 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnPuzzle: A Unified Framework for Pathology Image Analysis
Mar 05, 2025Pathology image analysis plays a pivotal role in medical diagnosis, with deep learning techniques significantly advancing diagnostic accuracy and research. While numerous studies have been conducted to address specific pathological tasks, the lack of standardization in pre-processing methods and model/database architectures complicates fair comparisons across different approaches. This highlights the need for a unified pipeline and comprehensive benchmarks to enable consistent evaluation and accelerate research progress. In this paper, we present UnPuzzle, a novel and unified framework for pathological AI research that covers a broad range of pathology tasks with benchmark results. From high-level to low-level, upstream to downstream tasks, UnPuzzle offers a modular pipeline that encompasses data pre-processing, model composition,taskconfiguration,andexperimentconduction.Specifically, it facilitates efficient benchmarking for both Whole Slide Images (WSIs) and Region of Interest (ROI) tasks. Moreover, the framework supports variouslearningparadigms,includingself-supervisedlearning,multi-task learning,andmulti-modallearning,enablingcomprehensivedevelopment of pathology AI models. Through extensive benchmarking across multiple datasets, we demonstrate the effectiveness of UnPuzzle in streamlining pathology AI research and promoting reproducibility. We envision UnPuzzle as a cornerstone for future advancements in pathology AI, providing a more accessible, transparent, and standardized approach to model evaluation. The UnPuzzle repository is publicly available at https://github.com/Puzzle-AI/UnPuzzle.
Deep Causal Inference for Point-referenced Spatial Data with Continuous Treatments
Dec 05, 2024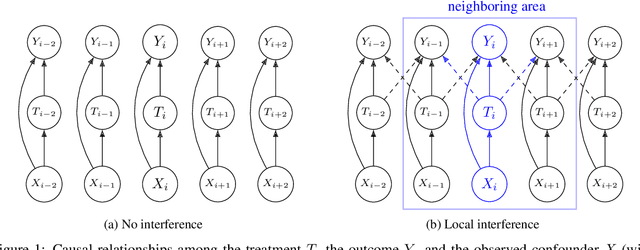


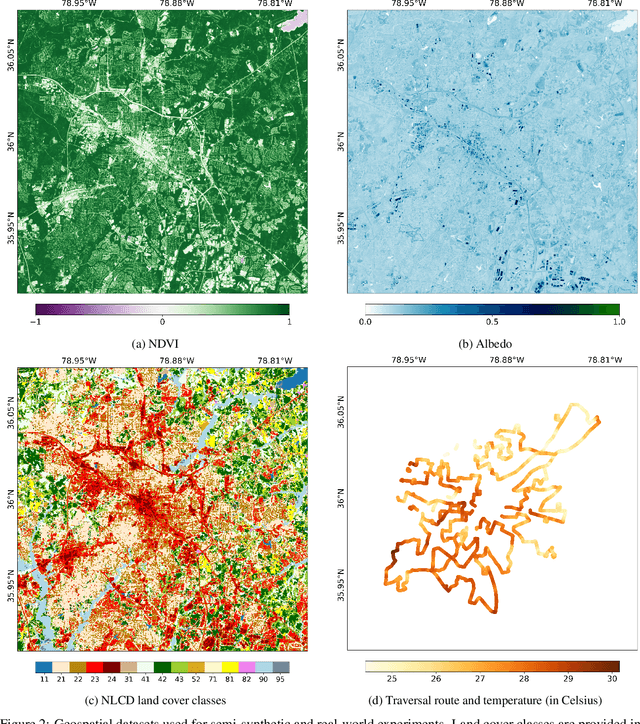
Causal reasoning is often challenging with spatial data, particularly when handling high-dimensional inputs. To address this, we propose a neural network (NN) based framework integrated with an approximate Gaussian process to manage spatial interference and unobserved confounding. Additionally, we adopt a generalized propensity-score-based approach to address partially observed outcomes when estimating causal effects with continuous treatments. We evaluate our framework using synthetic, semi-synthetic, and real-world data inferred from satellite imagery. Our results demonstrate that NN-based models significantly outperform linear spatial regression models in estimating causal effects. Furthermore, in real-world case studies, NN-based models offer more reasonable predictions of causal effects, facilitating decision-making in relevant applications.
Causal Mediation Analysis with Multi-dimensional and Indirectly Observed Mediators
Jun 13, 2023



Causal mediation analysis (CMA) is a powerful method to dissect the total effect of a treatment into direct and mediated effects within the potential outcome framework. This is important in many scientific applications to identify the underlying mechanisms of a treatment effect. However, in many scientific applications the mediator is unobserved, but there may exist related measurements. For example, we may want to identify how changes in brain activity or structure mediate an antidepressant's effect on behavior, but we may only have access to electrophysiological or imaging brain measurements. To date, most CMA methods assume that the mediator is one-dimensional and observable, which oversimplifies such real-world scenarios. To overcome this limitation, we introduce a CMA framework that can handle complex and indirectly observed mediators based on the identifiable variational autoencoder (iVAE) architecture. We prove that the true joint distribution over observed and latent variables is identifiable with the proposed method. Additionally, our framework captures a disentangled representation of the indirectly observed mediator and yields accurate estimation of the direct and mediated effects in synthetic and semi-synthetic experiments, providing evidence of its potential utility in real-world applications.
Domain Adaptation via Rebalanced Sub-domain Alignment
Feb 03, 2023

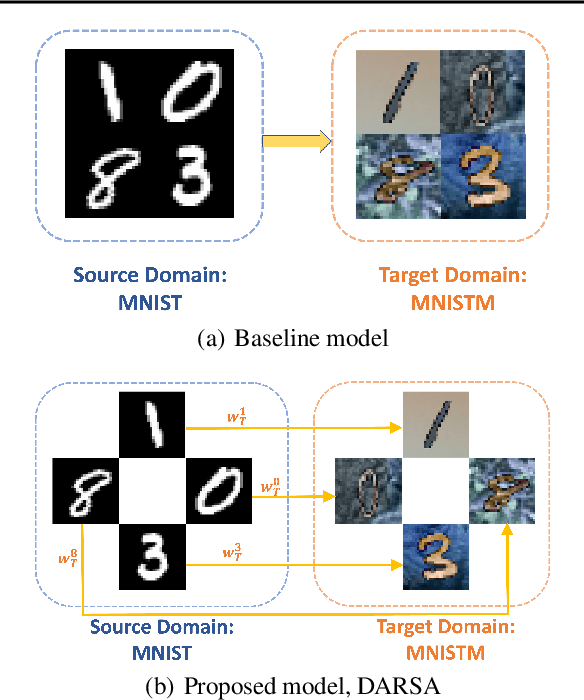

Unsupervised domain adaptation (UDA) is a technique used to transfer knowledge from a labeled source domain to a different but related unlabeled target domain. While many UDA methods have shown success in the past, they often assume that the source and target domains must have identical class label distributions, which can limit their effectiveness in real-world scenarios. To address this limitation, we propose a novel generalization bound that reweights source classification error by aligning source and target sub-domains. We prove that our proposed generalization bound is at least as strong as existing bounds under realistic assumptions, and we empirically show that it is much stronger on real-world data. We then propose an algorithm to minimize this novel generalization bound. We demonstrate by numerical experiments that this approach improves performance in shifted class distribution scenarios compared to state-of-the-art methods.
Estimating Causal Effects using a Multi-task Deep Ensemble
Jan 26, 2023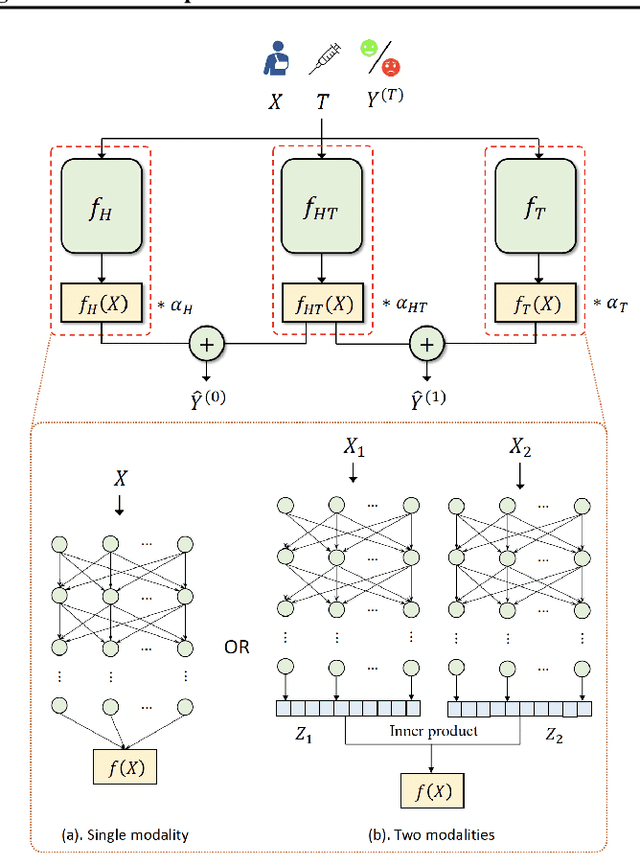



Over the past few decades, a number of methods have been proposed for causal effect estimation, yet few have been demonstrated to be effective in handling data with complex structures, such as images. To fill this gap, we propose a Causal Multi-task Deep Ensemble (CMDE) framework to learn both shared and group-specific information from the study population and prove its equivalence to a multi-task Gaussian process (GP) with coregionalization kernel a priori. Compared to multi-task GP, CMDE efficiently handles high-dimensional and multi-modal covariates and provides pointwise uncertainty estimates of causal effects. We evaluate our method across various types of datasets and tasks and find that CMDE outperforms state-of-the-art methods on a majority of these tasks.
Unsupervised Learning of Monocular Depth and Ego-Motion Using Multiple Masks
Apr 01, 2021

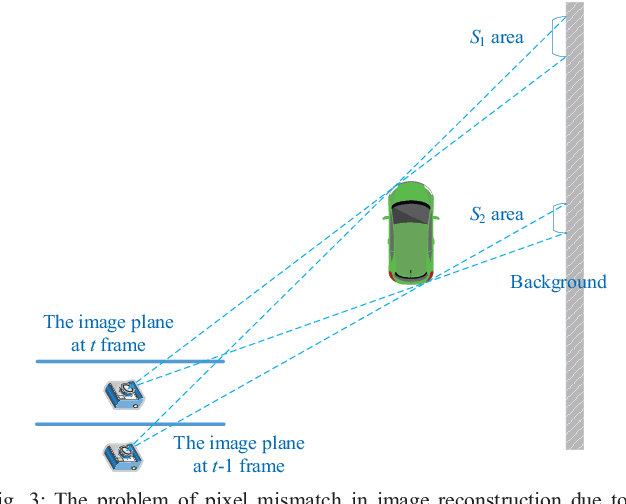
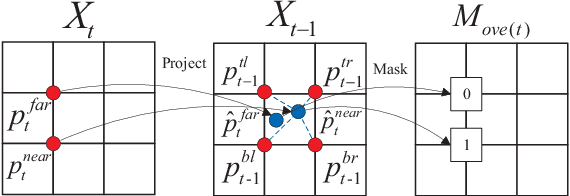
A new unsupervised learning method of depth and ego-motion using multiple masks from monocular video is proposed in this paper. The depth estimation network and the ego-motion estimation network are trained according to the constraints of depth and ego-motion without truth values. The main contribution of our method is to carefully consider the occlusion of the pixels generated when the adjacent frames are projected to each other, and the blank problem generated in the projection target imaging plane. Two fine masks are designed to solve most of the image pixel mismatch caused by the movement of the camera. In addition, some relatively rare circumstances are considered, and repeated masking is proposed. To some extent, the method is to use a geometric relationship to filter the mismatched pixels for training, making unsupervised learning more efficient and accurate. The experiments on KITTI dataset show our method achieves good performance in terms of depth and ego-motion. The generalization capability of our method is demonstrated by training on the low-quality uncalibrated bike video dataset and evaluating on KITTI dataset, and the results are still good.
* Accepted to ICRA 2019
IFR-Net: Iterative Feature Refinement Network for Compressed Sensing MRI
Sep 25, 2019
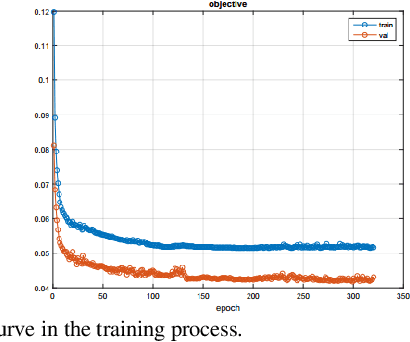

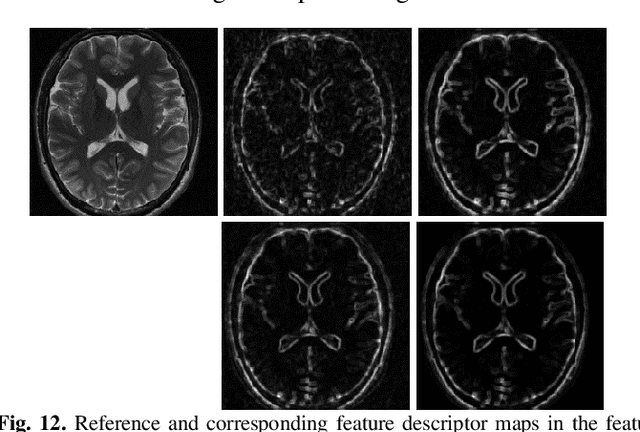
To improve the compressive sensing MRI (CS-MRI) approaches in terms of fine structure loss under high acceleration factors, we have proposed an iterative feature refinement model (IFR-CS), equipped with fixed transforms, to restore the meaningful structures and details. Nevertheless, the proposed IFR-CS still has some limitations, such as the selection of hyper-parameters, a lengthy reconstruction time, and the fixed sparsifying transform. To alleviate these issues, we unroll the iterative feature refinement procedures in IFR-CS to a supervised model-driven network, dubbed IFR-Net. Equipped with training data pairs, both regularization parameter and the utmost feature refinement operator in IFR-CS become trainable. Additionally, inspired by the powerful representation capability of convolutional neural network (CNN), CNN-based inversion blocks are explored in the sparsity-promoting denoising module to generalize the sparsity-enforcing operator. Extensive experiments on both simulated and in vivo MR datasets have shown that the proposed network possesses a strong capability to capture image details and preserve well the structural information with fast reconstruction speed.