 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Selection for Initiating Human-Centric Experimental Design
Oct 26, 2024



In human-centric tasks such as healthcare and education, the heterogeneity among patients and students necessitates personalized treatments and instructional interventions. While reinforcement learning (RL) has been utilized in those tasks, off-policy selection (OPS) is pivotal to close the loop by offline evaluating and selecting policies without online interactions, yet current OPS methods often overlook the heterogeneity among participants. Our work is centered on resolving a pivotal challenge in human-centric systems (HCSs): how to select a policy to deploy when a new participant joining the cohort, without having access to any prior offline data collected over the participant? We introduce First-Glance Off-Policy Selection (FPS), a novel approach that systematically addresses participant heterogeneity through sub-group segmentation and tailored OPS criteria to each sub-group. By grouping individuals with similar traits, FPS facilitates personalized policy selection aligned with unique characteristics of each participant or group of participants. FPS is evaluated via two important but challenging applications, intelligent tutoring systems and a healthcare application for sepsis treatment and intervention. FPS presents significant advancement in enhancing learning outcomes of students and in-hospital care outcomes.
ε-Neural Thompson Sampling of Deep Brain Stimulation for Parkinson Disease Treatment
Mar 11, 2024



Deep Brain Stimulation (DBS) stands as an effective intervention for alleviating the motor symptoms of Parkinson's disease (PD). Traditional commercial DBS devices are only able to deliver fixed-frequency periodic pulses to the basal ganglia (BG) regions of the brain, i.e., continuous DBS (cDBS). However, they in general suffer from energy inefficiency and side effects, such as speech impairment. Recent research has focused on adaptive DBS (aDBS) to resolve the limitations of cDBS. Specifically, reinforcement learning (RL) based approaches have been developed to adapt the frequencies of the stimuli in order to achieve both energy efficiency and treatment efficacy. However, RL approaches in general require significant amount of training data and computational resources, making it intractable to integrate RL policies into real-time embedded systems as needed in aDBS. In contrast, contextual multi-armed bandits (CMAB) in general lead to better sample efficiency compared to RL. In this study, we propose a CMAB solution for aDBS. Specifically, we define the context as the signals capturing irregular neuronal firing activities in the BG regions (i.e., beta-band power spectral density), while each arm signifies the (discretized) pulse frequency of the stimulation. Moreover, an {\epsilon}-exploring strategy is introduced on top of the classic Thompson sampling method, leading to an algorithm called {\epsilon}-Neural Thompson sampling ({\epsilon}-NeuralTS), such that the learned CMAB policy can better balance exploration and exploitation of the BG environment. The {\epsilon}-NeuralTS algorithm is evaluated using a computation BG model that captures the neuronal activities in PD patients' brains. The results show that our method outperforms both existing cDBS methods and CMAB baselines.
Off-Policy Evaluation for Human Feedback
Oct 14, 2023Off-policy evaluation (OPE) is important for closing the gap between offline training and evaluation of reinforcement learning (RL), by estimating performance and/or rank of target (evaluation) policies using offline trajectories only. It can improve the safety and efficiency of data collection and policy testing procedures in situations where online deployments are expensive, such as healthcare. However, existing OPE methods fall short in estimating human feedback (HF) signals, as HF may be conditioned over multiple underlying factors and is only sparsely available; as opposed to the agent-defined environmental rewards (used in policy optimization), which are usually determined over parametric functions or distributions. Consequently, the nature of HF signals makes extrapolating accurate OPE estimations to be challenging. To resolve this, we introduce an OPE for HF (OPEHF) framework that revives existing OPE methods in order to accurately evaluate the HF signals. Specifically, we develop an immediate human reward (IHR) reconstruction approach, regularized by environmental knowledge distilled in a latent space that captures the underlying dynamics of state transitions as well as issuing HF signals. Our approach has been tested over two real-world experiments, adaptive in-vivo neurostimulation and intelligent tutoring, as well as in a simulation environment (visual Q&A). Results show that our approach significantly improves the performance toward estimating HF signals accurately, compared to directly applying (variants of) existing OPE methods.
Robust Reinforcement Learning through Efficient Adversarial Herding
Jun 12, 2023
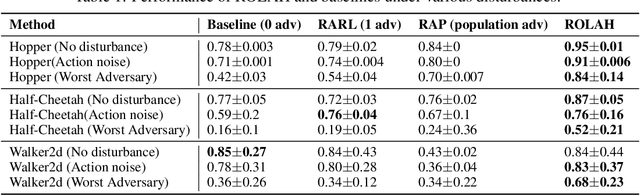
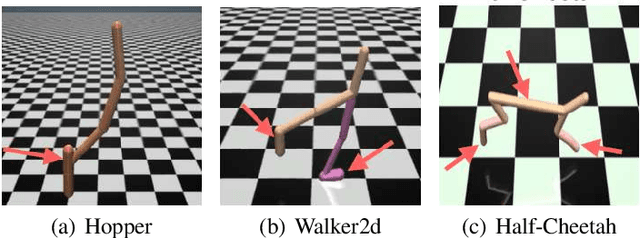
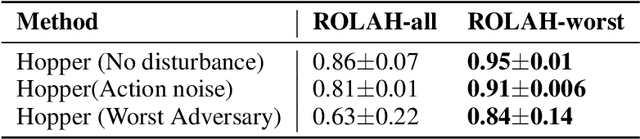
Although reinforcement learning (RL) is considered the gold standard for policy design, it may not always provide a robust solution in various scenarios. This can result in severe performance degradation when the environment is exposed to potential disturbances. Adversarial training using a two-player max-min game has been proven effective in enhancing the robustness of RL agents. In this work, we extend the two-player game by introducing an adversarial herd, which involves a group of adversaries, in order to address ($\textit{i}$) the difficulty of the inner optimization problem, and ($\textit{ii}$) the potential over pessimism caused by the selection of a candidate adversary set that may include unlikely scenarios. We first prove that adversarial herds can efficiently approximate the inner optimization problem. Then we address the second issue by replacing the worst-case performance in the inner optimization with the average performance over the worst-$k$ adversaries. We evaluate the proposed method on multiple MuJoCo environments. Experimental results demonstrate that our approach consistently generates more robust policies.
Offline Learning of Closed-Loop Deep Brain Stimulation Controllers for Parkinson Disease Treatment
Feb 09, 2023



Deep brain stimulation (DBS) has shown great promise toward treating motor symptoms caused by Parkinson's disease (PD), by delivering electrical pulses to the Basal Ganglia (BG) region of the brain. However, DBS devices approved by the U.S. Food and Drug Administration (FDA) can only deliver continuous DBS (cDBS) stimuli at a fixed amplitude; this energy inefficient operation reduces battery lifetime of the device, cannot adapt treatment dynamically for activity, and may cause significant side-effects (e.g., gait impairment). In this work, we introduce an offline reinforcement learning (RL) framework, allowing the use of past clinical data to train an RL policy to adjust the stimulation amplitude in real time, with the goal of reducing energy use while maintaining the same level of treatment (i.e., control) efficacy as cDBS. Moreover, clinical protocols require the safety and performance of such RL controllers to be demonstrated ahead of deployments in patients. Thus, we also introduce an offline policy evaluation (OPE) method to estimate the performance of RL policies using historical data, before deploying them on patients. We evaluated our framework on four PD patients equipped with the RC+S DBS system, employing the RL controllers during monthly clinical visits, with the overall control efficacy evaluated by severity of symptoms (i.e., bradykinesia and tremor), changes in PD biomakers (i.e., local field potentials), and patient ratings. The results from clinical experiments show that our RL-based controller maintains the same level of control efficacy as cDBS, but with significantly reduced stimulation energy. Further, the OPE method is shown effective in accurately estimating and ranking the expected returns of RL controllers.
Variational Latent Branching Model for Off-Policy Evaluation
Feb 03, 2023



Model-based methods have recently shown great potential for off-policy evaluation (OPE); offline trajectories induced by behavioral policies are fitted to transitions of Markov decision processes (MDPs), which are used to rollout simulated trajectories and estimate the performance of policies. Model-based OPE methods face two key challenges. First, as offline trajectories are usually fixed, they tend to cover limited state and action space. Second, the performance of model-based methods can be sensitive to the initialization of their parameters. In this work, we propose the variational latent branching model (VLBM) to learn the transition function of MDPs by formulating the environmental dynamics as a compact latent space, from which the next states and rewards are then sampled. Specifically, VLBM leverages and extends the variational inference framework with the recurrent state alignment (RSA), which is designed to capture as much information underlying the limited training data, by smoothing out the information flow between the variational (encoding) and generative (decoding) part of VLBM. Moreover, we also introduce the branching architecture to improve the model's robustness against randomly initialized model weights. The effectiveness of the VLBM is evaluated on the deep OPE (DOPE) benchmark, from which the training trajectories are designed to result in varied coverage of the state-action space. We show that the VLBM outperforms existing state-of-the-art OPE methods in general.
Imputation-Free Learning from Incomplete Observations
Jul 05, 2021

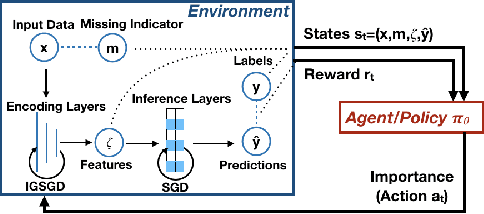
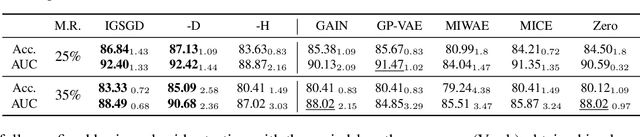
Although recent works have developed methods that can generate estimations (or imputations) of the missing entries in a dataset to facilitate downstream analysis, most depend on assumptions that may not align with real-world applications and could suffer from poor performance in subsequent tasks. This is particularly true if the data have large missingness rates or a small population. More importantly, the imputation error could be propagated into the prediction step that follows, causing the gradients used to train the prediction models to be biased. Consequently, in this work, we introduce the importance guided stochastic gradient descent (IGSGD) method to train multilayer perceptrons (MLPs) and long short-term memories (LSTMs) to directly perform inference from inputs containing missing values without imputation. Specifically, we employ reinforcement learning (RL) to adjust the gradients used to train the models via back-propagation. This not only reduces bias but allows the model to exploit the underlying information behind missingness patterns. We test the proposed approach on real-world time-series (i.e., MIMIC-III), tabular data obtained from an eye clinic, and a standard dataset (i.e., MNIST), where our imputation-free predictions outperform the traditional two-step imputation-based predictions using state-of-the-art imputation methods.
Learning-Based Vulnerability Analysis of Cyber-Physical Systems
Mar 10, 2021

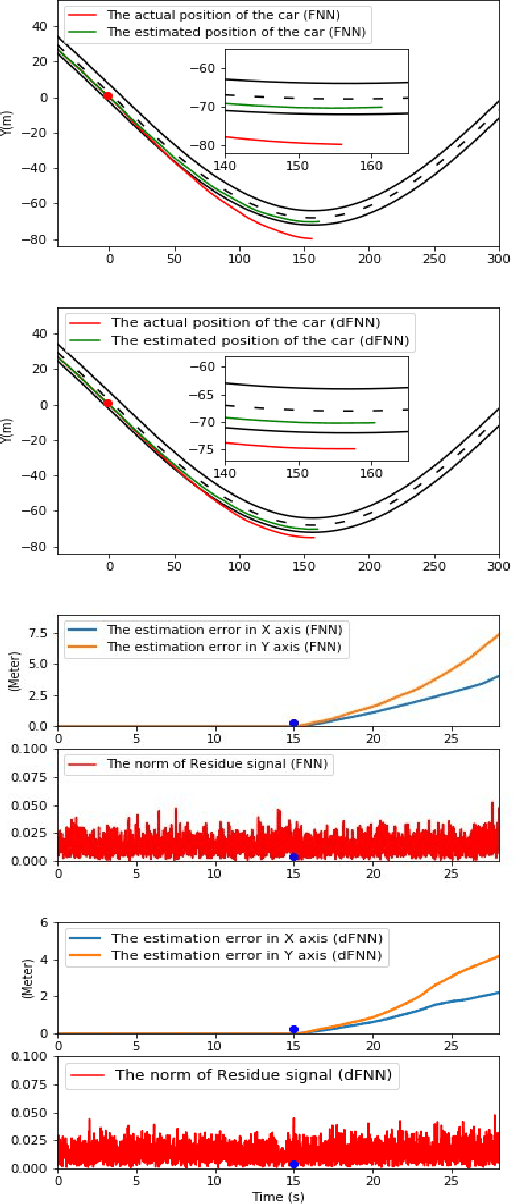
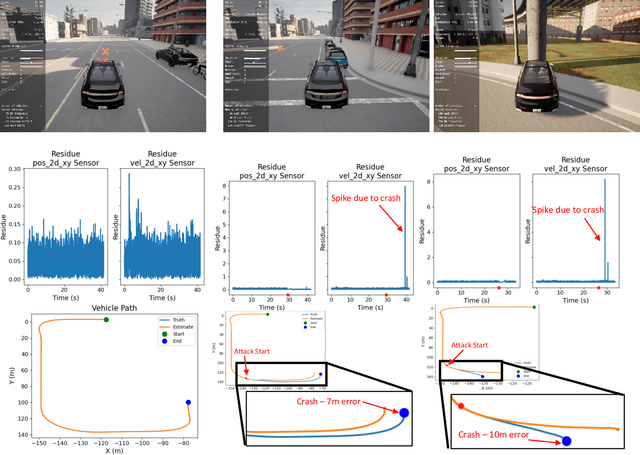
This work focuses on the use of deep learning for vulnerability analysis of cyber-physical systems (CPS). Specifically, we consider a control architecture widely used in CPS (e.g., robotics), where the low-level control is based on e.g., the extended Kalman filter (EKF) and an anomaly detector. To facilitate analyzing the impact potential sensing attacks could have, our objective is to develop learning-enabled attack generators capable of designing stealthy attacks that maximally degrade system operation. We show how such problem can be cast within a learning-based grey-box framework where parts of the runtime information are known to the attacker, and introduce two models based on feed-forward neural networks (FNN); both models are trained offline, using a cost function that combines the attack effects on the estimation error and the residual signal used for anomaly detection, so that the trained models are capable of recursively generating such effective sensor attacks in real-time. The effectiveness of the proposed methods is illustrated on several case studies.
Deep Learning for Stable Monotone Dynamical Systems
Jun 11, 2020
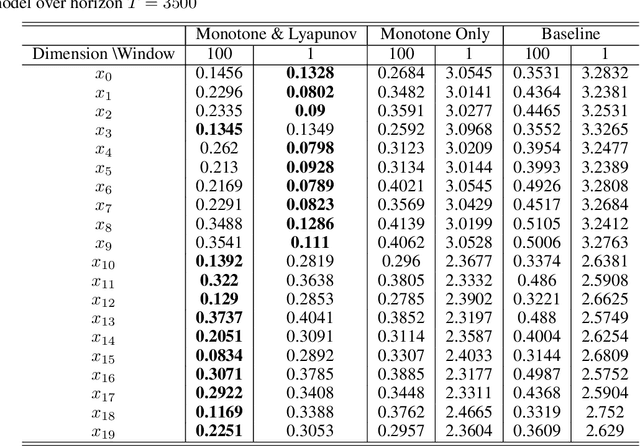

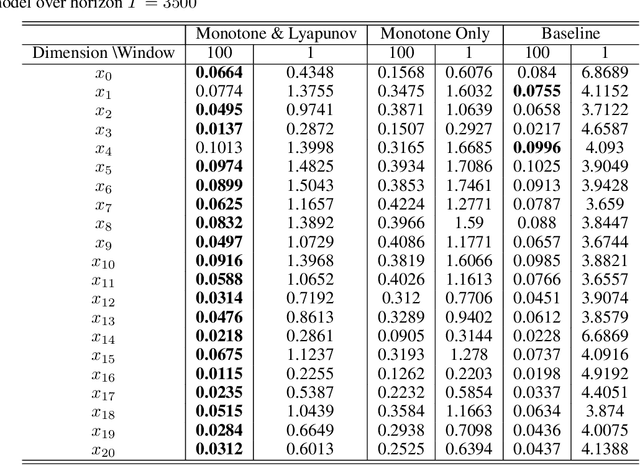
Monotone systems, originating from real-world (e.g., biological or chemical) applications, are a class of dynamical systems that preserves a partial order of system states over time. In this work, we introduce a feedforward neural networks (FNNs)-based method to learn the dynamics of unknown stable nonlinear monotone systems. We propose the use of nonnegative neural networks and batch normalization, which in general enables the FNNs to capture the monotonicity conditions without reducing the expressiveness. To concurrently ensure stability during training, we adopt an alternating learning method to simultaneously learn the system dynamics and corresponding Lyapunov function, while exploiting monotonicity of the system.~The combination of the monotonicity and stability constraints ensures that the learned dynamics preserves both properties, while significantly reducing learning errors. Finally, our techniques are evaluated on two complex biological and chemical systems.