 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
AS-ES Learning: Towards Efficient CoT Learning in Small Models
Mar 04, 2024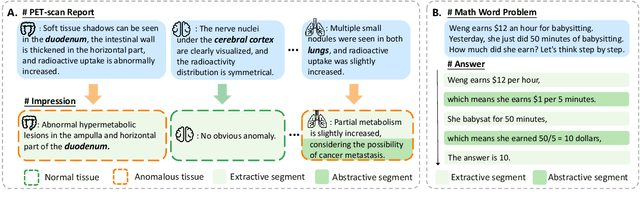
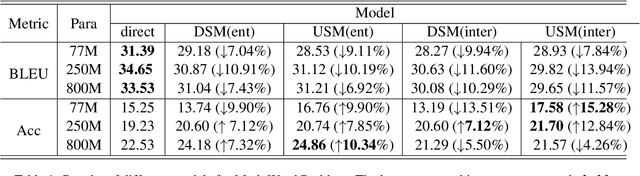
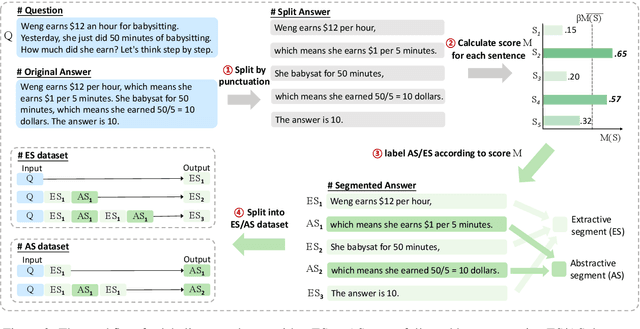

Chain-of-Thought (CoT) serves as a critical emerging ability in LLMs, especially when it comes to logical reasoning. Attempts have been made to induce such ability in small models as well by distilling from the data with CoT generated by Large Language Models (LLMs). However, existing methods often simply generate and incorporate more data from LLMs and fail to note the importance of efficiently utilizing existing CoT data. We here propose a new training paradigm AS-ES (Abstractive Segments - Extractive Segments) learning, which exploits the inherent information in CoT for iterative generation. Experiments show that our methods surpass the direct seq2seq training on CoT-extensive tasks like MWP and PET summarization, without data augmentation or altering the model itself. Furthermore, we explore the reason behind the inefficiency of small models in learning CoT and provide an explanation of why AS-ES learning works, giving insights into the underlying mechanism of CoT.
Beyond Direct Diagnosis: LLM-based Multi-Specialist Agent Consultation for Automatic Diagnosis
Jan 29, 2024Automatic diagnosis is a significant application of AI in healthcare, where diagnoses are generated based on the symptom description of patients. Previous works have approached this task directly by modeling the relationship between the normalized symptoms and all possible diseases. However, in the clinical diagnostic process, patients are initially consulted by a general practitioner and, if necessary, referred to specialists in specific domains for a more comprehensive evaluation. The final diagnosis often emerges from a collaborative consultation among medical specialist groups. Recently, large language models have shown impressive capabilities in natural language understanding. In this study, we adopt tuning-free LLM-based agents as medical practitioners and propose the Agent-derived Multi-Specialist Consultation (AMSC) framework to model the diagnosis process in the real world by adaptively fusing probability distributions of agents over potential diseases. Experimental results demonstrate the superiority of our approach compared with baselines. Notably, our approach requires significantly less parameter updating and training time, enhancing efficiency and practical utility. Furthermore, we delve into a novel perspective on the role of implicit symptoms within the context of automatic diagnosis.
From Artificially Real to Real: Leveraging Pseudo Data from Large Language Models for Low-Resource Molecule Discovery
Sep 11, 2023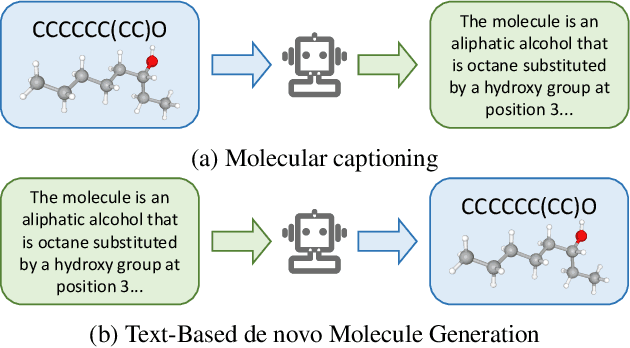
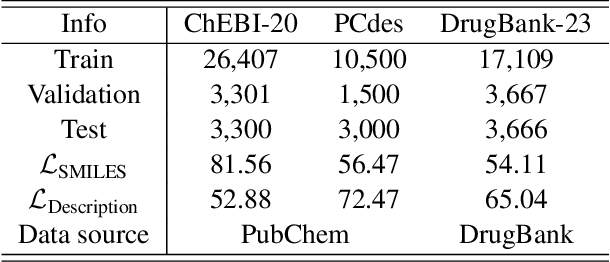
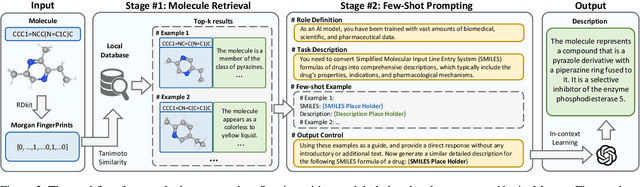
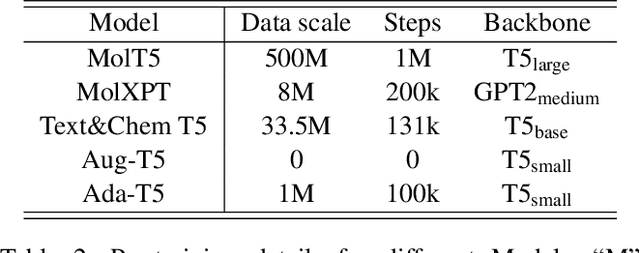
Molecule discovery serves as a cornerstone in numerous scientific domains, fueling the development of new materials and innovative drug designs. Recent developments of in-silico molecule discovery have highlighted the promising results of cross-modal techniques, which bridge molecular structures with their descriptive annotations. However, these cross-modal methods frequently encounter the issue of data scarcity, hampering their performance and application. In this paper, we address the low-resource challenge by utilizing artificially-real data generated by Large Language Models (LLMs). We first introduce a retrieval-based prompting strategy to construct high-quality pseudo data, then explore the optimal method to effectively leverage this pseudo data. Experiments show that using pseudo data for domain adaptation outperforms all existing methods, while also requiring a smaller model scale, reduced data size and lower training cost, highlighting its efficiency. Furthermore, our method shows a sustained improvement as the volume of pseudo data increases, revealing the great potential of pseudo data in advancing low-resource cross-modal molecule discovery.
Manifold-based Verbalizer Space Re-embedding for Tuning-free Prompt-based Classification
Sep 08, 2023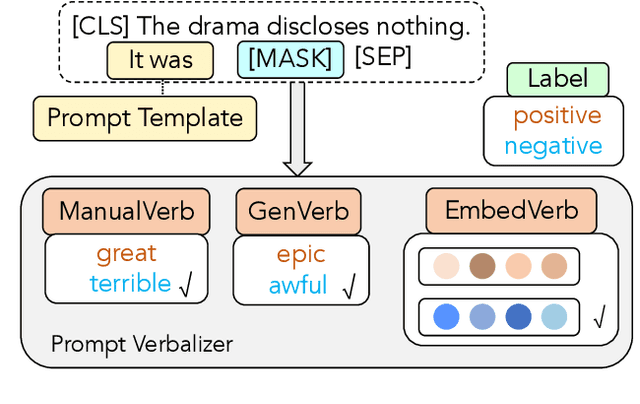
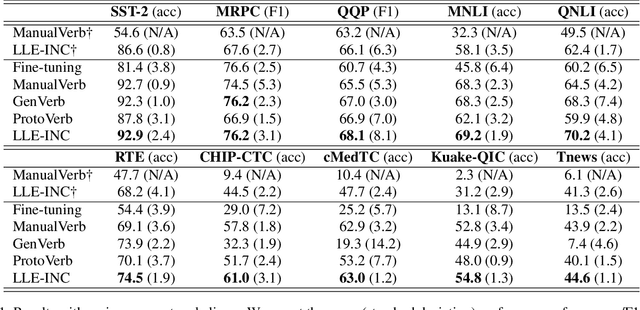
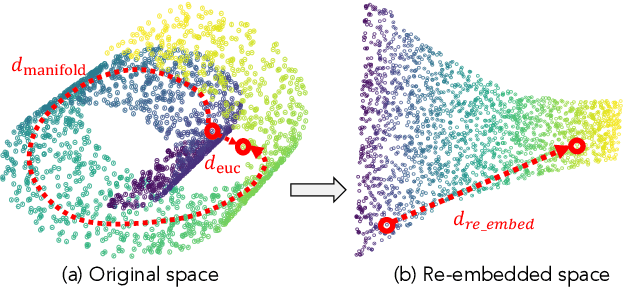
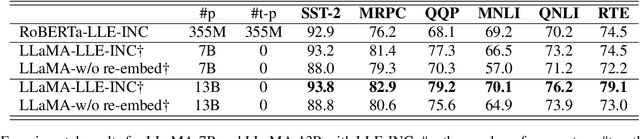
Prompt-based classification adapts tasks to a cloze question format utilizing the [MASK] token and the filled tokens are then mapped to labels through pre-defined verbalizers. Recent studies have explored the use of verbalizer embeddings to reduce labor in this process. However, all existing studies require a tuning process for either the pre-trained models or additional trainable embeddings. Meanwhile, the distance between high-dimensional verbalizer embeddings should not be measured by Euclidean distance due to the potential for non-linear manifolds in the representation space. In this study, we propose a tuning-free manifold-based space re-embedding method called Locally Linear Embedding with Intra-class Neighborhood Constraint (LLE-INC) for verbalizer embeddings, which preserves local properties within the same class as guidance for classification. Experimental results indicate that even without tuning any parameters, our LLE-INC is on par with automated verbalizers with parameter tuning. And with the parameter updating, our approach further enhances prompt-based tuning by up to 3.2%. Furthermore, experiments with the LLaMA-7B&13B indicate that LLE-INC is an efficient tuning-free classification approach for the hyper-scale language models.
Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese
Sep 08, 2023



Large Language Models (LLMs) have demonstrated remarkable success in diverse natural language processing (NLP) tasks in general domains. However, LLMs sometimes generate responses with the hallucination about medical facts due to limited domain knowledge. Such shortcomings pose potential risks in the utilization of LLMs within medical contexts. To address this challenge, we propose knowledge-tuning, which leverages structured medical knowledge bases for the LLMs to grasp domain knowledge efficiently and facilitate reliable response generation. We also release cMedKnowQA, a Chinese medical knowledge question-answering dataset constructed from medical knowledge bases to assess the medical knowledge proficiency of LLMs. Experimental results show that the LLMs which are knowledge-tuned with cMedKnowQA, can exhibit higher levels of accuracy in response generation compared with vanilla instruction-tuning and offer a new reliable way for the domain adaptation of LLMs.
UniCoRN: Unified Cognitive Signal ReconstructioN bridging cognitive signals and human language
Jul 06, 2023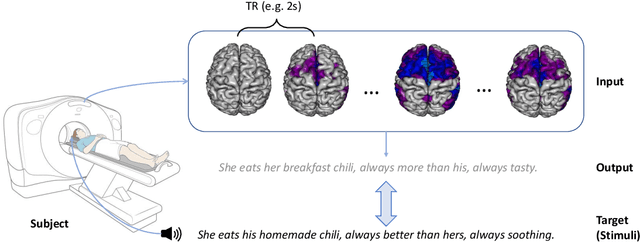

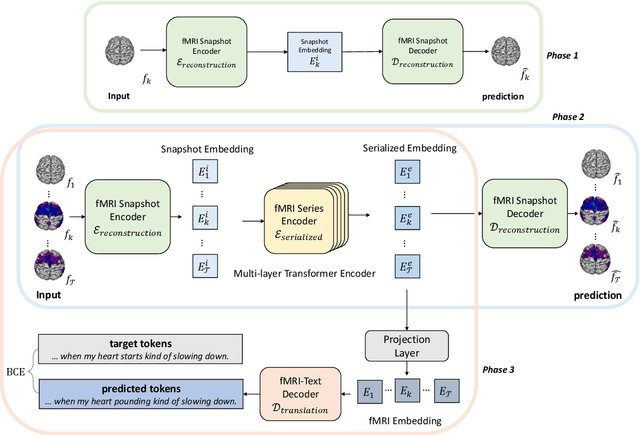
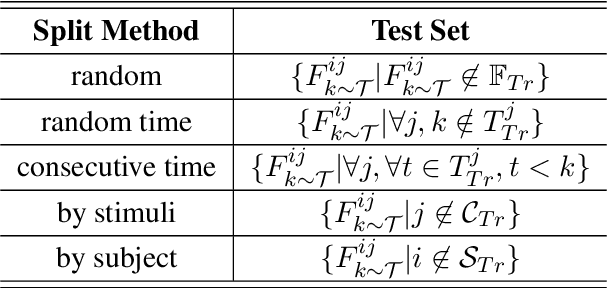
Decoding text stimuli from cognitive signals (e.g. fMRI) enhances our understanding of the human language system, paving the way for building versatile Brain-Computer Interface. However, existing studies largely focus on decoding individual word-level fMRI volumes from a restricted vocabulary, which is far too idealized for real-world application. In this paper, we propose fMRI2text, the first openvocabulary task aiming to bridge fMRI time series and human language. Furthermore, to explore the potential of this new task, we present a baseline solution, UniCoRN: the Unified Cognitive Signal ReconstructioN for Brain Decoding. By reconstructing both individual time points and time series, UniCoRN establishes a robust encoder for cognitive signals (fMRI & EEG). Leveraging a pre-trained language model as decoder, UniCoRN proves its efficacy in decoding coherent text from fMRI series across various split settings. Our model achieves a 34.77% BLEU score on fMRI2text, and a 37.04% BLEU when generalized to EEGto-text decoding, thereby surpassing the former baseline. Experimental results indicate the feasibility of decoding consecutive fMRI volumes, and the effectiveness of decoding different cognitive signals using a unified structure.
HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge
Apr 14, 2023Large Language Models (LLMs), such as the LLaMA model, have demonstrated their effectiveness in various general-domain natural language processing (NLP) tasks. Nevertheless, LLMs have not yet performed optimally in biomedical domain tasks due to the need for medical expertise in the responses. In response to this challenge, we propose HuaTuo, a LLaMA-based model that has been supervised-fine-tuned with generated QA (Question-Answer) instances. The experimental results demonstrate that HuaTuo generates responses that possess more reliable medical knowledge. Our proposed HuaTuo model is accessible at https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese.
Global Prompt Cell: A Portable Control Module for Effective Prompt
Apr 12, 2023As a novel approach to tuning pre-trained models, prompt tuning involves freezing the parameters in downstream tasks while inserting trainable embeddings into inputs in the first layer.However,previous methods have mainly focused on the initialization of prompt embeddings. The question of how to train and utilize prompt embeddings in a reasonable way has become aa limiting factor in the effectiveness of prompt tuning. To address this issue, we introduce the Global Prompt Cell (GPC), a portable control module for prompt tuning that selectively preserves prompt information across all encoder layers. Our experimental results demonstrate a 5.8% improvement on SuperGLUE datasets compared to vanilla prompt tuning.
Prompt Combines Paraphrase: Teaching Pre-trained Models to Understand Rare Biomedical Words
Sep 14, 2022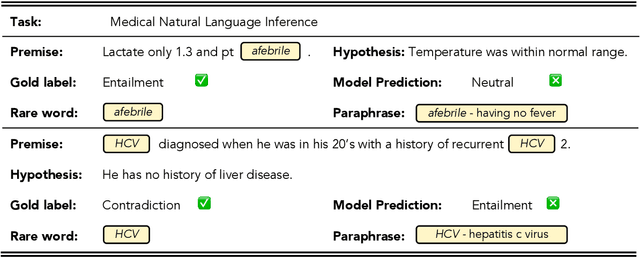
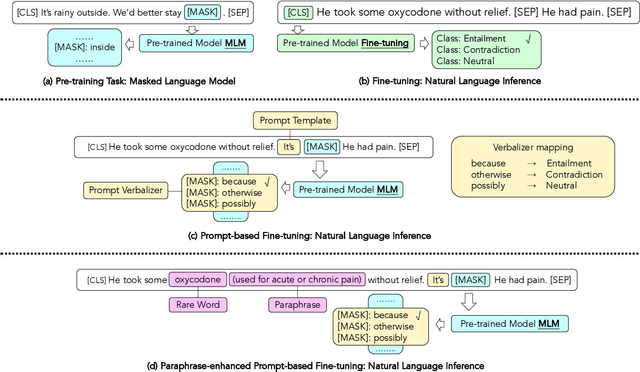
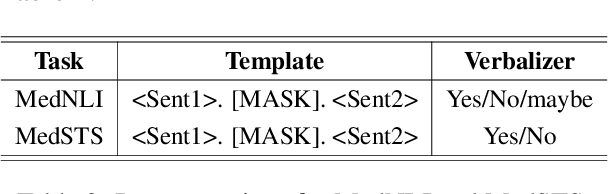
Prompt-based fine-tuning for pre-trained models has proven effective for many natural language processing tasks under few-shot settings in general domain. However, tuning with prompt in biomedical domain has not been investigated thoroughly. Biomedical words are often rare in general domain, but quite ubiquitous in biomedical contexts, which dramatically deteriorates the performance of pre-trained models on downstream biomedical applications even after fine-tuning, especially in low-resource scenarios. We propose a simple yet effective approach to helping models learn rare biomedical words during tuning with prompt. Experimental results show that our method can achieve up to 6% improvement in biomedical natural language inference task without any extra parameters or training steps using few-shot vanilla prompt settings.