation in the entropy of the teacher's predictive distribution. We propose EGRSD (Entropy-Guided Reinforced Self-Distillation), which unifies token-level updates through three signals: a reward-grounded direction, a teacher-student likelihood-ratio magnitude, and the proposed teacher-entropy confidence gate that down-weights high-entropy token positions while maintaining a nonzero lower bound on every token weight. We further introduce CL-EGRSD, a causal-lookahead variant that distinguishes sustained high-entropy spans from transient high-entropy positions whose following context rapidly becomes low entropy. Experiments with Qwen3-4B and Qwen3-8B in thinking mode show that EGRSD and CL-EGRSD advance the accuracy-length frontier among the compared trainable methods.
EvoStreaming: Your Offline Video Model Is a Natively Streaming Assistant
May 11, 2026Streaming video understanding demands more than watching longer videos: assistants must decide when to speak in real time, balancing responsiveness against verbosity. Yet most video-language models (VideoLLMs) are trained for offline inference, and existing streaming benchmarks externalize this timing decision to the evaluator. We address this gap with RealStreamEval, a frame-level multi-turn evaluation protocol that exposes models to sequential observations and penalizes unnecessary responses. Under this protocol, we observed that strong offline VideoLLMs retain useful visual understanding but lack an interaction policy for deciding when to respond. Motivated by this observation, we propose EvoStreaming, a self-evolved streaming adaptation framework in which the base model itself acts as data generator, relevance annotator, and roll-out policy to synthesize streaming trajectories without external supervision. With only $1{,}000$ self-generated samples ($139\times$ less than the leading streaming instruction-tuning approach) and no architectural changes, EvoStreaming consistently improves the overall RealStreamEval score by up to $10.8$ points across five open VideoLLM backbones (Qwen2/2.5/3-VL, InternVL-3.5, MiniCPM-V4.5) while largely preserving offline video performance. These results suggest that data-efficient interaction tuning is a practical path for adapting existing VideoLLMs to streaming assistants.
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
Apr 10, 2026Vision agent memory has shown remarkable effectiveness in streaming video understanding. However, storing such memory for videos incurs substantial memory overhead, leading to high costs in both storage and computation. To address this issue, we propose StreamMeCo, an efficient Stream Agent Memory Compression framework. Specifically, based on the connectivity of the memory graph, StreamMeCo introduces edge-free minmax sampling for the isolated nodes and an edge-aware weight pruning for connected nodes, evicting the redundant memory nodes while maintaining the accuracy. In addition, we introduce a time-decay memory retrieval mechanism to further eliminate the performance degradation caused by memory compression. Extensive experiments on three challenging benchmark datasets (M3-Bench-robot, M3-Bench-web and Video-MME-Long) demonstrate that under 70% memory graph compression, StreamMeCo achieves a 1.87* speedup in memory retrieval while delivering an average accuracy improvement of 1.0%. Our code is available at https://github.com/Celina-love-sweet/StreamMeCo.
Flash-Unified: A Training-Free and Task-Aware Acceleration Framework for Native Unified Models
Mar 16, 2026Native unified multimodal models, which integrate both generative and understanding capabilities, face substantial computational overhead that hinders their real-world deployment. Existing acceleration techniques typically employ a static, monolithic strategy, ignoring the fundamental divergence in computational profiles between iterative generation tasks (e.g., image generation) and single-pass understanding tasks (e.g., VQA). In this work, we present the first systematic analysis of unified models, revealing pronounced parameter specialization, where distinct neuron sets are critical for each task. This implies that, at the parameter level, unified models have implicitly internalized separate inference pathways for generation and understanding within a single architecture. Based on these insights, we introduce a training-free and task-aware acceleration framework, FlashU, that tailors optimization to each task's demands. Across both tasks, we introduce Task-Specific Network Pruning and Dynamic Layer Skipping, aiming to eliminate inter-layer and task-specific redundancy. For visual generation, we implement a time-varying control signal for the guidance scale and a temporal approximation for the diffusion head via Diffusion Head Cache. For multimodal understanding, building upon the pruned model, we introduce Dynamic Token Pruning via a V-Norm Proxy to exploit the spatial redundancy of visual inputs. Extensive experiments on Show-o2 demonstrate that FlashU achieves 1.78$\times$ to 2.01$\times$ inference acceleration across both understanding and generation tasks while maintaining SOTA performance, outperforming competing unified models and validating our task-aware acceleration paradigm. Our code is publicly available at https://github.com/Rirayh/FlashU.
Panoramic Affordance Prediction
Mar 16, 2026Affordance prediction serves as a critical bridge between perception and action in embodied AI. However, existing research is confined to pinhole camera models, which suffer from narrow Fields of View (FoV) and fragmented observations, often missing critical holistic environmental context. In this paper, we present the first exploration into Panoramic Affordance Prediction, utilizing 360-degree imagery to capture global spatial relationships and holistic scene understanding. To facilitate this novel task, we first introduce PAP-12K, a large-scale benchmark dataset containing over 1,000 ultra-high-resolution (12k, 11904 x 5952) panoramic images with over 12k carefully annotated QA pairs and affordance masks. Furthermore, we propose PAP, a training-free, coarse-to-fine pipeline inspired by the human foveal visual system to tackle the ultra-high resolution and severe distortion inherent in panoramic images. PAP employs recursive visual routing via grid prompting to progressively locate targets, applies an adaptive gaze mechanism to rectify local geometric distortions, and utilizes a cascaded grounding pipeline to extract precise instance-level masks. Experimental results on PAP-12K reveal that existing affordance prediction methods designed for standard perspective images suffer severe performance degradation and fail due to the unique challenges of panoramic vision. In contrast, PAP framework effectively overcomes these obstacles, significantly outperforming state-of-the-art baselines and highlighting the immense potential of panoramic perception for robust embodied intelligence.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
D2Pruner: Debiased Importance and Structural Diversity for MLLM Token Pruning
Dec 22, 2025



Processing long visual token sequences poses a significant computational burden on Multimodal Large Language Models (MLLMs). While token pruning offers a path to acceleration, we find that current methods, while adequate for general understanding, catastrophically fail on fine-grained localization tasks. We attribute this failure to the inherent flaws of the two prevailing strategies: importance-based methods suffer from a strong positional bias, an inherent model artifact that distracts from semantic content, while diversity-based methods exhibit structural blindness, disregarding the user's prompt and spatial redundancy. To address this, we introduce D2Pruner, a framework that rectifies these issues by uniquely combining debiased importance with a structural pruning mechanism. Our method first secures a core set of the most critical tokens as pivots based on a debiased attention score. It then performs a Maximal Independent Set (MIS) selection on the remaining tokens, which are modeled on a hybrid graph where edges signify spatial proximity and semantic similarity. This process iteratively preserves the most important and available token while removing its neighbors, ensuring that the supplementary tokens are chosen to maximize importance and diversity. Extensive experiments demonstrate that D2Pruner has exceptional efficiency and fidelity. Applied to LLaVA-1.5-7B for general understanding tasks, it reduces FLOPs by 74.2\% while retaining 99.2\% of its original performance. Furthermore, in challenging localization benchmarks with InternVL-2.5-8B, it maintains 85.7\% performance at a 90\% token reduction rate, marking a significant advancement with up to 63. 53\% improvement over existing methods.
IPCV: Information-Preserving Compression for MLLM Visual Encoders
Dec 21, 2025



Multimodal Large Language Models (MLLMs) deliver strong vision-language performance but at high computational cost, driven by numerous visual tokens processed by the Vision Transformer (ViT) encoder. Existing token pruning strategies are inadequate: LLM-stage token pruning overlooks the ViT's overhead, while conventional ViT token pruning, without language guidance, risks discarding textually critical visual cues and introduces feature distortions amplified by the ViT's bidirectional attention. To meet these challenges, we propose IPCV, a training-free, information-preserving compression framework for MLLM visual encoders. IPCV enables aggressive token pruning inside the ViT via Neighbor-Guided Reconstruction (NGR) that temporarily reconstructs pruned tokens to participate in attention with minimal overhead, then fully restores them before passing to the LLM. Besides, we introduce Attention Stabilization (AS) to further alleviate the negative influence from token pruning by approximating the K/V of pruned tokens. It can be directly applied to previous LLM-side token pruning methods to enhance their performance. Extensive experiments show that IPCV substantially reduces end-to-end computation and outperforms state-of-the-art training-free token compression methods across diverse image and video benchmarks. Our code is available at https://github.com/Perkzi/IPCV.
DOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025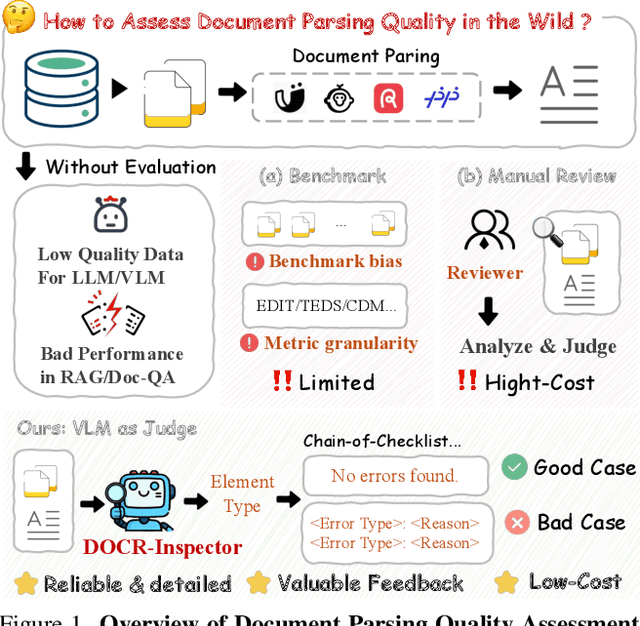
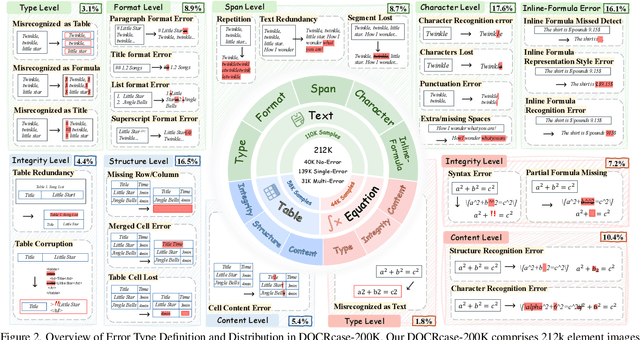

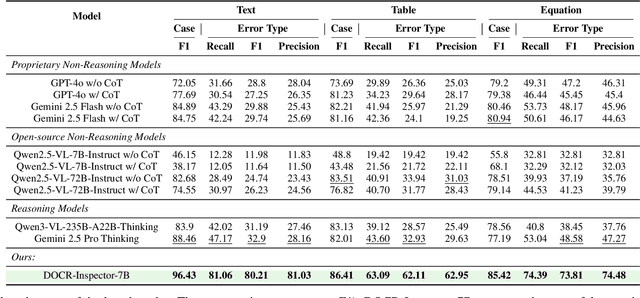
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.