 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMEB-V3: Measuring the Performance Gaps of Omni-Modality Embedding Models
Apr 25, 2026Multimodal embedding models aim to map heterogeneous inputs, such as text, images, videos, and audio, into a shared semantic space. However, existing methods and benchmarks remain largely limited to partial modality coverage, making it difficult to systematically evaluate full-modality representation learning. In this work, we take a step toward the full-modality setting. We introduce MMEB-V3, a comprehensive benchmark that evaluates embeddings across text, image, video, audio, as well as agent-centric scenarios. To enable more fine-grained diagnosis, we further construct OmniSET (Omni-modality Semantic Equivalence Tuples), where semantically equivalent instances are represented across modalities, allowing us to disentangle semantic similarity from modality effects. Through experiments on MMEB-V3, we conduct a systematic analysis of full-modality embeddings and identify three key findings: (1) models often fail to retrieve the intended target modality; (2) cross-modal retrieval is highly asymmetric and dominated by query-modality bias; and (3) instruction-induced shifts are either insufficient or misaligned with the target modality, and therefore do not reliably improve retrieval. These results indicate that current multimodal embeddings are not yet capable of reliably enforcing modality constraints specified by instructions, and consequently fail to exhibit consistent modality-aware retrieval behavior. We hope MMEB-V3 provides a useful benchmark for understanding and diagnosing these limitations, and for guiding future research on full-modality embeddings.
OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Mar 17, 2026Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmarking LLM-based CI. To address this gap, we introduce OpenHospital, an interactive arena where physician agents can evolve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabilities and provides robust evaluation metrics for benchmarking both medical proficiency and system efficiency. Experiments demonstrate the effectiveness of OpenHospital in both fostering and quantifying CI.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025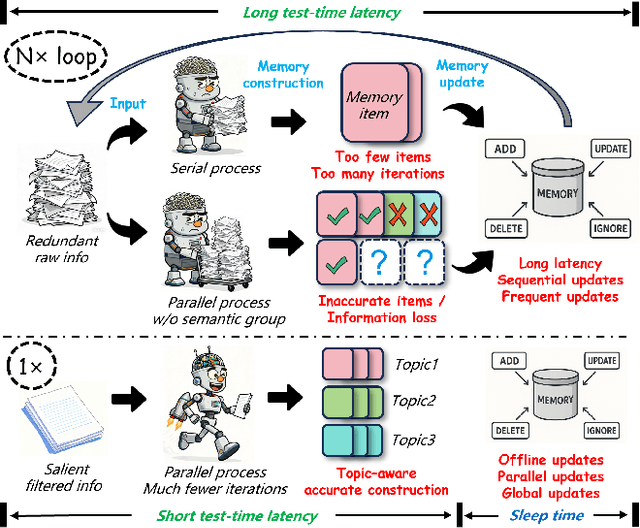
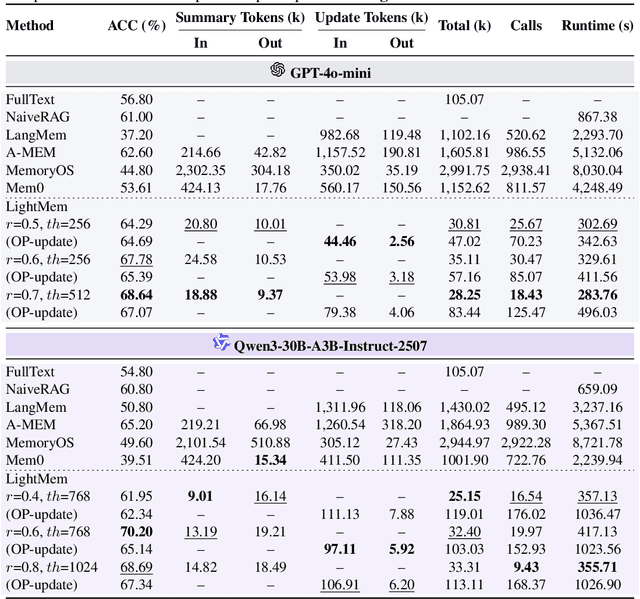
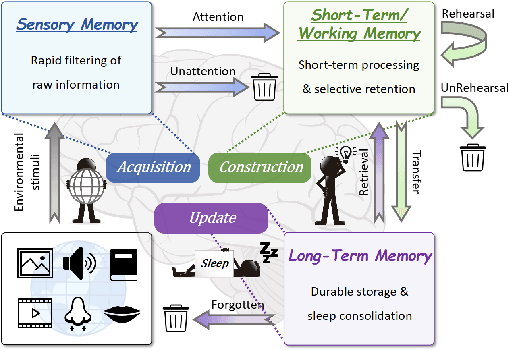
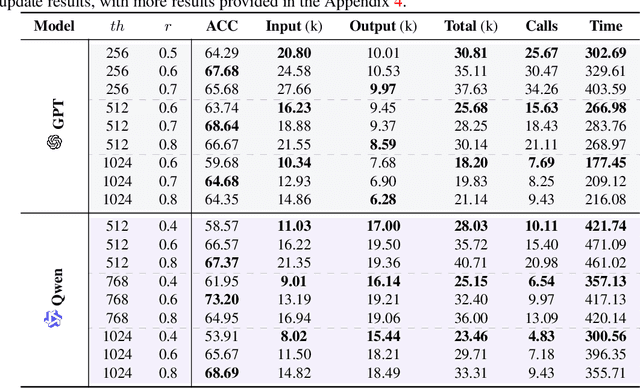
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
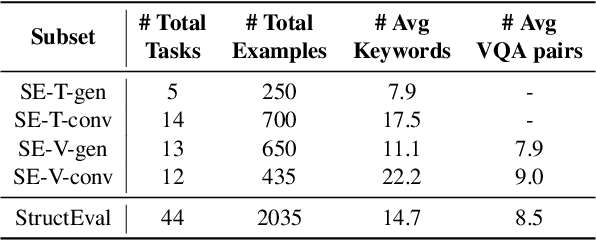
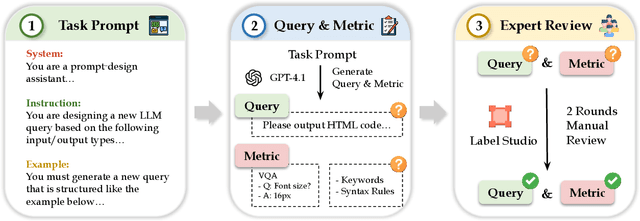

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
ZJUKLAB at SemEval-2025 Task 4: Unlearning via Model Merging
Mar 27, 2025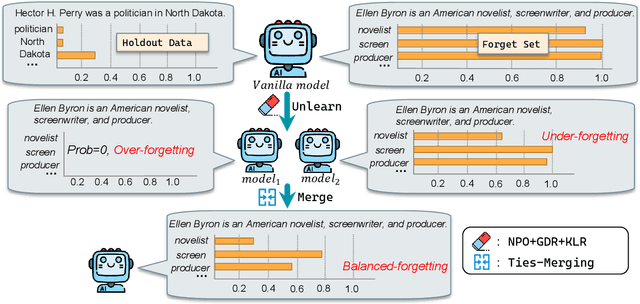
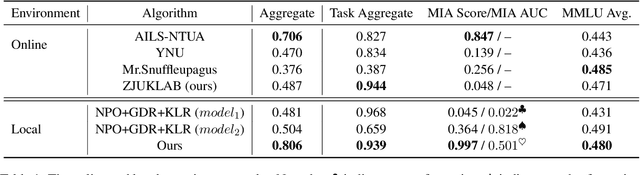
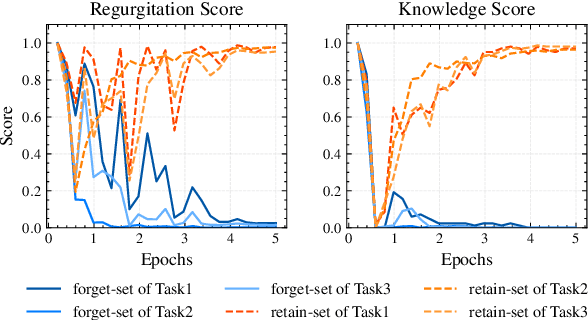
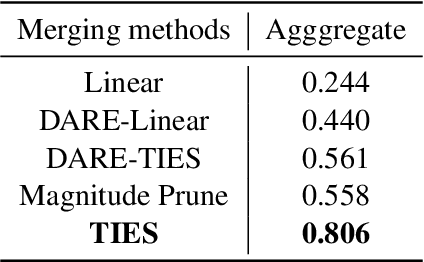
This paper presents the ZJUKLAB team's submission for SemEval-2025 Task 4: Unlearning Sensitive Content from Large Language Models. This task aims to selectively erase sensitive knowledge from large language models, avoiding both over-forgetting and under-forgetting issues. We propose an unlearning system that leverages Model Merging (specifically TIES-Merging), combining two specialized models into a more balanced unlearned model. Our system achieves competitive results, ranking second among 26 teams, with an online score of 0.944 for Task Aggregate and 0.487 for overall Aggregate. In this paper, we also conduct local experiments and perform a comprehensive analysis of the unlearning process, examining performance trajectories, loss dynamics, and weight perspectives, along with several supplementary experiments, to understand the effectiveness of our method. Furthermore, we analyze the shortcomings of our method and evaluation metrics, emphasizing that MIA scores and ROUGE-based metrics alone are insufficient to fully evaluate successful unlearning. Finally, we emphasize the need for more comprehensive evaluation methodologies and rethinking of unlearning objectives in future research. Code is available at https://github.com/zjunlp/unlearn/tree/main/semeval25.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks
Oct 07, 2024



Embedding models have been crucial in enabling various downstream tasks such as semantic similarity, information retrieval, and clustering. Recently, there has been a surge of interest in developing universal text embedding models that can generalize across tasks (e.g., MTEB). However, progress in learning universal multimodal embedding models has been relatively slow despite their importance. In this work, we aim to explore the potential for building universal embeddings capable of handling a wide range of downstream tasks. Our contributions are twofold: (1) MMEB (Massive Multimodal Embedding Benchmark), which covers 4 meta-tasks (i.e. classification, visual question answering, multimodal retrieval, and visual grounding) and 36 datasets, including 20 training and 16 evaluation datasets, and (2) VLM2Vec (Vision-Language Model -> Vector), a contrastive training framework that converts any state-of-the-art vision-language model into an embedding model via training on MMEB. Unlike previous models such as CLIP and BLIP, VLM2Vec can process any combination of images and text to generate a fixed-dimensional vector based on task instructions. We build a series of VLM2Vec models on Phi-3.5-V and evaluate them on MMEB's evaluation split. Our results show that \model achieves an absolute average improvement of 10% to 20% over existing multimodal embedding models on both in-distribution and out-of-distribution datasets in MMEB.
Semi-Supervised Reward Modeling via Iterative Self-Training
Sep 10, 2024Reward models (RM) capture the values and preferences of humans and play a central role in Reinforcement Learning with Human Feedback (RLHF) to align pretrained large language models (LLMs). Traditionally, training these models relies on extensive human-annotated preference data, which poses significant challenges in terms of scalability and cost. To overcome these limitations, we propose Semi-Supervised Reward Modeling (SSRM), an approach that enhances RM training using unlabeled data. Given an unlabeled dataset, SSRM involves three key iterative steps: pseudo-labeling unlabeled examples, selecting high-confidence examples through a confidence threshold, and supervised finetuning on the refined dataset. Across extensive experiments on various model configurations, we demonstrate that SSRM significantly improves reward models without incurring additional labeling costs. Notably, SSRM can achieve performance comparable to models trained entirely on labeled data of equivalent volumes. Overall, SSRM substantially reduces the dependency on large volumes of human-annotated data, thereby decreasing the overall cost and time involved in training effective reward models.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024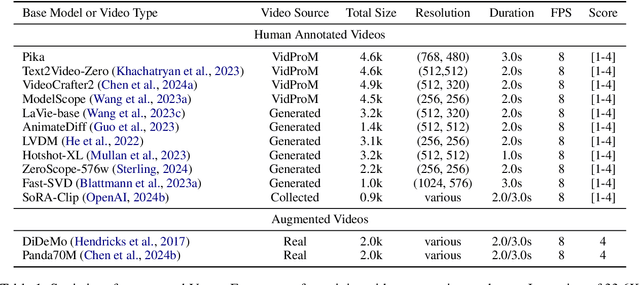

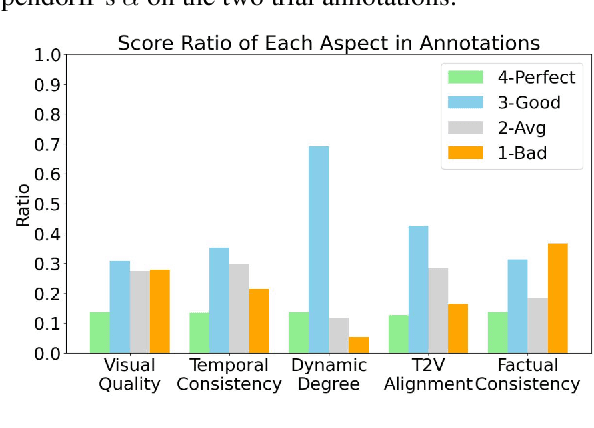

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
Jun 21, 2024In traditional RAG framework, the basic retrieval units are normally short. The common retrievers like DPR normally work with 100-word Wikipedia paragraphs. Such a design forces the retriever to search over a large corpus to find the `needle' unit. In contrast, the readers only need to extract answers from the short retrieved units. Such an imbalanced `heavy' retriever and `light' reader design can lead to sub-optimal performance. In order to alleviate the imbalance, we propose a new framework LongRAG, consisting of a `long retriever' and a `long reader'. LongRAG processes the entire Wikipedia into 4K-token units, which is 30x longer than before. By increasing the unit size, we significantly reduce the total units from 22M to 700K. This significantly lowers the burden of retriever, which leads to a remarkable retrieval score: answer recall@1=71% on NQ (previously 52%) and answer recall@2=72% (previously 47%) on HotpotQA (full-wiki). Then we feed the top-k retrieved units ($\approx$ 30K tokens) to an existing long-context LLM to perform zero-shot answer extraction. Without requiring any training, LongRAG achieves an EM of 62.7% on NQ, which is the best known result. LongRAG also achieves 64.3% on HotpotQA (full-wiki), which is on par of the SoTA model. Our study offers insights into the future roadmap for combining RAG with long-context LLMs.