 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
May 28, 2026Real-world data analysis is inherently iterative, yet existing benchmarks mostly evaluate isolated or short interactive tasks, leaving agents' ability to track evolving analytical context over long horizons untested. We introduce LongDS, a benchmark for long-horizon, multi-turn data analysis where agents must maintain, update, restore, and compose evolving analytical states. LongDS comprises 68 tasks constructed from real-world Kaggle notebooks, spanning 2,225 turns across six domains including Geoscience, Business, and Education. Tasks are designed around state-evolution patterns (e.g., counterfactual perturbation, rollback, multi-state composition), with an average dependency span of 11.3 turns. Evaluating five state-of-the-art models, we find that the best model reaches only 48.45% average accuracy, performance drops nearly 47 points from early to late turns, and long-horizon errors account for 52%--69% of failures. Further analysis shows that additional agent steps do not necessarily improve performance, suggesting that the key bottleneck is maintaining a correct analytical state rather than increasing interaction budget. We release LongDS to support research on reliable long-horizon agentic data analysis. Code and data will be released at https://github.com/zjunlp/DataMind.
When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
May 28, 2026Long-horizon interactions require language models to manage accumulating information: when to update their state, when to preserve their state, and what to ignore. We study this challenge as \textbf{Contextual Belief Management (CBM)}: maintaining a predicted belief state aligned with formal evidence while isolating task-irrelevant noise. To make CBM measurable, we introduce BeliefTrack, a closed-world benchmark spanning Rule Discovery and Circuit Diagnosis, where a finite belief space and symbolic verifiers enable exact turn-level evaluation. BeliefTrack diagnoses three failures: Failed Stay, Failed Update, and Failed Isolation. Across multiple LLMs, vanilla models exhibit severe CBM failures, while explicit belief-tracking prompts provide limited gains. In contrast, reinforcement learning with belief-state rewards reduces failure rates by 70.9\% on average. Further probing reveals latent belief-state dynamics behind these failures, and representation-level steering reduces failure rates by 46.1\% across two tasks\footnote{Code is coming soon at https://github.com/zjunlp/CBM.
Move-Then-Operate: Behavioral Phasing for Human-Like Robotic Manipulation
Apr 26, 2026We present Move-Then-Operate, a Vision language action framework that explicitly decouples robotic manipulation into two distinct behavioral phases: coarse relocation (move) and contact-critical interaction (operate). Unlike monolithic policies that conflate these heterogeneous regimes, our architecture employs a dual-expert policy routed by a learnable phase selector, introducing a structural inductive bias that isolates phase-specific dynamics. Phase labels are automatically generated via an MLLM-based pipeline conditioned on lightweight contextual cues such as end-effector velocity and subtask decomposition to ensure alignment with human motor patterns. Evaluated on the RoboTwin2 benchmark, our method achieves an average success rate of $68.9\%$, outperforming the monolithic $π_0$ baseline by $24\%$. It matches or exceeds models trained on $10\times$ more data and reaches peak performance in $40\%$ fewer training steps, demonstrating that architectural disentanglement of move and operate phases is a highly effective and efficient strategy for mastering high-precision manipulation.
How Controllable Are Large Language Models? A Unified Evaluation across Behavioral Granularities
Mar 03, 2026Large Language Models (LLMs) are increasingly deployed in socially sensitive domains, yet their unpredictable behaviors, ranging from misaligned intent to inconsistent personality, pose significant risks. We introduce SteerEval, a hierarchical benchmark for evaluating LLM controllability across three domains: language features, sentiment, and personality. Each domain is structured into three specification levels: L1 (what to express), L2 (how to express), and L3 (how to instantiate), connecting high-level behavioral intent to concrete textual output. Using SteerEval, we systematically evaluate contemporary steering methods, revealing that control often degrades at finer-grained levels. Our benchmark offers a principled and interpretable framework for safe and controllable LLM behavior, serving as a foundation for future research.
Towards Policy-Adaptive Image Guardrail: Benchmark and Method
Mar 01, 2026Accurate rejection of sensitive or harmful visual content, i.e., harmful image guardrail, is critical in many application scenarios. This task must continuously adapt to the evolving safety policies and content across various domains and over time. However, traditional classifiers, confined to fixed categories, require frequent retraining when new policies are introduced. Vision-language models (VLMs) offer a more adaptable and generalizable foundation for dynamic safety guardrails. Despite this potential, existing VLM-based safeguarding methods are typically trained and evaluated under only a fixed safety policy. We find that these models are heavily overfitted to the seen policy, fail to generalize to unseen policies, and even lose the basic instruction-following ability and general knowledge. To address this issue, in this paper we make two key contributions. First, we benchmark the cross-policy generalization performance of existing VLMs with SafeEditBench, a new evaluation suite. SafeEditBench leverages image-editing models to convert unsafe images into safe counterparts, producing policy-aligned datasets where each safe-unsafe image pair remains visually similar except for localized regions violating specific safety rules. Human annotators then provide accurate safe/unsafe labels under five distinct policies, enabling fine-grained assessment of policy-aware generalization. Second, we introduce SafeGuard-VL, a reinforcement learning-based method with verifiable rewards (RLVR) for robust unsafe-image guardrails. Instead of relying solely on supervised fine-tuning (SFT) under fixed policies, SafeGuard-VL explicitly optimizes the model with policy-grounded rewards, promoting verifiable adaptation across evolving policies. Extensive experiments verify the effectiveness of our method for unsafe image guardrails across various policies.
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Jan 09, 2026As Large Language Models (LLMs) are increasingly deployed in real-world settings, correctness alone is insufficient. Reliable deployment requires maintaining truthful beliefs under contextual perturbations. Existing evaluations largely rely on point-wise confidence like Self-Consistency, which can mask brittle belief. We show that even facts answered with perfect self-consistency can rapidly collapse under mild contextual interference. To address this gap, we propose Neighbor-Consistency Belief (NCB), a structural measure of belief robustness that evaluates response coherence across a conceptual neighborhood. To validate the efficiency of NCB, we introduce a new cognitive stress-testing protocol that probes outputs stability under contextual interference. Experiments across multiple LLMs show that the performance of high-NCB data is relatively more resistant to interference. Finally, we present Structure-Aware Training (SAT), which optimizes context-invariant belief structure and reduces long-tail knowledge brittleness by approximately 30%. Code will be available at https://github.com/zjunlp/belief.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025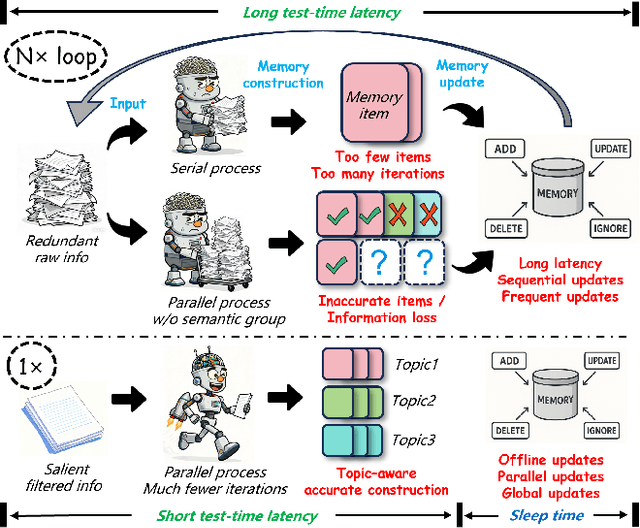
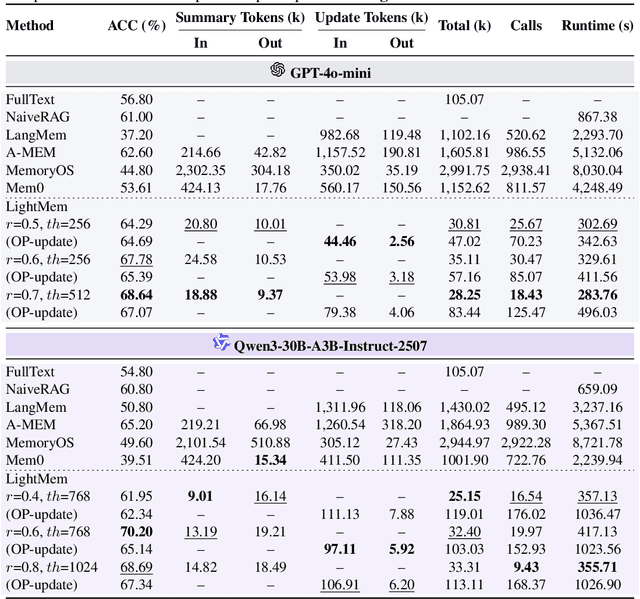
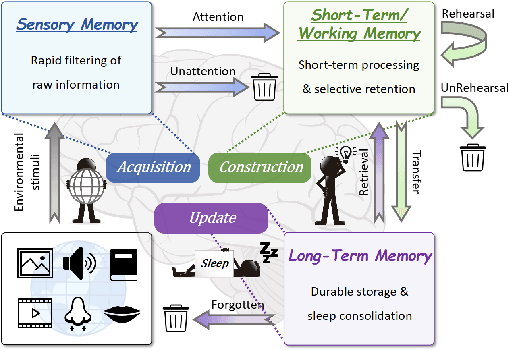
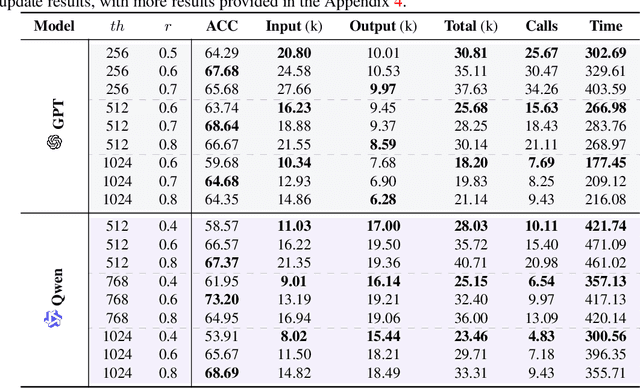
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025



In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
ZJUKLAB at SemEval-2025 Task 4: Unlearning via Model Merging
Mar 27, 2025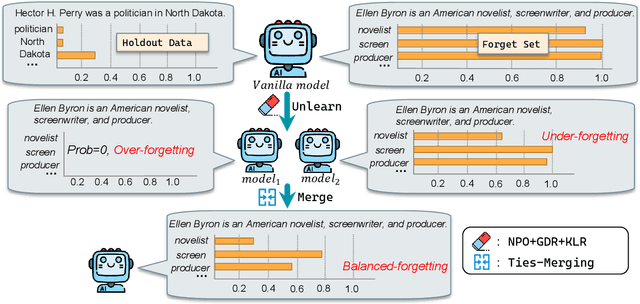
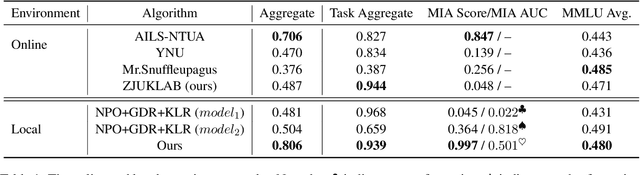
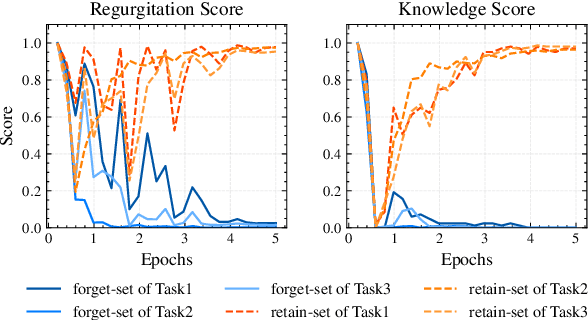
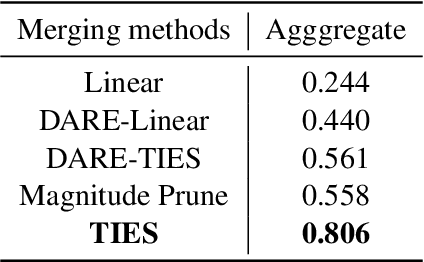
This paper presents the ZJUKLAB team's submission for SemEval-2025 Task 4: Unlearning Sensitive Content from Large Language Models. This task aims to selectively erase sensitive knowledge from large language models, avoiding both over-forgetting and under-forgetting issues. We propose an unlearning system that leverages Model Merging (specifically TIES-Merging), combining two specialized models into a more balanced unlearned model. Our system achieves competitive results, ranking second among 26 teams, with an online score of 0.944 for Task Aggregate and 0.487 for overall Aggregate. In this paper, we also conduct local experiments and perform a comprehensive analysis of the unlearning process, examining performance trajectories, loss dynamics, and weight perspectives, along with several supplementary experiments, to understand the effectiveness of our method. Furthermore, we analyze the shortcomings of our method and evaluation metrics, emphasizing that MIA scores and ROUGE-based metrics alone are insufficient to fully evaluate successful unlearning. Finally, we emphasize the need for more comprehensive evaluation methodologies and rethinking of unlearning objectives in future research. Code is available at https://github.com/zjunlp/unlearn/tree/main/semeval25.
MLLM can see? Dynamic Correction Decoding for Hallucination Mitigation
Oct 15, 2024



Multimodal Large Language Models (MLLMs) frequently exhibit hallucination phenomena, but the underlying reasons remain poorly understood. In this paper, we present an empirical analysis and find that, although MLLMs incorrectly generate the objects in the final output, they are actually able to recognize visual objects in the preceding layers. We speculate that this may be due to the strong knowledge priors of the language model suppressing the visual information, leading to hallucinations. Motivated by this, we propose a novel dynamic correction decoding method for MLLMs (DeCo), which adaptively selects the appropriate preceding layers and proportionally integrates knowledge into the final layer to adjust the output logits. Note that DeCo is model agnostic and can be seamlessly incorporated with various classic decoding strategies and applied to different MLLMs. We evaluate DeCo on widely-used benchmarks, demonstrating that it can reduce hallucination rates by a large margin compared to baselines, highlighting its potential to mitigate hallucinations. Code is available at https://github.com/zjunlp/DeCo.