 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuyan-TTS: A Trainable Text-to-Speech Model Optimized for Podcast Scenarios with a $50K Budget
Apr 27, 2025Recent advancements in text-to-speech (TTS) models have been driven by the integration of large language models (LLMs), enhancing semantic comprehension and improving speech naturalness. However, existing LLM-based TTS models often lack open-source training code and efficient inference acceleration frameworks, limiting their accessibility and adaptability. Additionally, there is no publicly available TTS model specifically optimized for podcast scenarios, which are in high demand for voice interaction applications. To address these limitations, we introduce Muyan-TTS, an open-source trainable TTS model designed for podcast applications within a $50,000 budget. Our model is pre-trained on over 100,000 hours of podcast audio data, enabling zero-shot TTS synthesis with high-quality voice generation. Furthermore, Muyan-TTS supports speaker adaptation with dozens of minutes of target speech, making it highly customizable for individual voices. In addition to open-sourcing the model, we provide a comprehensive data collection and processing pipeline, a full training procedure, and an optimized inference framework that accelerates LLM-based TTS synthesis. Our code and models are available at https://github.com/MYZY-AI/Muyan-TTS.
Deep Causal Inference for Point-referenced Spatial Data with Continuous Treatments
Dec 05, 2024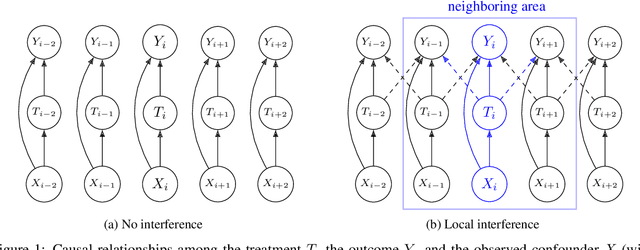


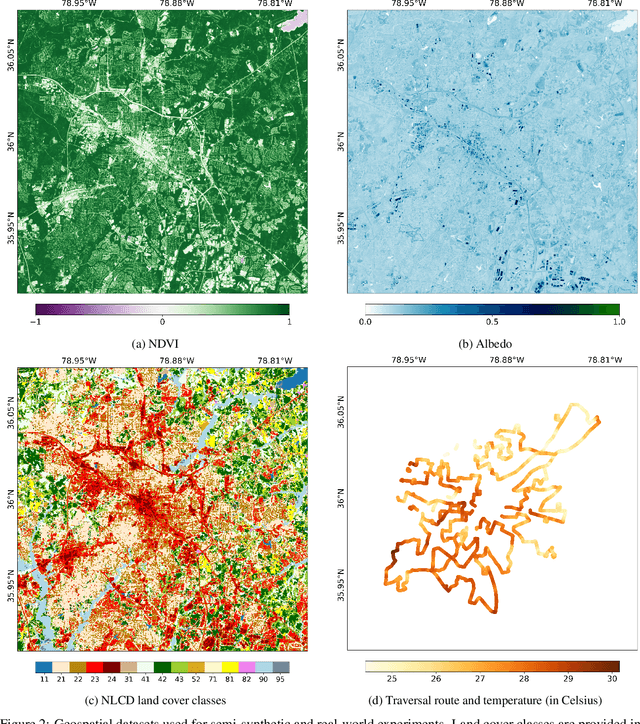
Causal reasoning is often challenging with spatial data, particularly when handling high-dimensional inputs. To address this, we propose a neural network (NN) based framework integrated with an approximate Gaussian process to manage spatial interference and unobserved confounding. Additionally, we adopt a generalized propensity-score-based approach to address partially observed outcomes when estimating causal effects with continuous treatments. We evaluate our framework using synthetic, semi-synthetic, and real-world data inferred from satellite imagery. Our results demonstrate that NN-based models significantly outperform linear spatial regression models in estimating causal effects. Furthermore, in real-world case studies, NN-based models offer more reasonable predictions of causal effects, facilitating decision-making in relevant applications.
pTSE-T: Presentation Target Speaker Extraction using Unaligned Text Cues
Nov 05, 2024



TSE aims to extract the clean speech of the target speaker in an audio mixture, thus eliminating irrelevant background noise and speech. While prior work has explored various auxiliary cues including pre-recorded speech, visual information (e.g., lip motions and gestures), and spatial information, the acquisition and selection of such strong cues are infeasible in many practical scenarios. Unlike all existing work, in this paper, we condition the TSE algorithm on semantic cues extracted from limited and unaligned text content, such as condensed points from a presentation slide. This method is particularly useful in scenarios like meetings, poster sessions, or lecture presentations, where acquiring other cues in real-time is challenging. To this end, we design two different networks. Specifically, our proposed TPE fuses audio features with content-based semantic cues to facilitate time-frequency mask generation to filter out extraneous noise, while another proposal, namely TSR, employs the contrastive learning technique to associate blindly separated speech signals with semantic cues. The experimental results show the efficacy in accurately identifying the target speaker by utilizing semantic cues derived from limited and unaligned text, resulting in SI-SDRi of 12.16 dB, SDRi of 12.66 dB, PESQi of 0.830 and STOIi of 0.150, respectively. Dataset and source code will be publicly available. Project demo page: https://slideTSE.github.io/.
ADEPT-Z: Zero-Shot Automated Circuit Topology Search for Pareto-Optimal Photonic Tensor Cores
Oct 02, 2024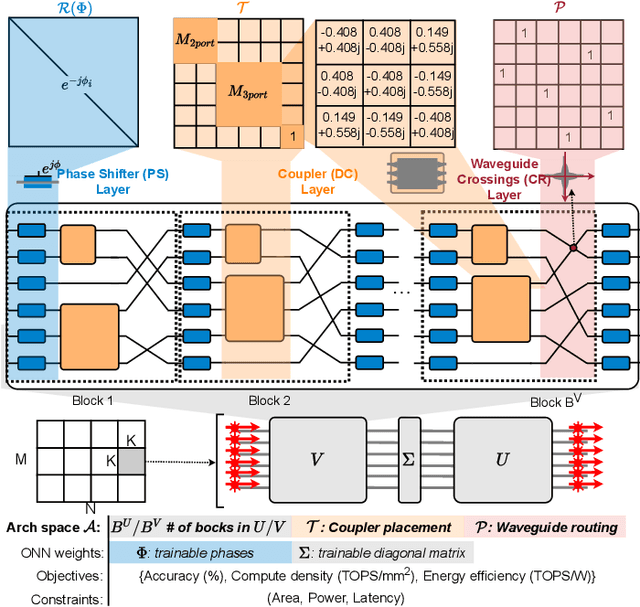

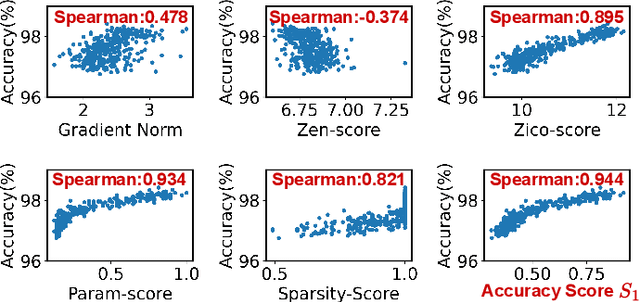

Photonic tensor cores (PTCs) are essential building blocks for optical artificial intelligence (AI) accelerators based on programmable photonic integrated circuits. Most PTC designs today are manually constructed, with low design efficiency and unsatisfying solution quality. This makes it challenging to meet various hardware specifications and keep up with rapidly evolving AI applications. Prior work has explored gradient-based methods to learn a good PTC structure differentiably. However, it suffers from slow training speed and optimization difficulty when handling multiple non-differentiable objectives and constraints. Therefore, in this work, we propose a more flexible and efficient zero-shot multi-objective evolutionary topology search framework ADEPT-Z that explores Pareto-optimal PTC designs with advanced devices in a larger search space. Multiple objectives can be co-optimized while honoring complicated hardware constraints. With only <3 hours of search, we can obtain tens of diverse Pareto-optimal solutions, 100x faster than the prior gradient-based method, outperforming prior manual designs with 2x higher accuracy weighted area-energy efficiency. The code of ADEPT-Z is available at https://github.com/ScopeX-ASU/ADEPT-Z.
Augmenting Ground-Level PM2.5 Prediction via Kriging-Based Pseudo-Label Generation
Jan 16, 2024Fusing abundant satellite data with sparse ground measurements constitutes a major challenge in climate modeling. To address this, we propose a strategy to augment the training dataset by introducing unlabeled satellite images paired with pseudo-labels generated through a spatial interpolation technique known as ordinary kriging, thereby making full use of the available satellite data resources. We show that the proposed data augmentation strategy helps enhance the performance of the state-of-the-art convolutional neural network-random forest (CNN-RF) model by a reasonable amount, resulting in a noteworthy improvement in spatial correlation and a reduction in prediction error.
Causal Mediation Analysis with Multi-dimensional and Indirectly Observed Mediators
Jun 13, 2023



Causal mediation analysis (CMA) is a powerful method to dissect the total effect of a treatment into direct and mediated effects within the potential outcome framework. This is important in many scientific applications to identify the underlying mechanisms of a treatment effect. However, in many scientific applications the mediator is unobserved, but there may exist related measurements. For example, we may want to identify how changes in brain activity or structure mediate an antidepressant's effect on behavior, but we may only have access to electrophysiological or imaging brain measurements. To date, most CMA methods assume that the mediator is one-dimensional and observable, which oversimplifies such real-world scenarios. To overcome this limitation, we introduce a CMA framework that can handle complex and indirectly observed mediators based on the identifiable variational autoencoder (iVAE) architecture. We prove that the true joint distribution over observed and latent variables is identifiable with the proposed method. Additionally, our framework captures a disentangled representation of the indirectly observed mediator and yields accurate estimation of the direct and mediated effects in synthetic and semi-synthetic experiments, providing evidence of its potential utility in real-world applications.
Domain Adaptation via Rebalanced Sub-domain Alignment
Feb 03, 2023

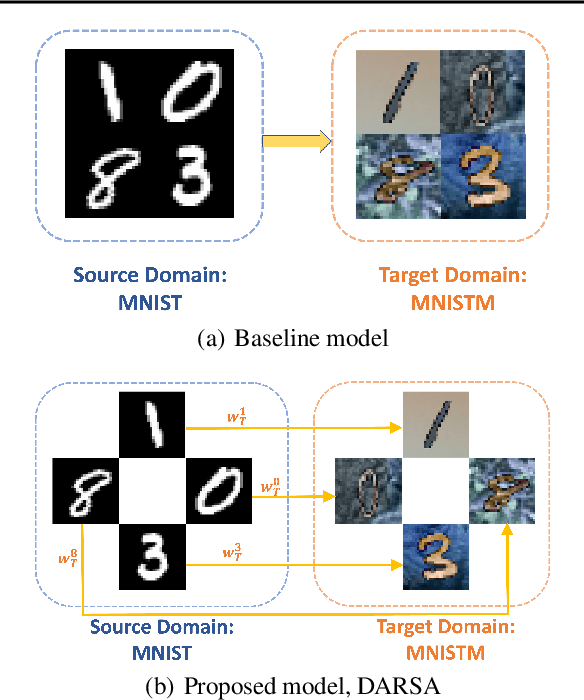

Unsupervised domain adaptation (UDA) is a technique used to transfer knowledge from a labeled source domain to a different but related unlabeled target domain. While many UDA methods have shown success in the past, they often assume that the source and target domains must have identical class label distributions, which can limit their effectiveness in real-world scenarios. To address this limitation, we propose a novel generalization bound that reweights source classification error by aligning source and target sub-domains. We prove that our proposed generalization bound is at least as strong as existing bounds under realistic assumptions, and we empirically show that it is much stronger on real-world data. We then propose an algorithm to minimize this novel generalization bound. We demonstrate by numerical experiments that this approach improves performance in shifted class distribution scenarios compared to state-of-the-art methods.
Estimating Causal Effects using a Multi-task Deep Ensemble
Jan 26, 2023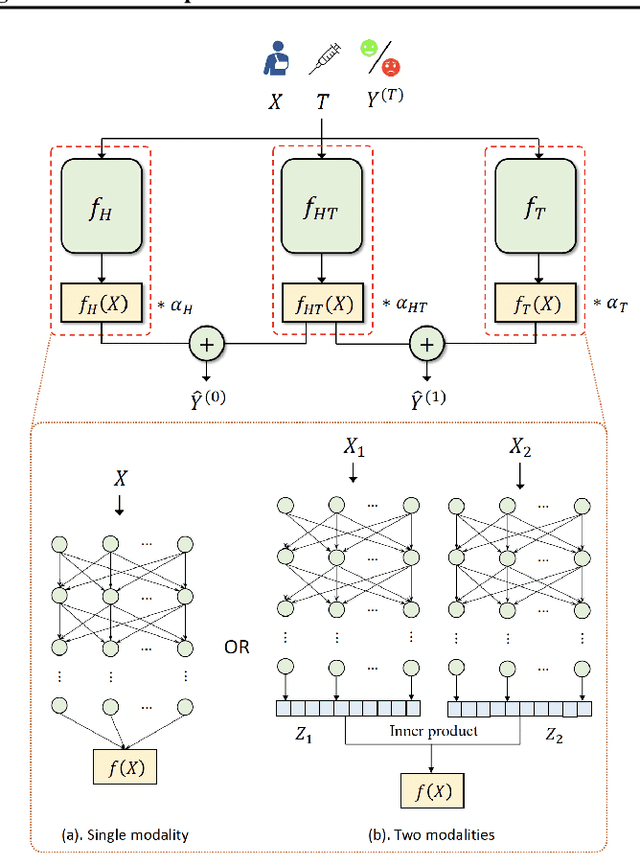



Over the past few decades, a number of methods have been proposed for causal effect estimation, yet few have been demonstrated to be effective in handling data with complex structures, such as images. To fill this gap, we propose a Causal Multi-task Deep Ensemble (CMDE) framework to learn both shared and group-specific information from the study population and prove its equivalence to a multi-task Gaussian process (GP) with coregionalization kernel a priori. Compared to multi-task GP, CMDE efficiently handles high-dimensional and multi-modal covariates and provides pointwise uncertainty estimates of causal effects. We evaluate our method across various types of datasets and tasks and find that CMDE outperforms state-of-the-art methods on a majority of these tasks.
Incorporating Prior Knowledge into Neural Networks through an Implicit Composite Kernel
May 17, 2022

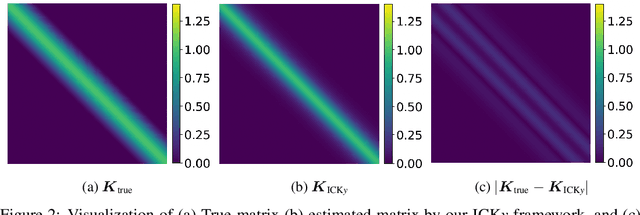
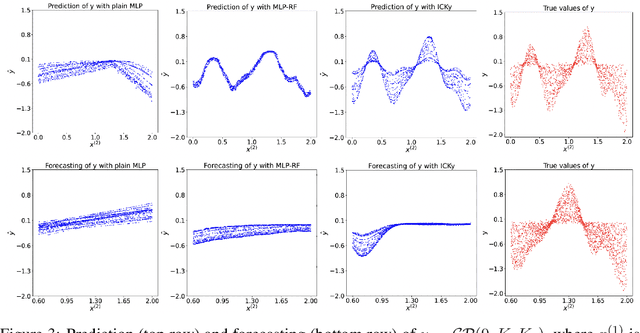
It is challenging to guide neural network (NN) learning with prior knowledge. In contrast, many known properties, such as spatial smoothness or seasonality, are straightforward to model by choosing an appropriate kernel in a Gaussian process (GP). Many deep learning applications could be enhanced by modeling such known properties. For example, convolutional neural networks (CNNs) are frequently used in remote sensing, which is subject to strong seasonal effects. We propose to blend the strengths of deep learning and the clear modeling capabilities of GPs by using a composite kernel that combines a kernel implicitly defined by a neural network with a second kernel function chosen to model known properties (e.g., seasonality). Then, we approximate the resultant GP by combining a deep network and an efficient mapping based on the Nystrom approximation, which we call Implicit Composite Kernel (ICK). ICK is flexible and can be used to include prior information in neural networks in many applications. We demonstrate the strength of our framework by showing its superior performance and flexibility on both synthetic and real-world data sets. The code is available at: https://anonymous.4open.science/r/ICK_NNGP-17C5/.