 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Localization of UAV Swarms in GNSS-Denied Conditions
Sep 04, 2025Relative localization of unmanned aerial vehicle (UAV) swarms in global navigation satellite system (GNSS) denied environments is essential for emergency rescue and battlefield reconnaissance. Existing methods suffer from significant localization errors among UAVs due to packet loss and high computational complexity in large swarms. This paper proposes a clustering-based framework where the UAVs simultaneously use communication signals for channel estimation and ranging. Firstly, the spectral clustering is utilized to divide the UAV swarm into different sub-clusters, where matrix completion and multidimensional scaling yield high-precision relative coordinates. Subsequently, a global map is created by the inter-cluster anchor fusion. A case study of UAV integrated communication and sensing (ISAC) system is presented, where the Orthogonal Time Frequency Space (OTFS) is adopted for ranging and communication. Experimental results show that the proposed method reduces localization errors in large swarms and loss of range information. It also explores the impact of signal parameters on communication and localization, highlighting the interplay between communication and localization performance.
Multimodal Large Language Models-Enabled UAV Swarm: Towards Efficient and Intelligent Autonomous Aerial Systems
Jun 15, 2025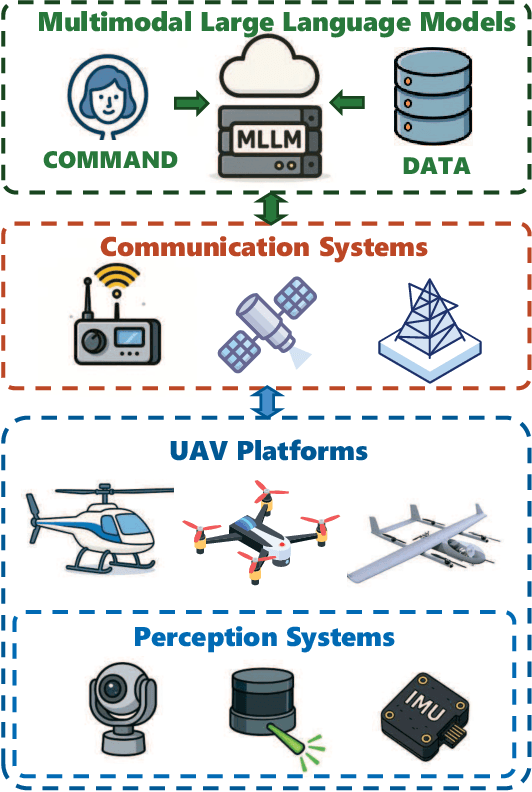
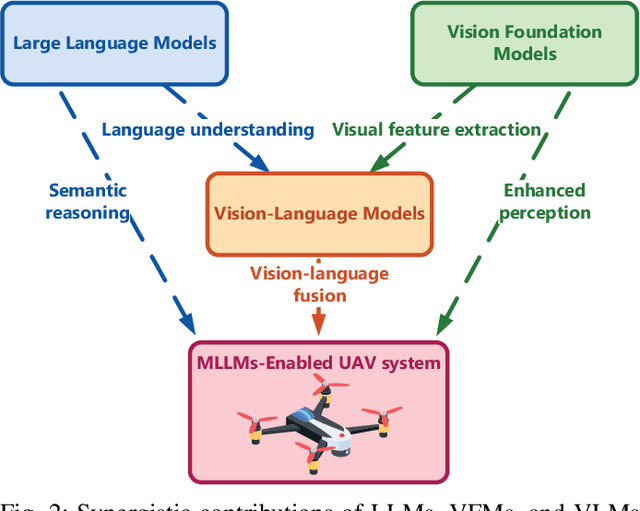
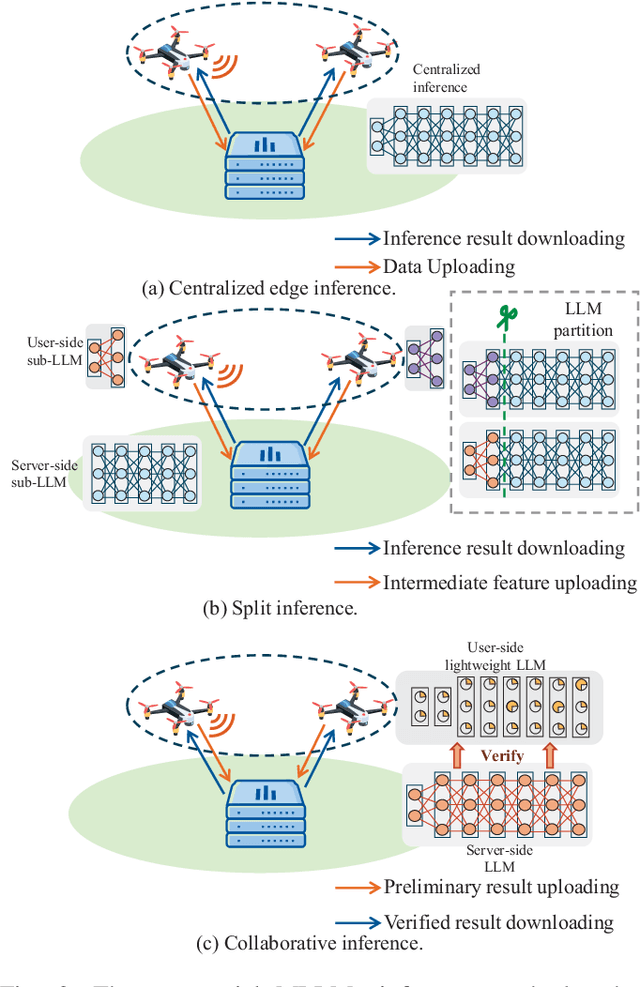
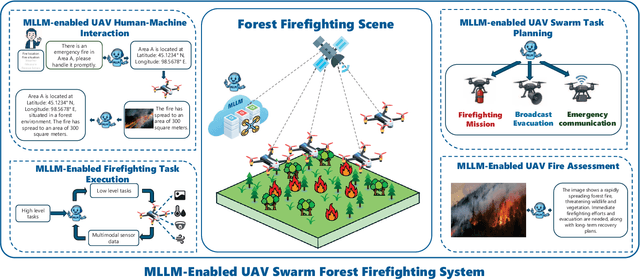
Recent breakthroughs in multimodal large language models (MLLMs) have endowed AI systems with unified perception, reasoning and natural-language interaction across text, image and video streams. Meanwhile, Unmanned Aerial Vehicle (UAV) swarms are increasingly deployed in dynamic, safety-critical missions that demand rapid situational understanding and autonomous adaptation. This paper explores potential solutions for integrating MLLMs with UAV swarms to enhance the intelligence and adaptability across diverse tasks. Specifically, we first outline the fundamental architectures and functions of UAVs and MLLMs. Then, we analyze how MLLMs can enhance the UAV system performance in terms of target detection, autonomous navigation, and multi-agent coordination, while exploring solutions for integrating MLLMs into UAV systems. Next, we propose a practical case study focused on the forest fire fighting. To fully reveal the capabilities of the proposed framework, human-machine interaction, swarm task planning, fire assessment, and task execution are investigated. Finally, we discuss the challenges and future research directions for the MLLMs-enabled UAV swarm. An experiment illustration video could be found online at https://youtu.be/zwnB9ZSa5A4.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
A Tightly Coupled Bi-Level Coordination Framework for CAVs at Road Intersections
Feb 07, 2023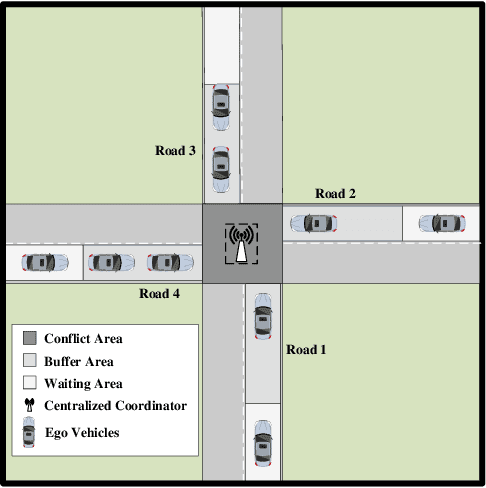
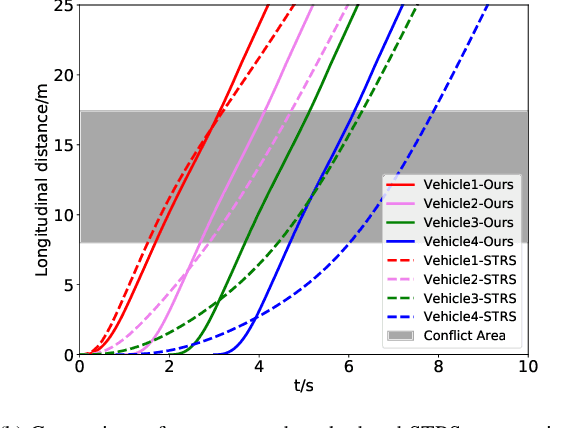
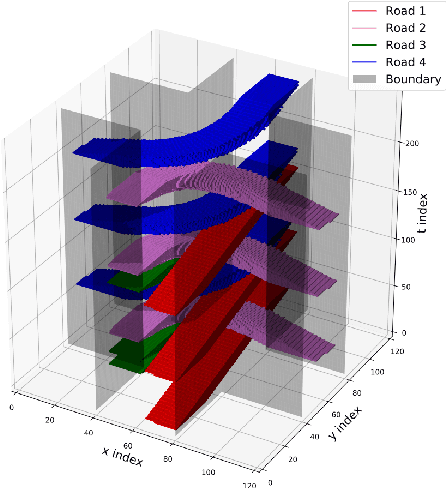
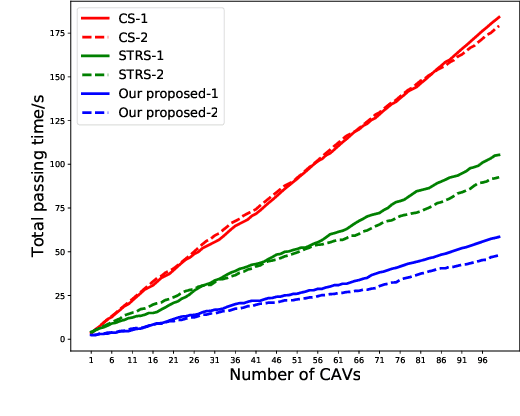
Since the traffic administration at road intersections determines the capacity bottleneck of modern transportation systems, intelligent cooperative coordination for connected autonomous vehicles (CAVs) has shown to be an effective solution. In this paper, we try to formulate a Bi-Level CAV intersection coordination framework, where coordinators from High and Low levels are tightly coupled. In the High-Level coordinator where vehicles from multiple roads are involved, we take various metrics including throughput, safety, fairness and comfort into consideration. Motivated by the time consuming space-time resource allocation framework in [1], we try to give a low complexity solution by transforming the complicated original problem into a sequential linear programming one. Based on the "feasible tunnels" (FT) generated from the High-Level coordinator, we then propose a rapid gradient-based trajectory optimization strategy in the Low-Level planner, to effectively avoid collisions beyond High-level considerations, such as the pedestrian or bicycles. Simulation results and laboratory experiments show that our proposed method outperforms existing strategies. Moreover, the most impressive advantage is that the proposed strategy can plan vehicle trajectory in milliseconds, which is promising in realworld deployments. A detailed description include the coordination framework and experiment demo could be found at the supplement materials, or online at https://youtu.be/MuhjhKfNIOg.