 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Channel Interference Mitigation Using Deep Learning for Drone-Based Large-Scale Antenna Measurements
Jan 19, 2026Unmanned aerial vehicles (UAVs) enable efficient in-situ radiation characterization of large-aperture antennas directly in their deployment environments. In such measurements, a continuous-wave (CW) probe tone is commonly transmitted to characterize the antenna response. However, active co-channel emissions from neighboring antennas often introduce severe in-band interference, where classical FFT-based estimators fail to accurately estimate the CW tone amplitude when the signal-to-interference ratios (SIR) falls below -10 dB. This paper proposes a lightweight deep convolutional neural network (DC-CNN) that estimates the amplitude of the CW tone. The model is trained and evaluated on real 5~GHz measurement bursts spanning an effective SIR range of --33.3 dB to +46.7 dB. Despite its compact size (<20k parameters), the proposed DC-CNN achieves a mean absolute error (MAE) of 7% over the full range, with <1 dB error for SIR >= -30 dB. This robustness and efficiency make DC-CNN suitable for deployment on embedded UAV platforms for interference-resilient antenna pattern characterization.
Forest Before Trees: Latent Superposition for Efficient Visual Reasoning
Jan 11, 2026While Chain-of-Thought empowers Large Vision-Language Models with multi-step reasoning, explicit textual rationales suffer from an information bandwidth bottleneck, where continuous visual details are discarded during discrete tokenization. Recent latent reasoning methods attempt to address this challenge, but often fall prey to premature semantic collapse due to rigid autoregressive objectives. In this paper, we propose Laser, a novel paradigm that reformulates visual deduction via Dynamic Windowed Alignment Learning (DWAL). Instead of forcing a point-wise prediction, Laser aligns the latent state with a dynamic validity window of future semantics. This mechanism enforces a "Forest-before-Trees" cognitive hierarchy, enabling the model to maintain a probabilistic superposition of global features before narrowing down to local details. Crucially, Laser maintains interpretability via decodable trajectories while stabilizing unconstrained learning via Self-Refined Superposition. Extensive experiments on 6 benchmarks demonstrate that Laser achieves state-of-the-art performance among latent reasoning methods, surpassing the strong baseline Monet by 5.03% on average. Notably, it achieves these gains with extreme efficiency, reducing inference tokens by more than 97%, while demonstrating robust generalization to out-of-distribution domains.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
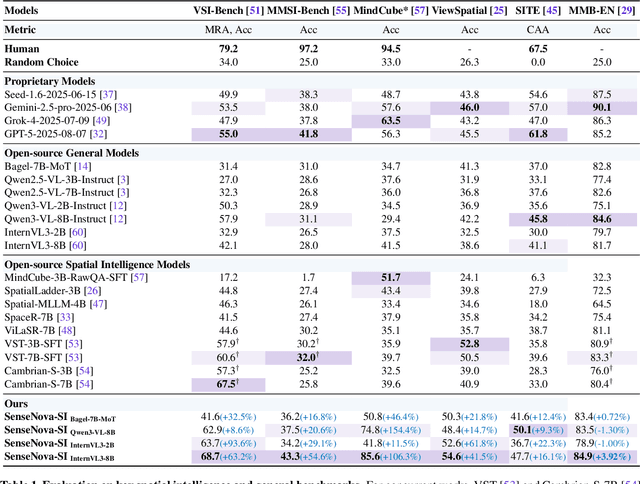


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025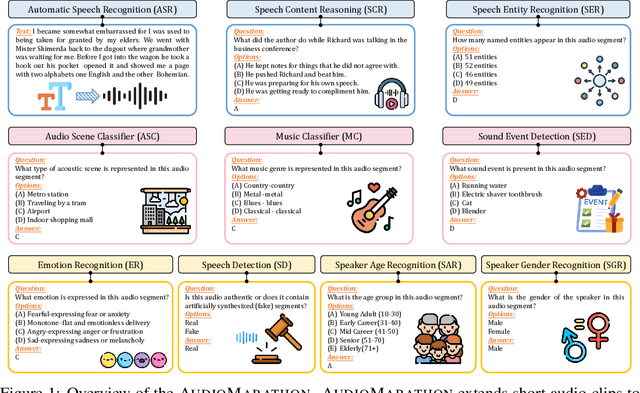
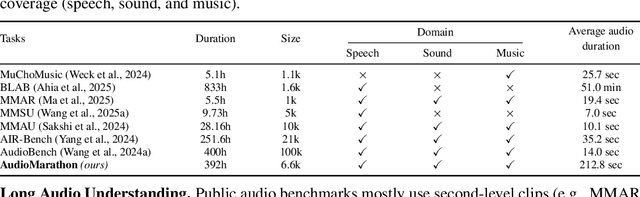

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
CROP: Integrating Topological and Spatial Structures via Cross-View Prefixes for Molecular LLMs
Aug 09, 2025Recent advances in molecular science have been propelled significantly by large language models (LLMs). However, their effectiveness is limited when relying solely on molecular sequences, which fail to capture the complex structures of molecules. Beyond sequence representation, molecules exhibit two complementary structural views: the first focuses on the topological relationships between atoms, as exemplified by the graph view; and the second emphasizes the spatial configuration of molecules, as represented by the image view. The two types of views provide unique insights into molecular structures. To leverage these views collaboratively, we propose the CROss-view Prefixes (CROP) to enhance LLMs' molecular understanding through efficient multi-view integration. CROP possesses two advantages: (i) efficiency: by jointly resampling multiple structural views into fixed-length prefixes, it avoids excessive consumption of the LLM's limited context length and allows easy expansion to more views; (ii) effectiveness: by utilizing the LLM's self-encoded molecular sequences to guide the resampling process, it boosts the quality of the generated prefixes. Specifically, our framework features a carefully designed SMILES Guided Resampler for view resampling, and a Structural Embedding Gate for converting the resulting embeddings into LLM's prefixes. Extensive experiments demonstrate the superiority of CROP in tasks including molecule captioning, IUPAC name prediction and molecule property prediction.
BASIC: Boosting Visual Alignment with Intrinsic Refined Embeddings in Multimodal Large Language Models
Aug 09, 2025Mainstream Multimodal Large Language Models (MLLMs) achieve visual understanding by using a vision projector to bridge well-pretrained vision encoders and large language models (LLMs). The inherent gap between visual and textual modalities makes the embeddings from the vision projector critical for visual comprehension. However, current alignment approaches treat visual embeddings as contextual cues and merely apply auto-regressive supervision to textual outputs, neglecting the necessity of introducing equivalent direct visual supervision, which hinders the potential finer alignment of visual embeddings. In this paper, based on our analysis of the refinement process of visual embeddings in the LLM's shallow layers, we propose BASIC, a method that utilizes refined visual embeddings within the LLM as supervision to directly guide the projector in generating initial visual embeddings. Specifically, the guidance is conducted from two perspectives: (i) optimizing embedding directions by reducing angles between initial and supervisory embeddings in semantic space; (ii) improving semantic matching by minimizing disparities between the logit distributions of both visual embeddings. Without additional supervisory models or artificial annotations, BASIC significantly improves the performance of MLLMs across a wide range of benchmarks, demonstrating the effectiveness of our introduced direct visual supervision.
C-TLSAN: Content-Enhanced Time-Aware Long- and Short-Term Attention Network for Personalized Recommendation
Jun 16, 2025Sequential recommender systems aim to model users' evolving preferences by capturing patterns in their historical interactions. Recent advances in this area have leveraged deep neural networks and attention mechanisms to effectively represent sequential behaviors and time-sensitive interests. In this work, we propose C-TLSAN (Content-Enhanced Time-Aware Long- and Short-Term Attention Network), an extension of the TLSAN architecture that jointly models long- and short-term user preferences while incorporating semantic content associated with items, such as product descriptions. C-TLSAN enriches the recommendation pipeline by embedding textual content linked to users' historical interactions directly into both long-term and short-term attention layers. This allows the model to learn from both behavioral patterns and rich item content, enhancing user and item representations across temporal dimensions. By fusing sequential signals with textual semantics, our approach improves the expressiveness and personalization capacity of recommendation systems. We conduct extensive experiments on large-scale Amazon datasets, benchmarking C-TLSAN against state-of-the-art baselines, including recent sequential recommenders based on Large Language Models (LLMs), which represent interaction history and predictions in text form. Empirical results demonstrate that C-TLSAN consistently outperforms strong baselines in next-item prediction tasks. Notably, it improves AUC by 1.66%, Recall@10 by 93.99%, and Precision@10 by 94.80% on average over the best-performing baseline (TLSAN) across 10 Amazon product categories. These results highlight the value of integrating content-aware enhancements into temporal modeling frameworks for sequential recommendation. Our code is available at https://github.com/booml247/cTLSAN.
Optimizing Recall or Relevance? A Multi-Task Multi-Head Approach for Item-to-Item Retrieval in Recommendation
Jun 06, 2025The task of item-to-item (I2I) retrieval is to identify a set of relevant and highly engaging items based on a given trigger item. It is a crucial component in modern recommendation systems, where users' previously engaged items serve as trigger items to retrieve relevant content for future engagement. However, existing I2I retrieval models in industry are primarily built on co-engagement data and optimized using the recall measure, which overly emphasizes co-engagement patterns while failing to capture semantic relevance. This often leads to overfitting short-term co-engagement trends at the expense of long-term benefits such as discovering novel interests and promoting content diversity. To address this challenge, we propose MTMH, a Multi-Task and Multi-Head I2I retrieval model that achieves both high recall and semantic relevance. Our model consists of two key components: 1) a multi-task learning loss for formally optimizing the trade-off between recall and semantic relevance, and 2) a multi-head I2I retrieval architecture for retrieving both highly co-engaged and semantically relevant items. We evaluate MTMH using proprietary data from a commercial platform serving billions of users and demonstrate that it can improve recall by up to 14.4% and semantic relevance by up to 56.6% compared with prior state-of-the-art models. We also conduct live experiments to verify that MTMH can enhance both short-term consumption metrics and long-term user-experience-related metrics. Our work provides a principled approach for jointly optimizing I2I recall and semantic relevance, which has significant implications for improving the overall performance of recommendation systems.
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
May 25, 2025The rapid advancement of large language models (LLMs) and multi-modal LLMs (MLLMs) has historically relied on model-centric scaling through increasing parameter counts from millions to hundreds of billions to drive performance gains. However, as we approach hardware limits on model size, the dominant computational bottleneck has fundamentally shifted to the quadratic cost of self-attention over long token sequences, now driven by ultra-long text contexts, high-resolution images, and extended videos. In this position paper, \textbf{we argue that the focus of research for efficient AI is shifting from model-centric compression to data-centric compression}. We position token compression as the new frontier, which improves AI efficiency via reducing the number of tokens during model training or inference. Through comprehensive analysis, we first examine recent developments in long-context AI across various domains and establish a unified mathematical framework for existing model efficiency strategies, demonstrating why token compression represents a crucial paradigm shift in addressing long-context overhead. Subsequently, we systematically review the research landscape of token compression, analyzing its fundamental benefits and identifying its compelling advantages across diverse scenarios. Furthermore, we provide an in-depth analysis of current challenges in token compression research and outline promising future directions. Ultimately, our work aims to offer a fresh perspective on AI efficiency, synthesize existing research, and catalyze innovative developments to address the challenges that increasing context lengths pose to the AI community's advancement.