 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for All: A Non-Linear Transformer can Enable Cross-Domain Generalization for In-Context Reinforcement Learning
May 10, 2026A central challenge in reinforcement learning (RL) is to learn models that generalize beyond the tasks on which they are trained, a goal traditionally pursued through multi-task and meta RL. Recently, transformer architectures have emerged as a promising approach, enabling adaptation to new tasks via in-context learning without explicit parameter updates. From a functional perspective, a transformer can be viewed as a functional operator that maps a context to a task-specific function. It is thus fundamental to understand and design this operator to support stronger generalization in RL. In this work, we address this resulting question of generalization from a kernel-based perspective by establishing a connection between non-linear transformers and kernel-based temporal difference learning. By interpreting the transformer as performing regression in a Reproducing Kernel Hilbert Space (RKHS), we show that value functions from different domains can be represented using a shared set of weights, provided they lie within the same RKHS. Experiments on multiple MetaWorld domains support this interpretation, demonstrating convergence of the temporal-difference objective.
Rethinking Token Prediction: Tree-Structured Diffusion Language Model
Apr 04, 2026Discrete diffusion language models have emerged as a competitive alternative to auto-regressive language models, but training them efficiently under limited parameter and memory budgets remains challenging. Modern architectures are predominantly based on a full-vocabulary token prediction layer, which accounts for a substantial fraction of model parameters (e.g., more than 20% in small scale DiT-style designs) and often dominates peak GPU memory usage. This leads to inefficient use of both parameters and memory under constrained training resources. To address this issue, we revisit the necessity of explicit full-vocabulary prediction, and instead exploit the inherent structure among tokens to build a tree-structured diffusion language model. Specifically, we model the diffusion process with intermediate latent states corresponding to a token's ancestor nodes in a pre-constructed vocabulary tree. This tree-structured factorization exponentially reduces the classification dimensionality, makes the prediction head negligible in size, and enables reallocation of parameters to deepen the attention blocks. Empirically, under the same parameter budget, our method reduces peak GPU memory usage by half while matching the perplexity performance of state-of-the-art discrete diffusion language models.
Learning in Context, Guided by Choice: A Reward-Free Paradigm for Reinforcement Learning with Transformers
Feb 09, 2026In-context reinforcement learning (ICRL) leverages the in-context learning capabilities of transformer models (TMs) to efficiently generalize to unseen sequential decision-making tasks without parameter updates. However, existing ICRL methods rely on explicit reward signals during pretraining, which limits their applicability when rewards are ambiguous, hard to specify, or costly to obtain. To overcome this limitation, we propose a new learning paradigm, In-Context Preference-based Reinforcement Learning (ICPRL), in which both pretraining and deployment rely solely on preference feedback, eliminating the need for reward supervision. We study two variants that differ in the granularity of feedback: Immediate Preference-based RL (I-PRL) with per-step preferences, and Trajectory Preference-based RL (T-PRL) with trajectory-level comparisons. We first show that supervised pretraining, a standard approach in ICRL, remains effective under preference-only context datasets, demonstrating the feasibility of in-context reinforcement learning using only preference signals. To further improve data efficiency, we introduce alternative preference-native frameworks for I-PRL and T-PRL that directly optimize TM policies from preference data without requiring reward signals nor optimal action labels.Experiments on dueling bandits, navigation, and continuous control tasks demonstrate that ICPRL enables strong in-context generalization to unseen tasks, achieving performance comparable to ICRL methods trained with full reward supervision.
In-Context Reinforcement Learning From Suboptimal Historical Data
Jan 27, 2026Transformer models have achieved remarkable empirical successes, largely due to their in-context learning capabilities. Inspired by this, we explore training an autoregressive transformer for in-context reinforcement learning (ICRL). In this setting, we initially train a transformer on an offline dataset consisting of trajectories collected from various RL tasks, and then fix and use this transformer to create an action policy for new RL tasks. Notably, we consider the setting where the offline dataset contains trajectories sampled from suboptimal behavioral policies. In this case, standard autoregressive training corresponds to imitation learning and results in suboptimal performance. To address this, we propose the Decision Importance Transformer(DIT) framework, which emulates the actor-critic algorithm in an in-context manner. In particular, we first train a transformer-based value function that estimates the advantage functions of the behavior policies that collected the suboptimal trajectories. Then we train a transformer-based policy via a weighted maximum likelihood estimation loss, where the weights are constructed based on the trained value function to steer the suboptimal policies to the optimal ones. We conduct extensive experiments to test the performance of DIT on both bandit and Markov Decision Process problems. Our results show that DIT achieves superior performance, particularly when the offline dataset contains suboptimal historical data.
Neuro-Logic Lifelong Learning
Nov 16, 2025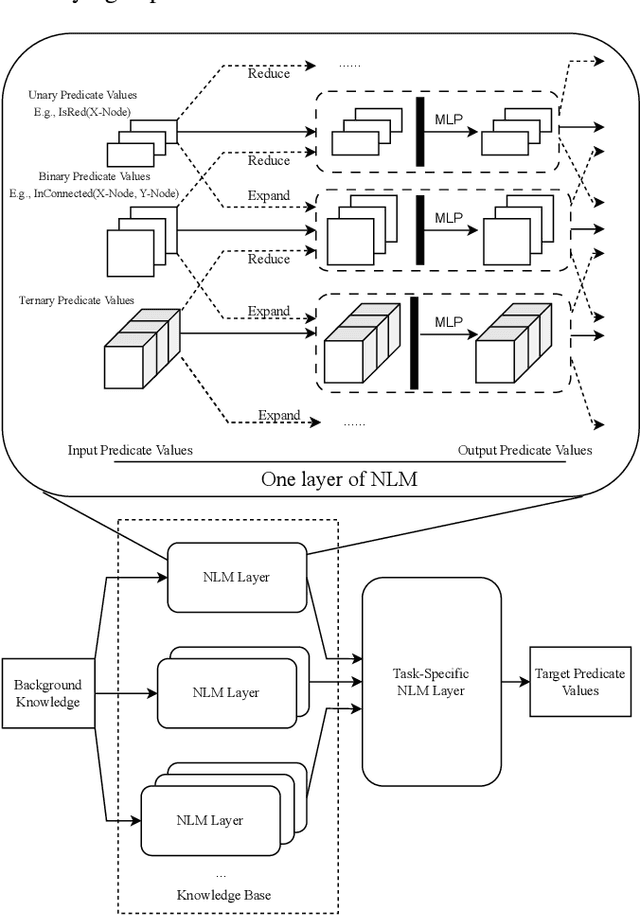
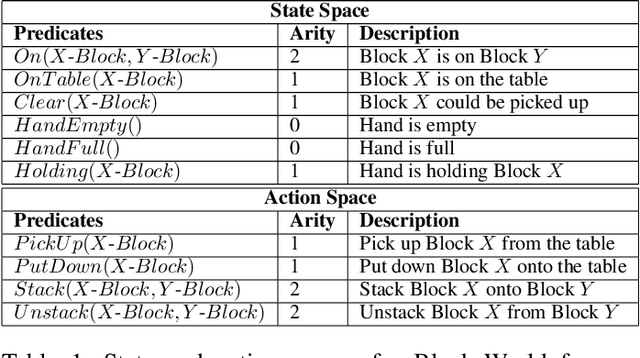
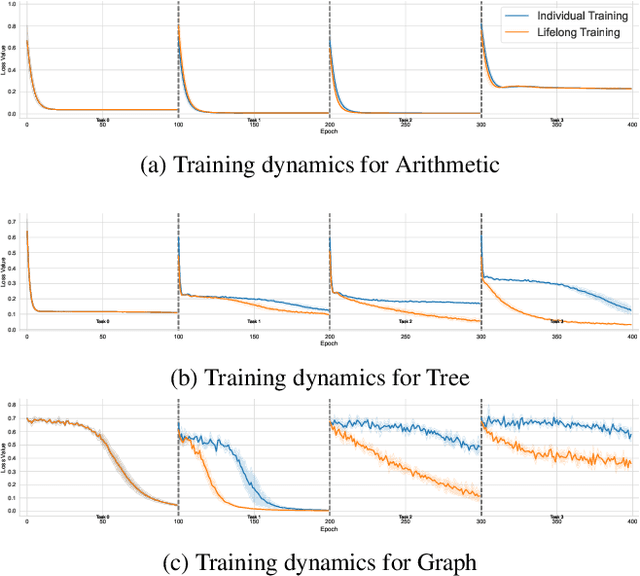
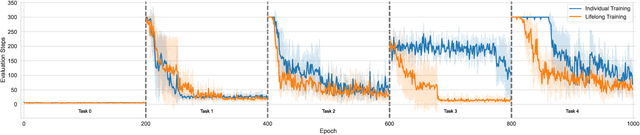
Solving Inductive Logic Programming (ILP) problems with neural networks is a key challenge in Neural-Symbolic Ar- tificial Intelligence (AI). While most research has focused on designing novel network architectures for individual prob- lems, less effort has been devoted to exploring new learning paradigms involving a sequence of problems. In this work, we investigate lifelong learning ILP, which leverages the com- positional and transferable nature of logic rules for efficient learning of new problems. We introduce a compositional framework, demonstrating how logic rules acquired from ear- lier tasks can be efficiently reused in subsequent ones, leading to improved scalability and performance. We formalize our approach and empirically evaluate it on sequences of tasks. Experimental results validate the feasibility and advantages of this paradigm, opening new directions for continual learn- ing in Neural-Symbolic AI.
PASTA: A Unified Framework for Offline Assortment Learning
Oct 02, 2025We study a broad class of assortment optimization problems in an offline and data-driven setting. In such problems, a firm lacks prior knowledge of the underlying choice model, and aims to determine an optimal assortment based on historical customer choice data. The combinatorial nature of assortment optimization often results in insufficient data coverage, posing a significant challenge in designing provably effective solutions. To address this, we introduce a novel Pessimistic Assortment Optimization (PASTA) framework that leverages the principle of pessimism to achieve optimal expected revenue under general choice models. Notably, PASTA requires only that the offline data distribution contains an optimal assortment, rather than providing the full coverage of all feasible assortments. Theoretically, we establish the first finite-sample regret bounds for offline assortment optimization across several widely used choice models, including the multinomial logit and nested logit models. Additionally, we derive a minimax regret lower bound, proving that PASTA is minimax optimal in terms of sample and model complexity. Numerical experiments further demonstrate that our method outperforms existing baseline approaches.
Conditional Average Treatment Effect Estimation Under Hidden Confounders
Jun 14, 2025One of the major challenges in estimating conditional potential outcomes and conditional average treatment effects (CATE) is the presence of hidden confounders. Since testing for hidden confounders cannot be accomplished only with observational data, conditional unconfoundedness is commonly assumed in the literature of CATE estimation. Nevertheless, under this assumption, CATE estimation can be significantly biased due to the effects of unobserved confounders. In this work, we consider the case where in addition to a potentially large observational dataset, a small dataset from a randomized controlled trial (RCT) is available. Notably, we make no assumptions on the existence of any covariate information for the RCT dataset, we only require the outcomes to be observed. We propose a CATE estimation method based on a pseudo-confounder generator and a CATE model that aligns the learned potential outcomes from the observational data with those observed from the RCT. Our method is applicable to many practical scenarios of interest, particularly those where privacy is a concern (e.g., medical applications). Extensive numerical experiments are provided demonstrating the effectiveness of our approach for both synthetic and real-world datasets.
Teleportation With Null Space Gradient Projection for Optimization Acceleration
Feb 17, 2025Optimization techniques have become increasingly critical due to the ever-growing model complexity and data scale. In particular, teleportation has emerged as a promising approach, which accelerates convergence of gradient descent-based methods by navigating within the loss invariant level set to identify parameters with advantageous geometric properties. Existing teleportation algorithms have primarily demonstrated their effectiveness in optimizing Multi-Layer Perceptrons (MLPs), but their extension to more advanced architectures, such as Convolutional Neural Networks (CNNs) and Transformers, remains challenging. Moreover, they often impose significant computational demands, limiting their applicability to complex architectures. To this end, we introduce an algorithm that projects the gradient of the teleportation objective function onto the input null space, effectively preserving the teleportation within the loss invariant level set and reducing computational cost. Our approach is readily generalizable from MLPs to CNNs, transformers, and potentially other advanced architectures. We validate the effectiveness of our algorithm across various benchmark datasets and optimizers, demonstrating its broad applicability.
S2TX: Cross-Attention Multi-Scale State-Space Transformer for Time Series Forecasting
Feb 17, 2025Time series forecasting has recently achieved significant progress with multi-scale models to address the heterogeneity between long and short range patterns. Despite their state-of-the-art performance, we identify two potential areas for improvement. First, the variates of the multivariate time series are processed independently. Moreover, the multi-scale (long and short range) representations are learned separately by two independent models without communication. In light of these concerns, we propose State Space Transformer with cross-attention (S2TX). S2TX employs a cross-attention mechanism to integrate a Mamba model for extracting long-range cross-variate context and a Transformer model with local window attention to capture short-range representations. By cross-attending to the global context, the Transformer model further facilitates variate-level interactions as well as local/global communications. Comprehensive experiments on seven classic long-short range time-series forecasting benchmark datasets demonstrate that S2TX can achieve highly robust SOTA results while maintaining a low memory footprint.
Score-Based Metropolis-Hastings Algorithms
Dec 31, 2024



In this paper, we introduce a new approach for integrating score-based models with the Metropolis-Hastings algorithm. While traditional score-based diffusion models excel in accurately learning the score function from data points, they lack an energy function, making the Metropolis-Hastings adjustment step inaccessible. Consequently, the unadjusted Langevin algorithm is often used for sampling using estimated score functions. The lack of an energy function then prevents the application of the Metropolis-adjusted Langevin algorithm and other Metropolis-Hastings methods, limiting the wealth of other algorithms developed that use acceptance functions. We address this limitation by introducing a new loss function based on the \emph{detailed balance condition}, allowing the estimation of the Metropolis-Hastings acceptance probabilities given a learned score function. We demonstrate the effectiveness of the proposed method for various scenarios, including sampling from heavy-tail distributions.