 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Selection for Initiating Human-Centric Experimental Design
Oct 26, 2024



In human-centric tasks such as healthcare and education, the heterogeneity among patients and students necessitates personalized treatments and instructional interventions. While reinforcement learning (RL) has been utilized in those tasks, off-policy selection (OPS) is pivotal to close the loop by offline evaluating and selecting policies without online interactions, yet current OPS methods often overlook the heterogeneity among participants. Our work is centered on resolving a pivotal challenge in human-centric systems (HCSs): how to select a policy to deploy when a new participant joining the cohort, without having access to any prior offline data collected over the participant? We introduce First-Glance Off-Policy Selection (FPS), a novel approach that systematically addresses participant heterogeneity through sub-group segmentation and tailored OPS criteria to each sub-group. By grouping individuals with similar traits, FPS facilitates personalized policy selection aligned with unique characteristics of each participant or group of participants. FPS is evaluated via two important but challenging applications, intelligent tutoring systems and a healthcare application for sepsis treatment and intervention. FPS presents significant advancement in enhancing learning outcomes of students and in-hospital care outcomes.
HOPE: Human-Centric Off-Policy Evaluation for E-Learning and Healthcare
Feb 18, 2023Reinforcement learning (RL) has been extensively researched for enhancing human-environment interactions in various human-centric tasks, including e-learning and healthcare. Since deploying and evaluating policies online are high-stakes in such tasks, off-policy evaluation (OPE) is crucial for inducing effective policies. In human-centric environments, however, OPE is challenging because the underlying state is often unobservable, while only aggregate rewards can be observed (students' test scores or whether a patient is released from the hospital eventually). In this work, we propose a human-centric OPE (HOPE) to handle partial observability and aggregated rewards in such environments. Specifically, we reconstruct immediate rewards from the aggregated rewards considering partial observability to estimate expected total returns. We provide a theoretical bound for the proposed method, and we have conducted extensive experiments in real-world human-centric tasks, including sepsis treatments and an intelligent tutoring system. Our approach reliably predicts the returns of different policies and outperforms state-of-the-art benchmarks using both standard validation methods and human-centric significance tests.
InferNet for Delayed Reinforcement Tasks: Addressing the Temporal Credit Assignment Problem
May 02, 2021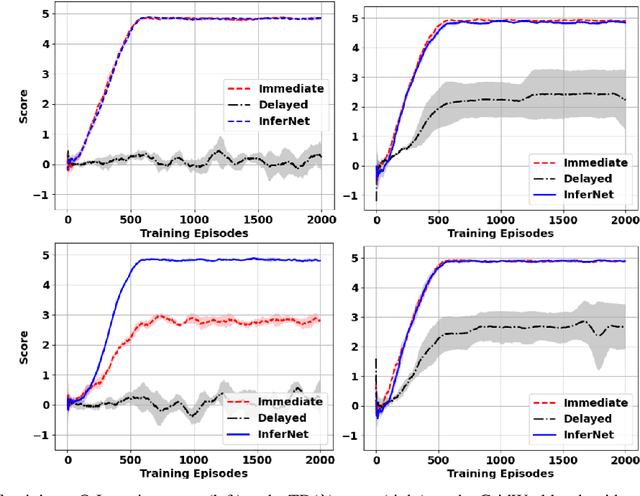



The temporal Credit Assignment Problem (CAP) is a well-known and challenging task in AI. While Reinforcement Learning (RL), especially Deep RL, works well when immediate rewards are available, it can fail when only delayed rewards are available or when the reward function is noisy. In this work, we propose delegating the CAP to a Neural Network-based algorithm named InferNet that explicitly learns to infer the immediate rewards from the delayed rewards. The effectiveness of InferNet was evaluated on two online RL tasks: a simple GridWorld and 40 Atari games; and two offline RL tasks: GridWorld and a real-life Sepsis treatment task. For all tasks, the effectiveness of using the InferNet inferred rewards is compared against the immediate and the delayed rewards with two settings: with noisy rewards and without noise. Overall, our results show that the effectiveness of InferNet is robust against noisy reward functions and is an effective add-on mechanism for solving temporal CAP in a wide range of RL tasks, from classic RL simulation environments to a real-world RL problem and for both online and offline learning.